Рекуррентные нейронные сети (RNN) с Keras
Перевод руководства по рекуррентным нейросетям с сайта Tensorflow.org. В материале рассматриваются как встроенные возможности Keras/Tensorflow 2.0 по быстрому построению сеток, так и возможности кастомизации слоев и ячеек. Также рассматриваются случаи и ограничения использования ядра CuDNN позволяющего ускорить процесс обучения нейросети.

Рекуррентные нейронные сети (RNN) — это класс нейронных сетей, которые хороши для моделирования последовательных данных, таких как временные ряды или естественный язык.
Если схематично, слой RNN использует цикл for для итерации по упорядоченной по времени последовательности, храня при этом во внутреннем состоянии, закодированную информацию о шагах, которые он уже видел.
Keras RNN API разработан с фокусом на:
Простота кастомизации: Вы можете также задать собственный слой ячеек RNN (внутреннюю часть цикла for ) с кастомным поведением и использовать его с общим слоем `tf.keras.layers.RNN` (сам цикл `for`). Это позволит вам быстро прототипировать различные исследовательские идеи в гибкой манере, с минимумом кода.
Установка
Построение простой модели
В Keras есть три встроенных слоя RNN:
Выходы и состояния
Кроме того, слой RNN может вернуть свое конечное внутреннее состояние (состояния).
Возвращенные состояния можно использовать позже для возобновления выполнения RNN или для инициализации другой RNN. Эта настройка обычно используется в модели энкодер-декодер, последовательность к последовательности, где итоговое состояние энкодера используется для начального состояния декодера.
Для того чтобы слой RNN возвращал свое внутреннее состояние, установите параметр return_state в значение True при создании слоя. Обратите внимание, что у LSTM 2 тензора состояния, а у GRU только один.
Заметьте что размерность должна совпадать с размерностью элемента слоя, как в следующем примере.
RNN слои и RNN ячейки
RNN API в дополнение к встроенным слоям RNN, также предоставляет API на уровне ячейки. В отличие от слоев RNN, которые обрабатывают целые пакеты входных последовательностей, ячейка RNN обрабатывает только один временной шаг.
Существует три встроенных ячейки RNN, каждая из которых соответствует своему слою RNN.
Кросс-пакетное сохранение состояния
При обработке длинных последовательностей (возможно бесконечных), вы можете захотеть использовать паттерн кросс-пакетное сохранение состояния (cross-batch statefulness).
Обычно, внутреннее состояние слоя RNN сбрасывается при каждом новом пакете данных (т.е. каждый пример который видит слой предполагается независимым от прошлого). Слой будет поддерживать состояние только на время обработки данного элемента.
Однако, если у вас очень длинные последовательности, полезно разбить их на более короткие и по очереди передавать их в слой RNN без сброса состояния слоя. Таким образом, слой может сохранять информацию обо всей последовательности, хотя он будет видеть только одну подпоследовательность за раз.
Вы можете сделать это установив в конструкторе `stateful=True`.
Если у вас есть последовательность `s = [t0, t1,… t1546, t1547]`, вы можете разбить ее например на:
Потом вы можете обработать ее с помощью:
Приведем полный пример:
Двунаправленные RNN
Для последовательностей отличных от временных рядов (напр. текстов), часто бывает так, что модель RNN работает лучше, если она обрабатывает последовательность не только от начала до конца, но и наоборот. Например, чтобы предсказать следующее слово в предложении, часто полезно знать контекст вокруг слова, а не только слова идущие перед ним.
Под капотом, Bidirectional скопирует переданный слой RNN layer, и перевернет поле go_backwards вновь скопированного слоя, и таким образом входные данные будут обработаны в обратном порядке.
На выходе` Bidirectional RNN по умолчанию будет сумма вывода прямого слоя и вывода обратного слоя. Если вам нужно другое поведение слияния, напр. конкатенация, поменяйте параметр `merge_mode` в конструкторе обертки `Bidirectional`.
Оптимизация производительности и ядра CuDNN в TensorFlow 2.0
В TensorFlow 2.0, встроенные слои LSTM и GRU пригодны для использования ядер CuDNN по умолчанию, если доступен графический процессор. С этим изменением предыдущие слои keras.layers.CuDNNLSTM/CuDNNGRU устарели, и вы можете построить свою модель, не беспокоясь об оборудовании, на котором она будет работать.
