Популярные причины падения сайтов

Медленная загрузка и некорректная работа сайта, полное падение веб-ресурса или недоступность отдельных страниц – это настоящее бедствие для любого онлайн-бизнеса в независимости от тематики и направления. Теряется трафик, потенциальные клиенты уходят на конкурирующие ресурсы, падают продажи, снижаются seo-показатели и позиции в поисковой выдаче. Эта публикация посвящена обзору наиболее распространенных проблем и типичных «болезней» сайтов, опираясь на опыт сервиса мониторинга доступности сайтов ХостТрекер и его клиентов.
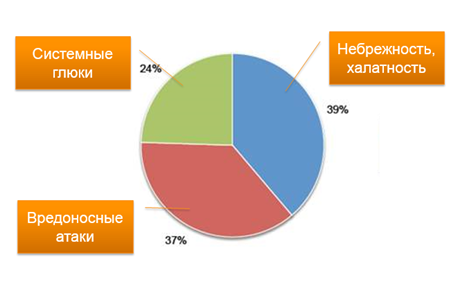
Причины недоступности веб-сайтов
Как с этим бороться?
Чтобы избежать оттока клиентов и падения продаж, снижения позиций при ранжировании поисковиками, нужно постоянно контролировать работу ресурса, своевременно получать информацию о недоступности сайта для пользователей и устранять неполадки.
Иными словами, постоянно поддерживать сайт.
Физически невозможно круглосуточно следить за функционированием веб-ресурсов, поминутно в ручном режиме перезагружая отдельные страницы. Поэтому желательно максимально автоматизировать процесс работы, обновлений и мониторинга сайта, а также каким-то образом настроить обратную связь — чтобы вовремя узнавать о неполадках. Популярными решениями являются сервисы Яндекс.Метрика и Google Analytics. Они действуют таким образом: клиент размещает у себя на сайте специальный скрипт, который каждый раз при входе на сайт посетителя отправляет данные куда надо. Во-первых, Вы получаете много хорошей статистики. Во-вторых, если вдруг посещение сайта падает, то появляется предположение, что с сайтом что-то не то, о чем они вас могут оповестить. Могут и отдельно перепроверить. Разные сервисы предлагают разные интересные функции. Но есть и отдельные профессиональные инструменты для подобных задач.
Сервисы мониторинга: выявление проблем
Провести диагностику веб-ресурса, выявить причины неполадок и установить круглосуточный контроль над функционированием сайта можно с помощью специализированных сервисов. Службы мониторинга предоставляют различные инструменты для комплексной и полностью автоматизированной проверки сайтов. Примером такого сервиса является, собственно, ХостТрекер.
С помощью подобных сервисов можно легко и быстро найти слабые места сайта и получить реальную картину его поведения во времени, а также избежать награды непричастных и наказания невиновных.
Это работает для всех вышеуказанных проблем. Если сервис показывает, что у сайта «прыгает» скорость загрузки, при том что количество посетителей равномерно распределено в течении дня, или же возвращаются таймауты — вопросы к хостеру. Также это может быть свидетельством того, что ваш сайт «перерос» купленный когда-то начальный пакет услуг хостинга, и сейчас для стабильной работы ему нужно больше ресурсов. К хостеру же возникают вопросы, если в договоре он гарантирует SLA 99.9%, а сам ежемесячно проводит многочасовые технические работы: легко проверить, не нарушил ли он свои гарантии. Если часто выпадают ошибки 50Х — скорее всего, дело в сайте или настройках сервера. В этом случае обращаемся к разработчикам. Сервисы также контролируют срок действия сертификатов и доменов, вовремя оповещая о необходимости продления, а также множество других вещей.
Пять шагов к спасению Linux-сервера, который рухнул
Мне доводилось видеть множество Linux-серверов, которые, без единой перезагрузки, работали годами, в режиме 24×7. Но ни один компьютер не застрахован от неожиданностей, к которым могут вести «железные», программные и сетевые сбои. Даже самый надёжный сервер может однажды отказать. Что делать? Сегодня вы узнаете о том, что стоит предпринять в первую очередь для того, чтобы выяснить причину проблемы и вернуть машину в строй.

Поиск и устранение неполадок: раньше и теперь
Когда, в 1980-х, я начал работать системным администратором Unix — задолго до того, как Линус Торвальдс загорелся идеей Linux — если с сервером было что-то не так, это была реальная засада. Тогда было сравнительно мало инструментов для поиска проблем, поэтому для того, чтобы сбойный сервер снова заработал, могло понадобиться много времени.
