Озеро, хранилище и витрина данных
Рассмотрим три типа облачных хранилищ данных, их различия и области применения.

Озеро данных
Озеро данных (data lake) — это большой репозиторий необработанных исходных данных, как неструктурированных, так и частично структурированных. Данные собираются из различных источников и просто хранятся. Они не модифицируются под определенную цель и не преобразуются в какой-либо формат. Для анализа этих данных требуется длительная предварительная подготовка, очистка и форматирование для придания им однородности. Озера данных — отличные ресурсы для городских администраций и прочих организаций, которые хранят информацию, связанную с перебоями в работе инфраструктуры, дорожным движением, преступностью или демографией. Данные можно использовать в дальнейшем для внесения изменений в бюджет или пересмотра ресурсов, выделенных коммунальным или экстренным службам.
Хранилище данных
Хранилище данных (data warehouse) представляет собой данные, агрегированные из разных источников в единый центральный репозиторий, который унифицирует их по качеству и формату. Специалисты по работе с данными могут использовать данные из хранилища в таких сферах, как data mining, искусственный интеллект (ИИ), машинное обучение и, конечно, в бизнес-аналитике. Хранилища данных можно использовать в больших городах для сбора информации об электронных транзакциях, поступающей от различных департаментов, включая данные о штрафах за превышение скорости, уплате акцизов и т. д. Хранилища также могут использовать разработчики для сбора терабайтов данных, генерируемых автомобильными датчиками. Это поможет им принимать правильные решения при разработке технологий для автономного вождения.
Витрина данных
Витрина данных (data mart) — это хранилище данных, предназначенное для определенного круга пользователей в компании или ее подразделении. Витрина данных может использоваться отделом маркетинга производственной компании для определения целевой аудитории при разработке маркетинговых планов. Также производственный отдел может применять ее для анализа производительности и количества ошибок, чтобы создать условия для непрерывного совершенствования процессов. Наборы данных в витрине данных часто используются в режиме реального времени для аналитики и получения практических результатов.
Озеро, хранилище и витрина данных: ключевые различия
Все упомянутые репозитории используются для хранения данных, но между ними есть существенные различия. Например, хранилище и озеро данных — крупные репозитории, однако озеро обычно более рентабельно с точки зрения затрат на внедрение и обслуживание, поскольку в нем по большей части хранятся неструктурированные данные.
За последние несколько лет архитектура озер данных эволюционировала, и теперь способна поддерживать бо́льшие объемы данных и облачные вычисления. Большие объемы данных поступают от разных источников в централизованный репозиторий.
Хранилище данных можно организовать одним из трех способов:
Витрина данных содержит небольшой по сравнению с хранилищем и озером объем данных, которые разбиты на категории для применения конкретной группой людей или подразделением компании. Витрина данных может быть представлена в виде различных схем (звезды, снежинки или свода), которые определяются логической структурой данных. Формат свода данных (data vault) является самым гибким, универсальным и масштабируемым.
Существует три типа витрин данных:
IBM предлагает различные решения для облачного хранения и интеллектуального анализа данных.
Нужно ли нам озеро данных? А что делать с хранилищем данных?
Это статья перевод моей статьи на medium — Getting Started with Data Lake, которая оказалась довольно популярной, наверное из-за своей простоты. Поэтому я решил написать ее на русском языке и немного дополнить, чтобы простому человеку, который не является специалистом по работе с данными стало понятно, что такое хранилище данных (DW), а что такое озеро данных (Data Lake), и как они вместе уживаются.
Почему я захотел написать про озеро данных? Я работаю с данными и аналитикой больше 10 лет, и сейчас я точно работаю с большими данными в Amazon Alexa AI в Кембридже, который в Бостоне, хотя сам живу в Виктории на острове Ванкувер и часто бываю и в Бостоне, и в Сиэтле, и в Ванкувере, а иногда даже и в Москве выступаю на конференциях. Так же время от времени я пишу, но пишу в основном на английском, и написал уже несколько книг, так же у меня есть потребность делиться трендами аналитики из Северной Америке, и я иногда пишу в телеграмм.