Поскольку ядро CuDNN построено с некоторыми допущениями, это значит, что слой не сможет использовать слой CuDNN kernel если вы измените параметры по умолчанию встроенных слоев LSTM или GRU. Напр:
Когда это возможно используйте ядра CuDNN
Загрузка датасета MNIST
Создайте экземпляр модели и скомпилируйте его
Постройте новую модель без ядра CuDNN
Как вы можете видеть, модель построенная с CuDNN намного быстрее для обучения чем модель использующая обычное ядро TensorFlow.
Ту же модель с поддержкой CuDNN можно использовать при выводе в однопроцессорной среде. Аннотация tf.device просто указывает используемое устройство. Модель выполнится по умолчанию на CPU если не будет доступно GPU.
Вам просто не нужно беспокоиться о железе на котором вы работаете. Разве это не круто?
RNN с входными данными вида список/словарь, или вложенными входными данными
Вложенные структуры позволяют включать больше информации в один временного шага. Например, видеофрейм может содержать аудио и видео на входе одновременно. Размерность данных в этом случае может быть:
В другом примере, у рукописных данных могут быть обе координаты x и y для текущей позиции ручки, так же как и информация о давлении. Так что данные могут быть представлены так:
В следующем коде построен пример кастомной ячейки RNN которая работает с такими структурированными входными данными.
Определите пользовательскую ячейку поддерживающую вложенный вход/выход
Постройте модель RNN с вложенными входом/выходом
Давайте построим модель Keras которая использует слой tf.keras.layers.RNN и кастомную ячейку которую мы только определили.
Обучите модель на случайно сгенерированных данных
Поскольку у нас нет хорошего датасета для этой модели, мы используем для демонстрации случайные данные, сгенерированные библиотекой Numpy.
Рекуррентные нейронные сети: типы, обучение, примеры и применение

Рекуррентные нейронные сети (Recurrent Neural Networks, RNNs) — популярные модели, используемые в обработке естественного языка (NLP). Во-первых, они оценивают произвольные предложения на основе того, насколько часто они встречались в текстах. Это дает нам меру грамматической и семантической корректности. Такие модели используются в машинном переводе. Во-вторых, языковые модели генерируют новый текст. Обучение модели на поэмах Шекспира позволит генерировать новый текст, похожий на Шекспира.
Что такое рекуррентные нейронные сети?
Идея RNN заключается в последовательном использовании информации. В традиционных нейронных сетях подразумевается, что все входы и выходы независимы. Но для многих задач это не подходит. Если вы хотите предсказать следующее слово в предложении, лучше учитывать предшествующие ему слова. RNN называются рекуррентными, потому что они выполняют одну и ту же задачу для каждого элемента последовательности, причем выход зависит от предыдущих вычислений. Еще одна интерпретация RNN: это сети, у которых есть «память», которая учитывает предшествующую информацию. Теоретически RNN могут использовать информацию в произвольно длинных последовательностях, но на практике они ограничены лишь несколькими шагами (подробнее об этом позже).
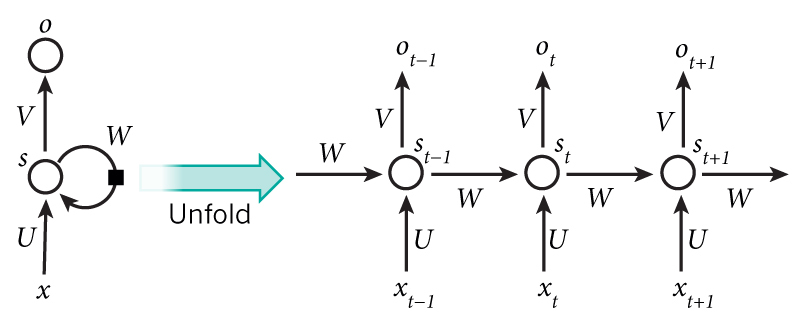 Рекуррентная нейронная сеть и ее развертка (unfolding)
Рекуррентная нейронная сеть и ее развертка (unfolding)
На диаграмме выше показано, что RNN разворачивается в полную сеть. Разверткой мы просто выписываем сеть для полной последовательности. Например, если последовательность представляет собой предложение из 5 слов, развертка будет состоять из 5 слоев, по слою на каждое слово. Формулы, задающие вычисления в RNN следующие:
Где используют рекуррентные нейросети?