Теперь всё совсем не так, как раньше. Как-то один системный администратор вполне серьёзно сказал мне, говоря о проблемном сервере: «Я его уничтожил и поднял новый».
В былые времена такое звучало бы дико, но сегодня, когда ИТ-инфраструктуры строят на основе виртуальных машин и контейнеров… В конце концов, развёртывание новых серверов по мере необходимости — это обычное дело в любой облачной среде.
Сюда надо добавить инструменты DevOps, такие, как Chef и Puppet, используя которые легче создать новый сервер, чем диагностировать и «чинить» старый. А если говорить о таких высокоуровневых средствах, как Docker Swarm, Mesosphere и Kubernetes, то благодаря им работоспособность отказавшего сервера будет автоматически восстановлена до того, как администратор узнает о проблеме.
Данная концепция стала настолько распространённой, что ей дали название — бессерверные вычисления. Среди платформ, которые предоставляют подобные возможности — AWS Lambda, Iron.io, Google Cloud Functions.
Благодаря такому подходу облачный сервис отвечает за администрирование серверов, решает вопросы масштабирования и массу других задач для того, чтобы предоставить клиенту вычислительные мощности, необходимые для запуска его приложений.
Бессерверные вычисления, виртуальные машины, контейнеры — все эти уровни абстракции скрывают реальные серверы от пользователей, и, в некоторой степени, от системных администраторов. Однако, в основе всего этого — физическое аппаратное обеспечение и операционные системы. И, если что-то на данном уровне вдруг разладится, кто-то должен привести всё в порядок. Именно поэтому то, о чём мы сегодня говорим, никогда не потеряет актуальности.
Помню разговор с одним системным оператором. Вот что он говорил о том, как надо поступать после сбоя: «Переустановка сервера — это путь вникуда. Так не понять — что стало с машиной, и как не допустить такого в будущем. Ни один сносный администратор так не поступает». Я с этим согласен. До тех пор, пока не обнаружен первоисточник проблемы, её нельзя считать решённой.
Итак, перед нами сервер, который дал сбой, или мы, по крайней мере, подозреваем, что источник неприятностей именно в нём. Предлагаю вместе пройти пять шагов, с которых стоит начинать поиск и решение проблем.
Шаг первый. Проверка аппаратного обеспечения
В первую очередь — проверьте железо. Я знаю, что звучит это тривиально и несовременно, но, всё равно — сделайте это. Встаньте с кресла, подойдите к серверной стойке и удостоверьтесь в том, что сервер правильно подключён ко всему, необходимому для его нормальной работы.
Я и сосчитать не смогу, сколько раз поиски причины проблемы приводили к кабельным соединениям. Один взгляд на светодиоды — и становится ясно, что Ethernet-кабель выдернут, или питание сервера отключено.
Конечно, если всё выглядит более-менее прилично, можно обойтись без визита к серверу и проверить состояние Ethernet-соединения такой командой:
Если её ответ можно трактовать, как «да», это значит, что исследуемый интерфейс способен обмениваться данными по сети.
Однако, не пренебрегайте возможностью лично осмотреть устройство. Это поможет, например, узнать, что кто-то выдернул какой-нибудь важный кабель и обесточил таким образом сервер или всю стойку. Да, это до смешного просто, но удивительно — как часто причина отказа системы именно в этом.
Ещё одну распространённую аппаратную проблему невооружённым взглядом не распознать. Так, сбойная память является причиной всевозможных проблем.
Виртуальные машины и контейнеры могут скрывать эти проблемы, но если вы столкнулись с закономерным появлением отказов, связанных с конкретным физическим выделенным сервером, проверьте его память.
Для того, чтобы увидеть, что BIOS/UEFI сообщают об аппаратном обеспечении компьютера, включая память, используйте команду dmidecode:
Даже если всё тут выглядит нормально, на самом деле это может быть и не так. Дело в том, что данные SMBIOS не всегда точны. Поэтому, если после dmidecode память всё ещё остаётся под подозрением — пришло время воспользоваться Memtest86. Это отличная программа для проверки памяти, но работает она медленно. Если вы запустите её на сервере, не рассчитывайте на возможность использовать эту машину для чего-нибудь другого до завершения проверки.