Я всегда работал с хранилищами данных, и с 2015 года стал плотно работать с Amazon Web Services, да и вообще переключился на облачную аналитику (AWS, Azure, GCP). Я наблюдал эволюцию решений для аналитики с 2007 года и сам даже поработал в вендоре хранилищ данных Терадата и внедрял ее в Сбербанке, тогда-то и появилась Big Data с Hadoop. Все стали говорить, что прошла эра хранилищ и теперь все на Hadoop, а потом уже стали говорить про Data Lake, опять же, что теперь уж точно хранилищу данных пришел конец. Но к счастью (может для кого и к несчастью, кто зарабатывал много денег на настройке Hadoop), хранилище данных не ушло.
В этой статье мы и рассмотрим, что такое озеро данных. Статья рассчитана на людей, у которых мало опыта с хранилищами данными или вовсе нет.

На картинке озеро Блед, это одно из моих любимых озер, хотя я там был всего один раз, но запомнил его на всю жизнь. Но мы поговорим о другом типе озера — озеро данных. Возможно многие из вас уже не раз слышали про это этот термин, но еще одно определение никому не повредит.
Прежде всего вот самые популярные определения Озера Данных:
«файловое хранилище всех типов сырых данных, которые доступны для анализа кем-угодно в организации» — Мартин Фовлер.
«Если вы думаете, что витрина данных это бутылка воды — очищенной, запакованной и расфасованной для удобного употребления, то озеро данных это у нас огромный резервуар с водой в ее естественном виде. Пользователи, могу набирать воды для себя, нырять на глубину, исследовать» — Джеймс Диксон.
Теперь мы точно знаем, что озеро данных это про аналитику, оно позволяет нам хранить большие объемы данных в их первоначальной форме и у нас есть необходимый и удобный доступ к данным.
Я часто люблю упрощать вещи, если я могу рассказать сложный термин простыми словами, значит для себя я понял, как это работает и для чего это нужно. Как то, я ковырялся в iPhone в фотогалерее, и меня осенило, так это же настоящее озеро данных, я даже сделал слайд для конференций:
Все очень просто. Мы делаем фотографию на телефон, фотография сохраняется на телефон и может быть сохранено в iCloud (файловое хранилище в облаке). Также телефон собирает мета-данные фотографии: что изображено, гео метка, время. Как результат, мы может использовать удобный интерфейс iPhone, чтобы найти нашу фотографию и при этому мы даже видим показатели, например, когда я ищу фотографии со словом огонь (fire), то я нахожу 3 фотографии с изображение костра. Для меня это прям как Business Intelligence инструмент, который работает очень быстро и четко.
И конечно, нам нельзя забывать про безопасность (авторизацию и аутентификацию), иначе наши данных, могут легко попасть в открытый доступ. Очень много новостей, про крупные корпорации и стартапы, у которых данные попали в открытый доступ из-за халатности разработчиков и не соблюдения простых правил.
Даже такая простая картинка, помогает нам представить, что такое озеро данных, его отличия от традиционного хранилища данных и его основные элементы:
С другой стороны, вендор Snowflake заявляет, что вам больше не нужно думать про озеро данных, так как их платформа данных (до 2020 это было хранилище данных), позволяет вам совместить и озеро данных и хранилище данных. Я работал не много со Snowflake, и это действительно уникальный продукт, который может так делать. Конечно Snowflake стоит денег, но у крупных компаний на западе серьезные бюджеты на аналитику.
В заключении, мое личное мнение, что нам все еще нужно хранилище данных как основной источник данных для нашей отчетности, и все, что не помещается, мы храним в озере данных. Вся роль аналитики — это предоставить удобный доступ бизнесу для принятия решений. Как ни крути, но бизнес пользователи работаю эффективней с хранилищем данных, чем озером данных, например в Amazon — есть Redshift (аналитическое хранилище данных) и есть Redshift Spectrum/Athena (SQL интерфейс для озера данных в S3 на базе Hive/Presto). Тоже самое относится к другим современным аналитическим хранилищам данных.
Давайте рассмотрим типичную архитектура хранилища данных:
Это классическое решение. У нас есть системы источники, с помощью ETL/ELT мы копируем данные в аналитическое хранилище данных и подключаем к Business Intelligence решению (мое любимое Tableau, а ваше?).