Рекуррентные нейронные сети продемонстрировали большой успех во многих задачах NLP. На этом этапе нужно упомянуть, что наиболее часто используемым типом RNN являются LSTM, которые намного лучше захватывают (хранят) долгосрочные зависимости, чем RNN. Но не волнуйтесь, LSTM — это, по сути, то же самое, что и RNN, которые мы разберем в этом уроке, у них просто есть другой способ вычисления скрытого состояния. Более подробно мы рассмотрим LSTM в другом посте. Вот некоторые примеры приложений RNN в NLP (без ссылок на исчерпывающий список).
Языковое моделирование и генерация текстов
Учитывая последовательность слов, мы хотим предсказать вероятность каждого слова (в словаре). Языковые модели позволяют нам измерить вероятность выбора, что является важным вкладом в машинный перевод (поскольку предложения с большой вероятностью правильны). Побочным эффектом такой способности является возможность генерировать новые тексты путем выбора из выходных вероятностей. Мы можем генерировать и другие вещи, в зависимости от того, что из себя представляют наши данные. В языковом моделировании наш вход обычно представляет последовательность слов (например, закодированных как вектор с одним горячим состоянием (one-hot)), а выход — последовательность предсказанных слов. При обучении нейронной сети, мы подаем на вход следующему слою предыдущий выход o_t=x_
Исследования по языковому моделированию и генерации текста:
Машинный перевод
Машинный перевод похож на языковое моделирование, поскольку вектор входных параметров представляет собой последовательность слов на исходном языке (например, на немецком). Мы хотим получить последовательность слов на целевом языке (например, на английском). Ключевое различие заключается в том, что мы получим эту последовательность только после того, как увидим все входные параметры, поскольку первое слово переводимого предложения может потребовать информации всей последовательности вводимых слов.
 RNN для машинного перевода
RNN для машинного перевода
Распознавание речи
По входной последовательности акустических сигналов от звуковой волны, мы можем предсказать последовательность фонетических сегментов вместе со своими вероятностями.
Генерация описания изображений
Вместе со сверточными нейронными сетями RNN использовались как часть модели генерации описаний неразмеченных изображений. Удивительно, насколько хорошо они работают. Комбинированная модель совмещает сгенерированные слова с признаками, найденными на изображениях.