Если вы сталкиваетесь со множеством проблем с памятью — я видел такое в местах, отличающихся нестабильным электропитанием — нужно загрузить модуль ядра Linux edac_core. Этот модуль постоянно проверяет память в поиске сбойных участков. Для того, чтобы загрузить этот модуль, воспользуйтесь такой командой:
Подождите какое-то время и посмотрите, удастся ли что-нибудь увидеть, выполнив такую команду:
Эта команда даст вам сводку о числе ошибок, разбитых по модулям памяти (показатели, название которых начинается с csrow ). Эти сведения, если сопоставить их с с данными dmidecode о каналах памяти, слотах и заводских номерах компонентов, помогут выявить сбойную планку памяти.
Шаг второй. Поиск истинного источника проблемы
Итак, сервер стал странно себя вести, но дым из него ещё пока не идёт. В сервере ли дело? Прежде чем вы попытаетесь решить возникшую проблему, сначала нужно точно определить её источник. Скажем, если пользователи жалуются на странности с серверным приложением, сначала проверьте, что причина проблемы — не в сбоях на клиенте.
Например, друг однажды рассказал мне, как его пользователи сообщили о том, что не могут работать с IBM Tivoli Storage Manager. Сначала, конечно, казалось, что виновен во всём сервер. Но в итоге администратор выяснил, что проблема вообще не была связана с серверной частью. Причиной был неудачный патч Windows-клиента 3076895. Но то, как сбоило это обновление безопасности, делало происходящее похожим на проблему серверной стороны.
Кроме того, нужно понять, является ли причиной проблемы сам сервер, или серверное приложение. Например, серверная программа может работать кое как, а железо оказывается в полном порядке.
Для начала — самое очевидное. Работает ли приложение? Есть множество способов проверить это. Вот два моих любимых:
Если оказалось, что, например, веб-сервер Apache не работает, запустить его можно такой командой:
Если в двух словах, то прежде чем диагностировать сервер и искать причину проблему, узнайте — сервер ли виноват, или что-то другое. Только тогда, когда вы поймёте, где именно находится источник сбоя, вы сможете задавать правильные вопросы и переходить к дальнейшему анализу того, что произошло.
Это можно сравнить с неожиданной остановкой автомобиля. Вы знаете, что машина дальше не едет, но, прежде чем тащить её в сервис, хорошо бы проверить, есть ли бензин в баке.
Шаг третий. Использование команды top
Шаг четвёртый. Проверка дискового пространства
Даже сегодня, когда в кармане можно носить терабайты информации, на сервере, совершенно незаметно, может кончиться дисковое пространство. Когда такое происходит — можно увидеть весьма странные вещи.
Разобраться с дисковым пространством нам поможет старая добрая команда df, имя которой является сокращением от «disk filesystem». С её помощью можно получить сводку по свободному и использованному месту на диске.
Обычно df используют двумя способами.
Если что-то кажется вам странным, можно копнуть глубже, воспользовавшись командой Iostat. Она является частью sysstat — продвинутого набора инструментов для мониторинга системы. Она выводит сведения о процессоре, а также данные о подсистеме ввода-вывода для блочных устройств хранения данных, для разделов и сетевых файловых систем.
Вероятно, самый полезный способ вызова этой команды выглядит так:
Такая команда выводит сведения об объёме прочитанных и записанных данных для устройства. Кроме того, она покажет среднее время операций ввода-вывода в миллисекундах. Чем больше это значение — тем вероятнее то, что накопитель перегружен запросами, или перед нами — аппаратная проблема. Что именно? Тут можно воспользоваться утилитой top для того, чтобы выяснить, нагружает ли сервер MySQL (или какая-нибудь ещё работающая на нём СУБД). Если подобных приложений найти не удалось, значит есть вероятность, что с диском что-то не так.
Работая с утилитами для проверки дисков, обращайте внимание, что именно вы анализируете.
Например, нагрузка в 100% на логический диск, который представляет собой несколько физических дисков, может означать лишь то, что система постоянно обрабатывает какие-то операции ввода-вывода. Значение имеет то, что именно происходит на физических дисках. Поэтому, если вы анализируете логический диск, помните, что дисковые утилиты не дадут полезной информации.