Такое решение имеет следующие недостатки:
Цель любого аналитического решения — служить бизнес пользователям. Поэтому мы всегда должны работать от требований бизнеса. (В Амазон это один из принципов — working backwards).
Работая и с хранилищем данных и с озером данных, мы можем сравнить оба решения:
Главный вывод, который можно сделать, что хранилище данных, никак не соревнуется с озером данных, а больше дополняет. Но это вам решать, что подходит для вашего случая. Всегда интересно, попробовать самому, и сделать правильные выводы.
Я хотел бы также рассказать по один из кейсов, когда я стал использовать подход озера данных. Все довольно банально, я попытался использовать инструмент ELT (у нас был Matillion ETL) и Amazon Redshift, мое решение работала, но не укладывалось в требования.
Мне необходимо было взять веб логи, трансформировать их и агрегировать, чтобы предоставить данные для 2х кейсов:
Один файл весил 1-4 мегабайта.
Но была одна трудность. У нас было 7 доменов по всему миру, и за один день создавалось 7 тысяч файлов. Это не очень больше объем, всего 50 гигабайт. Но размер нашего кластера Redshift был тоже небольшим (4 ноды). Загрузка традиционным способом одного файла занимала около минуты. То есть, в лоб задача не решалась. И это был тот случай, когда я решил использовать подход озера данных. Решение выглядело примерно так:
Оно достаточно простое (я хочу заметить, что преимущество работы в облаке это простота). Я использовал:
Совсем недавно я узнал один из недостатков озера данных — это GDPR. Проблема в том, когда клиент просит его удалить, а данные находятся в одном из файлов, мы не можем использовать Data Manipulation Language и операцию DELETE как в базе данных.
Надеюсь, статья прояснила разнице между хранилищем данных и озером данных. Если было интересно, то могу перевести еще свои статьи или статье профессионалов, которых читаю. А также рассказать про решения, с которыми работаю, и их архитектуру.
Data Lake – от теории к практике. Методы интеграции данных Hadoop и корпоративного DWH
В этой статье я хочу рассказать про важную задачу, о которой нужно думать и нужно уметь решать, если в аналитической платформе для работы с данными появляется такой важный компонент как Hadoop — задача интеграции данных Hadoop и данных корпоративного DWH. В Data Lake в Тинькофф Банке мы научились эффективно решать эту задачу и дальше в статье я расскажу, как мы это сделали.

Данная статья является продолжением цикла статей про Data Lake в Тинькофф Банке (предыдущая статья Data Lake – от теории к практике. Сказ про то, как мы строим ETL на Hadoop).
Задача
Лирическое отступление. Выше на рисунке изображено живописное озера, а точнее система озер – одно поменьше, другое побольше. То, что поменьше, красивое такое, облагороженное, с яхтами – это корпоративное DWH. А то, что виднеется на горизонте и не помещается на картинке в силу своих размеров – это Hadoop. Лирическое отступление окончено, к делу.
Задача у нас была достаточно тривиальная с точки зрения требований, и нетривиальная с точки зрения выбора технологии и реализации. Нам надо было прорыть канал между этими двумя озерами, наладить простой и эффективный способ публикации данных из Hadoop в DWH и обратно в рамках регламентных процессов, проистекающих в Data Lake.
Выбор технологии
Далее расскажу про преимущества и недостатки каждого из них.
Sqoop
Sqoop — это средство, предназначенное для передачи данных между кластерами Hadoop и реляционными базами данных. С его помощью можно импортировать данные из системы управления реляционной базой данных (реляционной СУБД), например, SQL Server, MySQL или Oracle, в распределенную файловую систему Hadoop (HDFS), преобразовать данные в системе Hadoop с использованием MapReduce или Hive, а затем экспортировать данные обратно в реляционную СУБД.
Т.к. в задаче изначально не предполагалась трансформация, то вроде бы Sqoop идеально подходит для решения поставленной задачи. Получается, что как только появляется потребность публикации таблицы (или в Hadoop, или в Greenplum), необходимо написать задание (job) на Sqoop и это задание научиться вызывать на одном из планировщиков (SAS или Informatica), в зависимости от регламента.