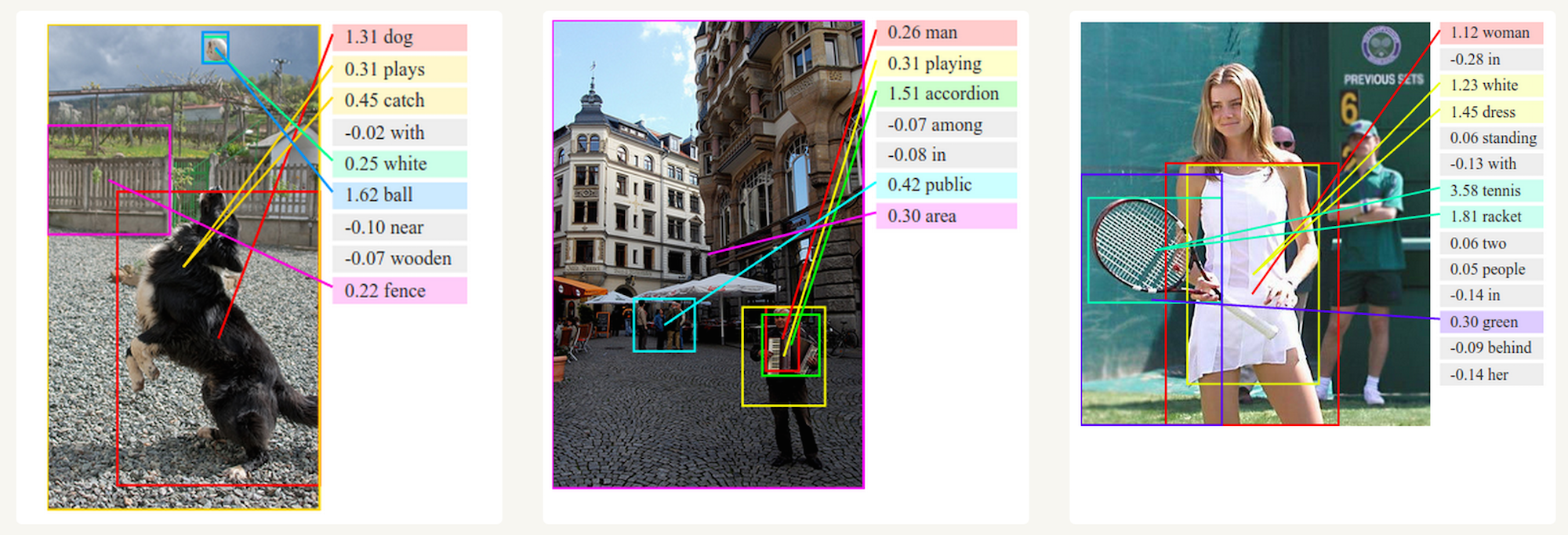 Глубокие визуально-семантические совмещения для генерации описания изображений. Источник: http://cs.stanford.edu/people/karpathy/deepimagesent/
Глубокие визуально-семантические совмещения для генерации описания изображений. Источник: http://cs.stanford.edu/people/karpathy/deepimagesent/
Обучение RNN
Обучение RNN аналогично обучению обычной нейронной сети. Мы также используем алгоритм обратного распространения ошибки (backpropagation), но с небольшим изменением. Поскольку одни и те же параметры используются на всех временных этапах в сети, градиент на каждом выходе зависит не только от расчетов текущего шага, но и от предыдущих временных шагов. Например, чтобы вычислить градиент при t = 4, нам нужно было бы «распространить ошибку» на 3 шага и суммировать градиенты. Этот алгоритм называется «алгоритмом обратного распространения ошибки сквозь время» (Backpropagation Through Time, BPTT). Если вы не видите в этом смысла, не беспокойтесь, у нас еще будет статья со всеми кровавыми подробностями. На данный момент просто помните о том, что рекуррентные нейронные сети, прошедшие обучение с BPTT, испытывают трудности с изучением долгосрочных зависимостей (например, зависимость между шагами, которые находятся далеко друг от друга) из-за затухания/взрывания градиента. Чтобы обойти эти проблемы, существует определенный механизм, были разработаны специальные архитектуры PNN (например LSTM).
Модификации RNN
На протяжении многих лет исследователи разрабатывали более сложные типы RNN, чтобы справиться с некоторыми из недостатков классической модели. Мы рассмотрим их более подробно в другой статье позже, но я хочу, чтобы этот раздел послужил кратким обзором, чтобы познакомить вас с классификацией моделей.
Двунаправленные рекуррентные нейронные сети (Bidirectional RNNs) основаны на той идее, что выход в момент времени t может зависеть не только от предыдущих элементов в последовательности, но и от будущих. Например, если вы хотите предсказать недостающее слово в последовательности, учитывая как в левый, так и в правый контекст. Двунаправленные рекуррентные нейронные сети довольно просты. Это всего лишь два RNN, уложенных друг на друга. Затем выход вычисляется на основе скрытого состояния обоих RNN. 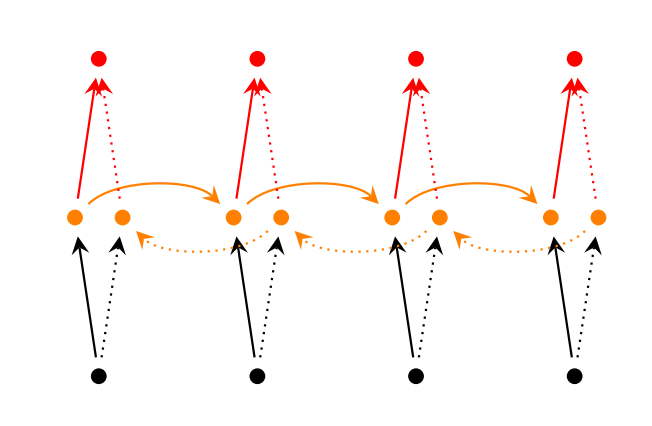
Глубинные рекуррентные нейронные сети похожи на двунаправленные RNN, только теперь у нас есть несколько уровней на каждый шаг времени. На практике это даст более высокий потенциал, но нам также потребуется много данных для обучения.