Шаг пятый. Проверка логов
Для новичков в Linux лог-файлы могут выглядеть как ужасная мешанина. Это — текстовые файлы, в которые записываются сведения о том, чем занимаются операционная система и приложения. Есть два вида записей. Одни записи — это то, что происходит в системе или в программе, например — каждая транзакция или перемещение данных. Вторые — сообщения об ошибках. В лог-файлах может содержаться и то, и другое. Эти файлы могут быть просто огромными.
Данные в файлах журналов обычно выглядят довольно таинственно, но вам всё равно придётся с ними разобраться. Вот, например, хорошее введение в эту тему от Digital Ocean.
Есть множество инструментов, которые помогут вам проверить логи. Например — dmesg. Эта утилита выводит сообщения ядра. Обычно их очень и очень много, поэтому используйте следующий простой сценарий командной строки для того, чтобы просмотреть 10 последних записей:
Вот ещё один удобный сценарий командной строки:
Он сканирует логи и показывает возможные проблемы.
Бывает полезно настроить journald так, чтобы он сохранял логи после перезагрузки системы. Сделать это можно, воспользовавшись такой командой:
Самый распространённый способ работать с этими журналами — такая команда:
Она покажет все записи журналов после последней перезагрузки. Если система была перезагружена, посмотреть, что было до этого, можно с помощью такой команды:
Мне, например, нравится система для управления логами с открытым кодом Graylog. Она собирает, индексирует и анализирует самые разные сведения. В её основе лежат MongoDB для работы с данными и Elasticsearch для поиска по лог-файлам. Graylog упрощает отслеживание состояния сервера. Graylog, если сравнить её со встроенными средствами Linux, проще и удобнее. Кроме того, среди её полезных возможностей можно отметить возможность работы с многими DevOps-системами, такими, как Chef, Puppet и Ansible.
Итоги
Как бы вы ни относились к вашему серверу, возможно, он не попадёт в Книгу Рекордов Гиннеса как тот, который проработал дольше всех. Но стремление сделать сервер как можно более стабильным, добираясь до сути неполадок и исправляя их — достойная цель. Надеемся, то, о чём мы сегодня рассказали, поможет вам достичь этой цели.
Уважаемые читатели! А как вы обычно поступаете с упавшими серверами?
Топ-10 причин падения серверов
— Ты чего такой грустный?
— Да вот сервер вчера «упал».
— Ну да, ты что его до сих пор не «поднял»?
— Поднял, но он со стола упал.
10 место. Резервное копирование. Системные администраторы бывают двух видов: которые делают резервные копии и которые пока не делают резервные копии. Бывает еще и третий вид, но очень редкий: системные администраторы, которые проверяют свои резервные копии. На них вся надежда.
8 место. Оборудование. Вместо серверных платформ используются обычные рабочие станции. Бывали случаи, когда база 1С лежала у бухгалтера на рабочем компьютере на диске D, и даже резервных копий никто не делал! Вопиющая смелость!
7 место. Использование нелицензионного ПО. Был случай, когда один товарищ пытался убедить меня в то, что весть его софт абсолютно лицензионный. Дабы подтвердить свои слова, мне был продемонстрирован лицензионный компакт-диск со всем софтом, купленный в фирменной палатке на Ждановичах. Чек прилагался.
6 место. Плановые замены HDD. Примерно раз в два-три месяца слышу новую историю про рассыпавшийся RAID. Для серверных винчестеров ресурс составляет не более 4 лет. Еще одной частой ошибкой является использование дешевых, не серверных винчестеров, что также весьма чревато. Еще я рекомендую при покупке нового оборудования закупать парочку винчестеров в запас, на всякий пожарный.
5 место. Запуск нескольких сервисов на одном сервере. Говорят, системные администраторы не смешиваю. Все они смешивают! Особенно любят администраторы смешивать контроллеры домена с чем-нибудь еще, например, с MS SQL и с 1C, файловым сервером, прокси-сервером и др. Лет 5 назад это не вызвало бы больших нареканий, но сегодня нравы поменялись, смешивать как минимум, неприлично, как максимум, небезопасно.
4 место. Встроенная учетная запись администратора. Как взломать сервер: берем шару и подбираем пароль к встроенной учетной записи администратора. Если пароль состоит из 4 цифр – пара минут, и сервер наш! А всего-то нужно было учетную запись отключить, а еще лучше и переименовать, да через групповые политики.