Всё хорошо, но Sqoop работает с Greenplum через JDBC. Мы столкнулись с крайне низкой производительностью. Тестовая таблица в 30 Gb выгружалась в Greenplum около 1 часа. Результат крайне неудовлетворительный. От Sqoop отказались. Хотя в целом, это очень удобный инструмент для того что бы, например, выгрузить разово в Hadoop, данные какой-либо не очень большой таблицы из реляционной БД. Но, для того что бы строить регламентные процессы на Sqoop, нужно четко понимать требования к производительности работы этих процессов и исходя из этого принимать решение.
Informatica Big Data Edition
Informatica Big Data Edition мы используем как ELT движок обработки данных в Hadoop. Т.е. как раз с помощью Informatica BDE мы строим в Hadoop те витрины, которые нужно опубликовать в Greenplum, где они станут доступны другим прикладным системам банка. Вроде как логично, после того как ELT процессы отработали на кластере Hadoop, построили витрину данных, сделать push этой витрины в Greenplum. Для работы с СУБД Greenplum в Informatica BDE есть PWX for Greenplum, который может работать как в режиме Native, так и в режиме Hive. Т.е., как только появляется потребность публикации таблицы из Hadoop в Greenplum, необходимо написать задание (mapping) на Informatica BDE и это задание вызвать на планировщике Informatica.
Всё хорошо, но есть нюанс. PWX for Greenplum в режиме Native работает как классический ETL, т.е. вычитывает из Hive данные на ETL сервер и уже на ETL сервере поднимает сессию gpload и грузит данные в Greenplum. Получается, что весь поток данных упирается в ETL-сервер.
Далее провели эксперименты в режиме Hive. PWX for Greenplum в режиме Hive работает без участия ETL сервера, ETL сервер только управляет процессом, вся работа с данными происходит на стороне кластера Hadoop (компоненты Informatica BDE устанавливаются так же и на кластер Hadoop). В этом случае сессии gpload поднимаются на узлах кластера Hadoop и грузят данные в Greenplum. Здесь мы не получаем узкое место в виде ETL сервера и производительность работы такого подхода получилась достаточно хорошей — тестовая таблица в 30 Gb выгружалась в Greenplum около 15 минут. Но PWX for Greenplum в режиме Hive работал, на момент проведения исследований, нестабильно. И есть ещё один важный момент. Если требуется сделать обратную публикацию данных (из Greenplum в Hadoop) PWX for Greenplum работает через ODBC.
Для решения задачи было принято решение не использовать Informatica BDE.
SAS Data Integration Studio
SAS Data Integration Studio мы используем как ELT движок обработки данных в Greenplum. Здесь получается другая картина. Informatica BDE строит необходимую витрину в Hadoop, далее SAS DIS делает pull этой витрины в Greenplum. Или иначе, SAS DIS строит какую-либо витрину в Greenplum, далее делает push этой витрины в Hadoop. Вроде бы красиво. Для работы с Hadoop в SAS DIS есть специальные компонент SAS Access Interface to Hadoop. Проводя параллель с PWX for Greenplum, у SAS Access Interface to Hadoop нет режима работы Hive и поэтому все данные польются через ETL сервер. Получили неудовлетворительную производительность работы процессов.
gphdfs
gphdfs – утилита, входящая в состав СУБД Greenplum, позволяющая организовать параллельный транспорт данных между сегмент серверами Greenplum и узлами с данными Hadoop. Провели эксперименты с публикацией данных и из Hadoop в Greenplum, и обратно – производительность работы процессов просто поразила. Тестовая таблица в 30 Gb выгружалась в Greenplum около 2 минут.
Анализ полученных результатов
Для наглядности в таблице ниже приведены результаты исследований.
Вывод получился двусмысленный — с наименьшими проблемами в производительности работы процессов, мы получаем утилиту, которую совершенно неприемлемо использовать в разработке ETL процессов как есть. Мы задумались… ELT платформа SAS Data Integration Studio позволяет разрабатывать на ней свои компоненты (трансформы) и мы решили, для того что бы снизить трудоемкость разработки ETL процессов и снизить сложность интеграции в регламентные процессы, разработать два трансформа, которые облегчат работу с gphdfs без потери производительности работы целевых процессов. Далее расскажу о деталях реализации.