Сети LSTM довольно популярны в наши дни, мы кратко говорили о них выше. LSTM не имеют принципиально отличающейся архитектуры от RNN, но они используют другую функцию для вычисления скрытого состояния. Память в LSTM называется ячейками, и вы можете рассматривать их как черные ящики, которые принимают в качестве входных данных предыдущее состояние h_
Введение в RNN Рекуррентные Нейронные Сети для начинающих
Введение в RNN Рекуррентные Нейронные Сети для начинающих
Рекуррентные нейронные сети (RNN) — это тип нейронных сетей, которые специализируются на обработке последовательностей. Зачастую их используют в таких задачах, как обработка естественного языка (Natural Language Processing) из-за их эффективности в анализе текста. В данной статье мы наглядно рассмотрим рекуррентные нейронные сети, поймем принцип их работы, а также создадим одну сеть в Python, используя numpy.
Зачем нужны рекуррентные нейронные сети
Один из нюансов работы с нейронными сетями (а также CNN) заключается в том, что они работают с предварительно заданными параметрами. Они принимают входные данные с фиксированными размерами и выводят результат, который также является фиксированным. Плюс рекуррентных нейронных сетей, или RNN, в том, что они обеспечивают последовательности с вариативными длинами как для входа, так и для вывода. Вот несколько примеров того, как может выглядеть рекуррентная нейронная сеть:
Способность обрабатывать последовательности делает рекуррентные нейронные сети RNN весьма полезными. Области использования:
Далее в статье будет показан пример создания рекуррентной нейронной сети по схеме «многие к одному» для анализа настроений.
Создание рекуррентной нейронной сети на примере
Представим, что у нас есть нейронная сеть, которая работает по принципу «многое ко многим«. Входные данные — x 0, х 1, … x n, а результаты вывода — y 0, y 1, … y n. Данные x i и y i являются векторами и могут быть произвольных размеров.
Вот что делает нейронную сеть рекуррентной: на каждом шаге она использует один и тот же вес. Говоря точнее, типичная классическая рекуррентная нейронная сеть использует только три набора параметров веса для выполнения требуемых подсчетов:
Для рекуррентной нейронной сети мы также используем два смещения:
Вес будет представлен как матрица, а смещение как вектор. В данном случае рекуррентная нейронная сеть состоит их трех параметров веса и двух смещений.
Следующие уравнения являются компактным представлением всего вышесказанного:
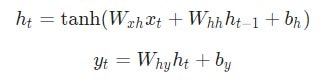 Разбор уравнений лучше не пропускать. Остановитесь на минутку и изучите их внимательно. Помните, что вес — это матрица, а другие переменные являются векторами.
Разбор уравнений лучше не пропускать. Остановитесь на минутку и изучите их внимательно. Помните, что вес — это матрица, а другие переменные являются векторами.
Говоря о весе, мы используем матричное умножение, после чего векторы вносятся в конечный результат. Затем применяется гиперболическая функция в качестве функции активации первого уравнения. Стоит иметь в виду, что другие методы активации, например, сигмоиду, также можно использовать.
Поставление задачи для рекуррентной нейронной сети
К текущему моменту мы смогли реализовать рекуррентную нейронную сеть RNN с нуля. Она должна выполнить простой анализ настроения. В дальнейшем примере мы попросим сеть определить, будет заданная строка нести позитивный или негативный характер.