2 место. Брандмауэр. Какими бы крепкими ни были стены города, они не защитят жителей от больного чумой внутри периметра. Конечно, все дома в городе забором не обнесешь, а вот улочку с серверами обгородить вполне возможно, более того, сисадмины могут сделать это бесплатно и быстро, а если повезет, то и качественно.
В очередной раз мы видим, как данные статистики сходятся с жизненными реалиями. А как дела обстоят у вас?
Андрей Махнач
руководитель отдела инфраструктурных решений СООО «ДПА»
Как привести в порядок перегруженный сервер?
Материал, перевод которого мы сегодня публикуем, посвящён поиску узких мест в производительности серверов, исправлению проблем, улучшению производительности систем и предотвращению падения производительности. Здесь, на пути к решению проблем перегруженного сервера, предлагается сделать следующие 4 шага:
1. Оценка ситуации
Когда трафик перегружает сервер, узким местом производительности могут стать процессор, сеть, память, дисковая подсистема ввода-вывода. Определение того, что именно вызывает проблему, позволяет сконцентрировать усилия на самом важном. Рассмотрим некоторые особенности анализа важнейших серверных подсистем.
Начать работу по выявлению проблем сервера можно, воспользовавшись командой top. Если есть такая возможность, здесь можно прибегнуть к историческим данным хостинг-провайдера и к данным, собранным системами мониторинга.
2. Стабилизация сервера
Наличие в системе перегруженного сервера может быстро привести к каскадным отказам в других частях системы. В результате важно, после того, как стало известно о том, что сервер перегружен, стабилизировать его, а уже потом исследовать ситуацию на предмет внесения в систему неких серьёзных улучшений.
▍Ограничение скорости обработки запросов
Ограничение скорости обработки запросов позволяет защитить инфраструктуру, ограничивая количество входящих запросов. Это очень важно при падении производительности сервера. По мере того, как растёт время ответа сервера, пользователи имеют свойство агрессивно обновлять страницу, что ещё сильнее повышает нагрузку на сервер.
Хотя отказ от обработки запроса — мера простая и действенная, лучше всего снижать нагрузку на сервер, занимаясь ограничением числа поступающих к нему запросов средствами некоей внешней системы. Это может быть, например, балансировщик нагрузки, обратный прокси-сервер или CDN. Ниже приведены ссылки на инструкции по работе с несколькими системами такого рода:
▍HTTP-кеширование
Поищите способы улучшения кеширования содержимого. Если ресурс может быть отдан пользователю из HTTP-кеша (из кеша браузера или из CDN), тогда его не нужно запрашивать с сервера, что уменьшает нагрузку на сервер.
HTTP-заголовки наподобие Cache-Control, Expires и ETag указывают на то, как должен кешироваться тот или иной ресурс. Аудит и исправление этих заголовков могут помочь улучшить кеширование.
Хотя для кеширования можно прибегнуть к возможностям сервис-воркеров, они используют отдельный кеш. Это — помощь основной системе кеширования браузера, а не её замена. Поэтому при исправлении проблем перегруженного сервера усилия надо сосредоточить на оптимизации HTTP-кеширования.
Диагностика
Запустите Lighthouse и взгляните на показатель Serve static assets with an efficient cache policy для того чтобы увидеть список ресурсов с коротким и средним временем кеширования (Time To Live, TTL). Проанализируйте ресурсы, перечисленные в списке, и рассмотрите возможность увеличения их TTL. Вот ориентировочные сроки кеширования, применимые к различным ресурсам.
Настройка кеширования
Нужно записать в директиву max-age заголовка Cache-Control необходимое время кеширования ресурса, выраженное в секундах. Вот инструкции по настройке этого заголовка в разных системах:
▍Постепенное сокращение возможностей системы
Постепенное сокращение возможностей системы — это стратегия временного ограничения функционала, направленная на снятие с сервера чрезмерной нагрузки. Эта концепция может быть применена множеством различных способов. Например, выдача клиентам статической текстовой страницы вместо полномасштабного приложения, отключение поиска или возврат меньшего, чем обычно, количества результатов поиска. Сюда относится и отключение ресурсоёмких возможностей проектов, не влияющих на их основной функционал. Основное внимание тут должно быть уделено отключению функционала, от которого можно отказаться, не слишком сильно воздействовав на основные возможности приложения.