Реализация трансформов
У этих двух трансформов достаточно простая задача, выполнить последовательно набор операций вокруг Hive и gphdfs.
Пример (дизайн) трансформа для публикации данных из Hadoop в Greenplum.
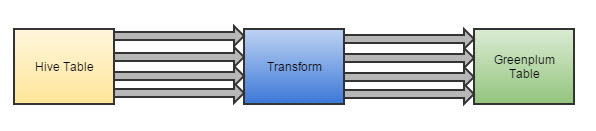
Разработчику остается добавить этот трансформ в job (задание) и указать названия входной и выходной таблиц.
Разработка такого процесса занимает около 15 минут.

По аналогии был реализован трансформ для публикации данных из Greenplum в Hadoop.
ВАЖНО. Ещё один из бенефитов который мы получили решив эту задачу, мы потенциально готовы организовывать процесс offload-а данных из корпоративного DWH в более дешевый Hadoop.
Озера данных: как устроены data lakes и зачем они нужны
Читайте «Хайтек» в
Озера, витрины и хранилища
Представьте, что у компании есть доступ к неисчерпаемому информационному ресурсу — погружаясь в него, аналитики регулярно получают ценные бизнес-инсайты и запускают новые, более совершенные продукты. Примерно по такому принципу работают озера данных — data lakes. Это относительно новый вид data-архитектуры, позволяющий воедино собирать сырые и разрозненные сведения из разных источников, а потом находить им эффективное применение. Первыми с технологией начали экспериментировать такие гиганты, как Oracle, Amazon и Microsoft — они же разработали удобные сервисы для построения озер.
Сам термин data lake ввел Джеймс Диксон, основатель платформы Pentaho. Он сравнивал витрины данных с озерами данных: первые похожи на бутилированную воду, которую очистили, отфильтровали и упаковали. Озера — это открытые водоемы, в которые вода стекается из разных источников. В них можно погружаться, а можно брать образцы с поверхности. Существуют еще дата-хранилища, которые выполняют конкретные задачи и служат определенным интересам. Озерные репозитории, напротив, могут принести пользу многим игрокам, если их грамотно использовать.
Казалось бы, потоки сведений только усложняют работу аналитикам, ведь сведения не структурированы, к тому же их слишком много. Но если компания умеет работать с данными и извлекать из них пользу, озеро не превращается в «болото».
Извлекаем данные из «бункера»
И все-таки какую пользу приносят data lakes компаниям? Их главное преимущество — это изобилие. В репозиторий попадают сведения от разных команд и подразделений, которые обычно никак между собой не связаны. Возьмем для примера онлайн-школу. Разные отделы ведут свою статистику и преследуют свои цели — одна команда следит за метриками удержания пользователей, вторая изучает customer journey новых клиентов, а третья собирает информацию о выпускниках. Доступа к полной картине нет ни у кого. Но если аккумулировать разрозненные сведения в едином репозитории, то можно обнаружить интересные закономерности. Например, окажется, что пользователи, которые пришли на курсы дизайна и просмотрели хотя бы два вебинара, чаще других доходят до конца программы и строят успешную карьеру на рынке. Эта информация поможет компании удержать студентов и создать более привлекательный продукт.
Часто неожиданные закономерности обнаруживаются случайно — так, озеро данных помогает дата-аналитикам экспериментально «скрещивать» разные потоки сведений и находить параллели, которые в других обстоятельствах они бы вряд ли обнаружили.
Источники данных могут быть любыми: у онлайн-школы это будет статистика с разных каналов продвижения, у фабрики — показатели IoT-датчиков, график использования станков и показатели износа оборудования, у маркетплейса — сведения о наличии товаров в стоке, статистика продаж и данные о самых популярных платежных методах. Озера как раз помогают собирать и изучать массивы информации, которые обычно никак не пересекаются и попадают в поле внимания разных отделов.