Вот несколько примеров из небольшого набора данных, который был собран для данной статьи:
| Текст | Позитивный? |
| Я хороший | Да |
| Я плохой | Нет |
| Это очень хорошо | Да |
| Это неплохо | Да |
| Я плохой, а не хороший | Нет |
| Я несчастен | Нет |
| Это было хорошо | Да |
| Я чувствую себя неплохо, мне не грустно | Да |
Составление плана для нейронной сети
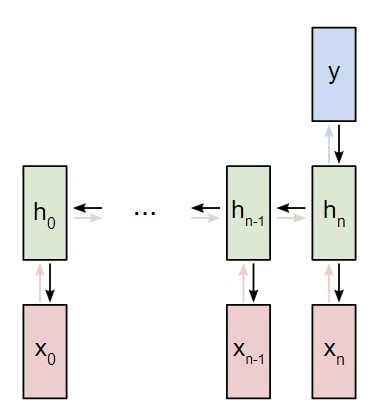
В следующем примере будет использована классификация рекуррентной сети «многие к одному». Принцип ее использования напоминает работу схемы «многие ко многим», что была описана ранее. Однако на этот раз будет задействовано только скрытое состояние для одного пункта вывода y :
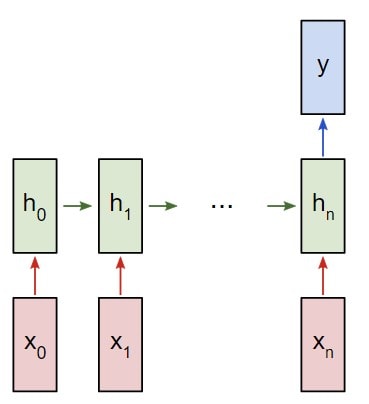 Рекуррентная нейронная сеть RNN многие к одному
Рекуррентная нейронная сеть RNN многие к одному
Каждый x i будет вектором, представляющим определенное слово из текста. Вывод y будет вектором, содержащим два числа. Одно представляет позитивное настроение, а второе — негативное. Мы используем функцию Softmax, чтобы превратить эти значения в вероятности, и в конечном счете выберем между позитивным и негативным.
Приступим к созданию нашей рекуррентной нейронной сети.
Предварительная обработка рекуррентной нейронной сети RNN
Упомянутый ранее набор данных состоит из двух словарей Python:
True = Позитивное, False = Негативное
Для получения данных в удобном формате потребуется сделать определенную предварительную обработку. Для начала необходимо создать словарь в Python из всех слов, которые употребляются в наборе данных:
vocab теперь содержит список всех слов, которые употребляются как минимум в одном учебном тексте. Далее присвоим каждому слову из vocab индекс типа integer (целое число).
Теперь можно отобразить любое заданное слово при помощи индекса целого числа. Это очень важный пункт, так как:
Напоследок напомним, что каждый ввод x i для рассматриваемой рекуррентной нейронной сети является вектором. Мы будем использовать веторы, которые представлены в виде унитарного кода. Единица в каждом векторе будет находиться в соответствующем целочисленном индексе слова.
Так как в словаре 18 уникальных слов, каждый x i будет 18-мерным унитарным вектором.
Напоследок напомним, что каждый ввод x i для рассматриваемой рекуррентной нейронной сети является вектором. Мы будем использовать веторы, которые представлены в виде унитарного кода. Единица в каждом векторе будет находиться в соответствующем целочисленном индексе слова.
Так как в словаре 18 уникальных слов, каждый x i будет 18-мерным унитарным вектором.
Мы используем createInputs() позже для создания входных данных в виде векторов и последующей их передачи в рекуррентную нейронную сеть RNN.
Фаза прямого распространения нейронной сети
Пришло время для создания рекуррентной нейронной сети. Начнем инициализацию с тремя параметрами веса и двумя смещениями.
Обратите внимание: для того, чтобы убрать внутреннюю вариативность весов, мы делим на 1000. Это не самый лучший способ инициализации весов, но он довольно простой, подойдет для новичков и неплохо работает для данного примера.
Для инициализации веса из стандартного нормального распределения мы используем np.random.randn().
Затем мы реализуем прямую передачу рассматриваемой нейронной сети. Помните первые два уравнения, рассматриваемые ранее?
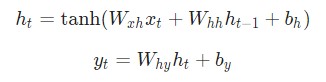
Эти же уравнения, реализованные в коде:
Давайте попробуем следующее:
Наша рекуррентная нейронная сеть работает, однако ее с трудом можно назвать полезной. Давайте исправим этот недочет.
Фаза обратного распространения нейронной сети
Для тренировки рекуррентной нейронной сети будет использована функция потери. Здесь будет использована потеря перекрестной энтропии, которая в большинстве случаев совместима с функцией Softmax. Формула для подсчета:

Здесь p c является предсказуемой вероятностью рекуррентной нейронной сети для класса correct (позитивный или негативный). Например, если позитивный текст предсказывается рекуррентной нейронной сетью как позитивный текст на 90%, то потеря составит:
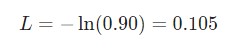
При наличии параметров потери можно натренировать нейронную сеть таким образом, чтобы она использовала градиентный спуск для минимизации потерь. Следовательно, здесь понадобятся градиенты.