3. Улучшение системы
▍Использование CDN
Задача по обслуживанию статических ресурсов может быть переложена с сервера на сеть доставки контента (Content Delivery Network, CDN). Это позволит снизить нагрузку на сервер.
Основная функция CDN заключается в быстрой доставке материалов пользователям благодаря использованию большой сети серверов, расположенных поблизости от пользователей. Кроме того, некоторые CDN предлагают дополнительные возможности, связанные с производительностью. Среди них — сжатие данных, балансировка нагрузки, оптимизация медиа-файлов.
Настройка CDN
Преимущества CDN раскрываются в том случае, если компания, владеющая сетью, имеет большую группировку серверов, распределённых по всему миру. Поэтому поддержка собственного CDN-сервиса редко имеет смысл. Обычная настройка CDN — это достаточно быстрая процедура, занимающая около получаса. Она заключается в обновлении DNS-записей таким образом, чтобы они указывали бы на CDN.
Оптимизация использования CDN: исследование ситуации
Для того чтобы идентифицировать ресурсы, которые обслуживаются не с помощью CDN (но должны выдаваться пользователям с CDN), можно воспользоваться WebPageTest. На странице результатов щёлкните по прямоугольнику, подписанному как Effective use of CDN и просмотрите список ресурсов, которые следует обслуживать средствами CDN.

Результаты, выдаваемые WebPageTest
Решение проблем
Если ресурсы не кешируются с помощью CDN, выясните, выполняются ли следующие условия:
▍Масштабирование вычислительных ресурсов
Решение относительно масштабирования вычислительных ресурсов следует принимать с осторожностью. Хотя часто решить некие проблемы можно, прибегнув к масштабированию, сделав это несвоевременно, можно неоправданно усложнить систему и необоснованно повысить затраты на её поддержку.
Диагностика
Высокий показатель, характеризующий время до первого байта (Time To First Byte, TTFB), может быть признаком того, что сервер приближается к пределам своих возможностей. Найти сведения о TTFB можно в разделе Reduce server response times (TTFB) отчёта Lighthouse.
Для более глубокого исследования ситуации нужно воспользоваться каким-нибудь средством мониторинга и проанализировать использование процессора. Если текущее или прогнозируемое значение загрузки процессора превышает 80% — это значит, что нужно задуматься о повышении мощности сервера.
Решение проблем
Добавление в систему балансировщика нагрузки позволяет распределять трафик между множеством серверов. Балансировщик нагрузки находится перед пулом серверов и распределяет трафик на подходящие серверы. Облачные провайдеры предлагают пользователям балансировщики нагрузки (GCP, AWS, Azure), но можно пользоваться и собственным балансировщиком, применив HAProxy или NGINX. После того, как балансировщик нагрузки готов к работе, в систему можно добавлять дополнительные серверы.
В дополнение к балансировке нагрузки большинство облачных провайдеров предлагает услуги по автоматическому масштабированию вычислительных мощностей (GCP, AWS, Azure). Автоматическое масштабирование связано с балансировкой нагрузки. А именно, при автоматическом масштабировании ресурсов в моменты высокой нагрузки производится выделение дополнительных ресурсов, а в периоды низкой — отключение ненужных ресурсов. Но, даже учитывая это, нужно отметить, что автоматическое масштабирование — это тоже не универсальное решение. Для автоматического запуска серверов нужно время. Конфигурации автоматического масштабирования требуют серьёзной настройки. Поэтому до применения сложной системы автоматического масштабирования стоит опробовать сравнительно простую конфигурацию с балансировщиком нагрузки.
▍Использование сжатия данных
Текстовые ресурсы нужно сжимать с использованием алгоритма gzip или brotli. В некоторых случаях сжатие может помочь в сокращении размеров таких ресурсов примерно на 70%.
Диагностика
Для того чтобы найти ресурсы, нуждающиеся в сжатии, можете воспользоваться показателем Enable text compression из отчёта Lighthouse.
Решение проблем
Для включения сжатия нужно отредактировать настройки сервера. Вот подробности об этом:
▍Оптимизация изображений и других медиа-материалов
На изображения приходится основной объём материалов большинства веб-сайтов. Оптимизация изображений может привести к значительному уменьшению размеров материалов сайта. При этом такая оптимизация выполняется достаточно быстро.
Диагностика
В отчёте Lighthouse есть разные показатели, которые указывают на потенциальные возможности по оптимизации изображений. Для поиска крупных изображений, нуждающихся в оптимизации, можно воспользоваться и обычными инструментами разработчика браузера. Такие изображения вполне могут стать хорошими кандидатами на оптимизацию.
Вот список показателей отчёта LightHouse, на которые стоит обратить внимание, исследуя возможность оптимизации изображений:
Решение проблем
Сначала поговорим о том, что стоит предпринять в том случае, если у вас мало времени.
В такой ситуации стоит обратить внимание на большие изображения, и на изображения, которые загружаются чаще других. Обнаружив их, их надо подвергнуть ручной оптимизации, воспользовавшись инструментом наподобие Squoosh. Хорошими кандидатами на оптимизацию обычно являются большие фотографии. Например, взятые с ресурса вроде Hero Images.
Вот на что надо обращать внимание, оптимизируя изображения:
Если изображения составляют значительную долю материалов сайта — рассмотрите возможность использования для их обслуживания специализированного CDN-сервиса, рассчитанного на работу с изображениями. Такие сервисы позволяют снять нагрузку по работе с изображениями с основного сервера. Настройка проекта на использование подобного CDN-сервиса проста, но она требует обновления существующих ссылок на изображения таким образом, чтобы они указывали бы на CDN-ресурсы. Вот материал, посвящённый использованию специализированных CDN-сервисов, рассчитанных на изображения.
▍Минификация JavaScript- и CSS-кода
Минификация кода позволяет уменьшать его размер, удаляя ненужные символы.
Диагностика
Взгляните на показатели Minify CSS и Minify JavaScript отчёта Lighthouse для того чтобы выявить ресурсы, нуждающиеся в минификации.
Решение проблем
Если у вас мало времени — сосредоточьтесь на минификации JavaScript-кода. На большинстве сайтов объём JavaScript-кода превышает объём CSS-кода, поэтому такой ход даст лучшие результаты. Вот материал о минификации JavaScript, а вот — о минификации CSS.
4. Мониторинг сервера
Инструменты для мониторинга серверов поддерживают сбор данных и их визуализацию с использованием панелей управления. Они умеют оповещать пользователей о различных событиях, имеющих отношение к производительности серверов. Использование таких инструментов может помочь в предотвращении и смягчении проблем с производительностью серверов.
Настраивая систему мониторинга, стоит стремиться к как можно большей простоте. Сбор чрезмерного количества данных и слишком частые уведомления способны вызывать негативные эффекты. Чем шире диапазон собираемых данных и чем чаще осуществляется их сбор — тем дороже будет обходиться их сбор и хранение. А если того, кто отвечает за состояние сервера, будут заваливать сообщениями о незначительных событиях, то он, в итоге, будет эти сообщения игнорировать.
В уведомлениях должны содержаться метрики, которые последовательно и точно описывают проблемы. Например, время ответа сервера (latency) — это метрика, которая особенно хорошо для этого подходит: она позволяет выявить большое количество проблемных ситуаций и напрямую связана с тем, как сервер воспринимается пользователями. Уведомления, основанные на низкоуровневых метриках, вроде уровня использования процессора, могут играть роль полезного дополнения, но они способны указать лишь на небольшую часть возможных проблем. Кроме того, уведомления должны быть основаны не на средних показателях, а на показателях, соответствующих 95-99 перцентилям. В противном случае анализ средних значений может легко привести к пропуску проблем, которые не затрагивают всех пользователей.
Настройка мониторинга
Все основные облачные провайдеры предоставляют клиентам собственные инструменты мониторинга (GCP, AWS, Azure). Кроме того, тут можно отметить инструмент Netdata — отличную бесплатную опенсорсную альтернативу инструментам провайдеров. Вне зависимости от того, чем именно вы пользуетесь, вам понадобится установить на каждый сервер, который нужно мониторить, приложение-агент. После завершения настройки системы не забудьте настроить уведомления. Вот инструкции по настройке разных средств мониторинга:
Итоги
Сегодня мы поговорили о том, как выявлять и исправлять проблемы с производительностью серверов. Хочется верить, что ваши серверы будут работать стабильно и вам советы из этого материала не пригодятся. А если что-то пойдёт не так — надеемся, тут вы нашли что-то такое, что поможет вам как можно быстрее справиться с проблемой.
Уважаемые читатели! Что вы делаете в ситуации, когда сервер, на котором работает ваш проект, начинает «тормозить»?