Еще один плюс дата-озер — это извлечение данных из разрозненных репозиториев и закрытых подсистем. Часто сведения хранятся в подобии информационного «бункера», доступ к которому есть только у одного подразделения. Перенести из него материалы сложно или невозможно — слишком много ограничений. Озера эту проблему решают.
Итак, можно выделить как минимум восемь преимуществ озер данных:
Озера в первую очередь нужны распределенным и разветвленным командам. Классический пример — Amazon. Корпорация аккумулировала данные из тысячи разных источников. Так, одни только финансовые транзакции хранились в 25 различных базах, которые были по-разному устроены и организованы. Это создавало путаницу и неудобства. Озеро помогло собрать все материалы в одном месте и установить единую систему защиты данных. Теперь специалисты — дата- и бизнес-аналитики, разработчики и CTO — могли брать нужные им компоненты и обрабатывать их, используя разные инструменты и технологии. А машинное обучение помогло аналитикам Amazon строить сверхточные прогнозы — теперь они знают, сколько коробок определенного размера потребуется для посылок в условном Техасе в ноябре.
Четыре шага к дата-озерам
Но у data lakes есть и недостатки. В первую очередь они требуют дополнительных ресурсов и высокого уровня экспертизы — по-настоящему извлечь из них пользу могут только высококвалифицированные аналитики. Также потребуются дополнительные инструменты Business Intelligence, которые помогут преобразовать инсайты в последовательную стратегию.
Другая проблема — это использование сторонних систем для поддержания data lakes. В этом случае компания зависит от провайдера. Если в системе произойдет сбой или утечка данных, это может привести к крупным финансовым потерям. Однако главная проблема озер — это хайп вокруг технологии. Часто компании внедряют этот формат, следуя моде, но не знают, зачем на самом деле им это нужно. В результате они тратят большие суммы, но не добиваются окупаемости. Поэтому эксперты советуют еще на стадии подготовки к запуску определить, какие бизнес-задачи будут решать озера.
Эксперты McKinsey выделяют четыре стадии создания data lakes:
Алгоритмы-аналитики
В самом аккумулировании данных нет ничего принципиально нового, но благодаря развитию облачных систем, платформ с открытым кодом и в целом увеличению компьютерных мощностей работать с озерной архитектурой сегодня могут даже стартапы.
Еще одним драйвером отрасли стало машинное обучение — технология отчасти упрощает работу аналитиков и дает им больше инструментов для пост-обработки. Если раньше специалист потонул бы в количестве файлов, сводок и таблиц, теперь он может «скормить» их алгоритму и быстрее построить аналитическую модель.
Использование дата-озер в комплексе с ИИ помогает не просто централизованно анализировать статистику, но и отслеживать тренды на протяжении всей истории работы компании. Так, один из американских колледжей собрал сведения об абитуриентах за последние 60 лет. Учитывались данные о количестве новых студентов, а также показатели по трудоустройству и общая экономическая ситуация в стране. В результате вуз скорректировал программу так, чтобы студенты заканчивали учебу, а не бросали курсы на полпути.
Какие еще бизнес-задачи могут решать дата-озера:
Впрочем, озера используют не только в бизнес-среде — например, в начале пандемии AWS собрала в едином репозитории сведения о COVID-19: данные исследований, статьи, статистические сводки. Информацию регулярно обновляли, а доступ к ней предоставили бесплатно — платить нужно было только за инструменты для аналитики.
Data lakes нельзя считать универсальным инструментом и панацеей, но в эпоху, когда данные считаются новой нефтью, компаниям важно искать разные пути исследования и применения big data. Главная задача — это централизация и консолидация разрозненных сведений. В эпоху микросервисов и распределенных команд часто возникают ситуации, когда один отдел не знает, над чем работает другой. Из-за этого бизнес тратит ресурсы, а разные специалисты выполняют одинаковые задачи, часто не подозревая об этом. В конечном итоге это снижает эффективность и перегружает «оперативную систему» компании. Как показывают опросы, большинство компаний инвестирует в озера данных как раз для повышения операционной эффективности. Но результаты превосходят ожидания: у ранних адептов технологии выручка и прибыль растут быстрее, чем у отстающих, а главное, они быстрее выводят на рынок новые продукты и услуги.