Оригиналы всех кодов, которые использованы в данной инструкции, доступны на GitHub.
Параметры рассматриваемой нейронной сети
Параметры данных, которые будут использованы в дальнейшем:
Установка
Следующим шагом будет настройка фазы прямого распространения. Это необходимо для кеширования отдельных данных, которые будут использоваться в фазе обратного распространения нейронной сети. Параллельно с этим можно будет установить основной скелет для фазы обратного распространения. Это будет выглядеть следующим образом:
Градиенты
Настало время математики! Начнем с вычисления 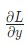 . Что нам известно:
. Что нам известно:
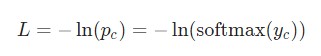
Здесь используется фактическое значение , а также применяется дифференцирование сложной функции. Результат следующий:
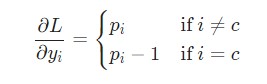
Отлично. Теперь разберемся с градиентами для W hy и b y, которые используются только для перехода конечного скрытого состояния в результат вывода рассматриваемой нейронной сети RNN. Используем следующие данные:
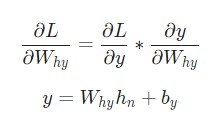
Здесь h n является конечным скрытым состоянием. Таким образом:

Аналогичным способом вычисляем:
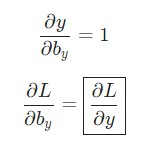
Наконец, нам понадобятся градиенты для W hh, W xh, и b h, которые использовались в каждом шаге нейронной сети. У нас есть:
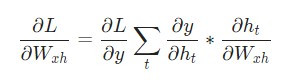
 Обратное распространение во времени
Обратное распространение во времени
W xh используется для всех прямых ссылок x t → h t, поэтому нам нужно провести обратное распространение назад к каждой из этих ссылок.
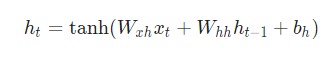
Производная гиперболической функции tanh нам уже известна:
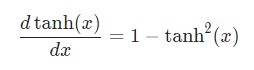
Используем дифференцирование сложной функции, или цепное правило:
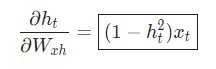
Аналогичным способом вычисляем:
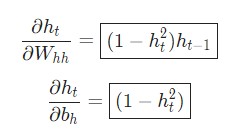
Последнее нужное значение — . Его можно подсчитать рекурсивно:
. Его можно подсчитать рекурсивно:

Реализуем обратное распространение во времени, или BPTT, отталкиваясь от скрытого состояния в качестве начальной точки. Далее будем работать в обратном порядке. Поэтому на момент подсчета значение 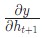 будет известно. Исключением станет только последнее скрытое состояние h n:
будет известно. Исключением станет только последнее скрытое состояние h n:
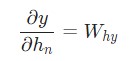
Теперь у нас есть все необходимое, чтобы наконец реализовать обратное распространение во времени ВРТТ и закончить backprop() :
Моменты, на которые стоит обратить внимание:
Мы сделали это! Наша рекуррентная нейронная сеть готова.
Тестирование рекуррентной нейронной сети
Наконец настал тот момент, которого мы так долго ждали — протестируем готовую рекуррентную нейронную сеть.
Для начала, напишем вспомогательную функцию для обработки данных рассматриваемой рекуррентной нейронной сети:
Теперь можно написать цикл для тренировки сети:
Результат вывода main.py выглядит следующим образом:
Неплохо для рекуррентной нейронной сети, которую мы построили сами!
Хотите поэкспериментировать с этим кодом сами? Можете запустить данную рекуррентную нейронную сеть RNN у себя в браузере. Она также доступна на GitHub.
Подведем итоги
Вот и все, пошаговое руководство по рекуррентным нейронным сетям на этом закончено. Мы узнали, что такое RNN, как они работают, почему они полезны, как их создавать и тренировать. Это очень малый аспект мира нейронных сетей. При желании вы можете продолжить изучение темы самостоятельно, используя следующие ресурсы: