Распределённые СУБД для энтерпрайза
CAP-теорема является краеугольным камнем теории распределённых систем. Конечно, споры вокруг неё не утихают: и определения в ней не канонические, и строгого доказательства нет… Тем не менее, твёрдо стоя на позициях бытового здравого смысла™, мы интуитивно понимаем, что теорема верна.

Единственное, что не очевидно, так это значение буквы «P». Когда кластер разделился, он решает – то ли не отвечать, пока не будет набран кворум, то ли отдавать те данные, которые есть. В зависимости от результатов этого выбора система классифицируется либо как CP, либо как AP. Cassandra, например, может вести себя и так и так, в зависимости даже не от настроек кластера, а от параметров каждого конкретного запроса. Но если система не «P», и она разделилась, тогда – что?
Ответ на этот вопрос несколько неожиданный: CA-кластер не может разделиться.
Что же это за кластер, который не может разделиться?
Непременный атрибут такого кластера – общая система хранения данных. В подавляющем большинстве случаев это означает подключение через SAN, что ограничивает применение CA-решений крупными предприятиями, способными содержать SAN-инфраструктуру. Для того, чтобы несколько серверов могли работать с одними и теми же данными, необходима кластерная файловая система. Такие файловые системы есть в портфелях HPE (CFS), Veritas (VxCFS) и IBM (GPFS).
Oracle RAC
Опция Real Application Cluster впервые появилась в 2001 году в релизе Oracle 9i. В таком кластере что несколько экземпляров сервера работают с одной и той же базой данных.
Oracle может работать как с кластерной файловой системой, так и с собственным решением – ASM, Automatic Storage Management.
Каждый экземпляр ведёт свой журнал. Транзакция выполняется и фиксируется одним экземпляром. В случае сбоя экземпляра один из выживших узлов кластера (экземпляров) считывает его журнал и восстанавливают потерянные данные – за счёт этого обеспечивается доступность.
Все экземпляры поддерживают собственный кэш, и одни и те же страницы (блоки) могут находиться одновременно в кэшах нескольких экземпляров. Более того, если какая-то страница нужна одному экземпляру, и она есть в кэше другого экземпляра, он может получить его у «соседа» при помощи механизма cache fusion вместо того, чтобы читать с диска.
Но что произойдёт, если одному из экземпляров потребуется изменить данные?
Особенность Oracle в том, что у него нет выделенного сервиса блокировок: если сервер хочет заблокировать строку, то запись о блокировке ставится прямо на той странице памяти, где находится блокируемая строка. Благодаря такому подходу Oracle – чемпион по производительности среди монолитных баз: сервис блокировок никогда не становится узким местом. Но в кластерной конфигурации такая архитектура может приводить к интенсивному сетевому обмену и взаимным блокировкам.
Как только запись блокируется, экземпляр оповещает все остальные экземпляры о том, что страница, в которой хранится эта запись, захвачена в монопольном режиме. Если другому экземпляру понадобится изменить запись на той же странице, он должен ждать, пока изменения на странице не будут зафиксированы, т. е. информация об изменении не будет записана в журнал на диске (при этом транзакция может продолжаться). Может случиться и так, что страница будет изменена последовательно несколькими экземплярами, и тогда при записи страницы на диск придётся выяснять, у кого же хранится актуальная версия этой страницы.
Случайное обновление одних и тех же страниц через разные узлы RAC приводит к резкому снижению производительности базы данных – вплоть до того, что производительность кластера может быть ниже, чем производительность единственного экземпляра.
Правильное использование Oracle RAC – физическое деление данных (например, при помощи механизма секционированных таблиц) и обращение к каждому набору секций через выделенный узел. Главным назначением RAC стало не горизонтальное масштабирование, а обеспечение отказоустойчивости.
Если узел перестаёт отвечать на heartbeat, то тот узел, который обнаружил это первым, запускает процедуру голосования на диске. Если и здесь пропавший узел не отметился, то один из узлов берёт на себя обязанности по восстановлению данных:
IBM Pure Data Systems for Transactions
Кластерное решение для СУБД появилось в портфеле Голубого Гиганта в 2009 году. Идеологически оно является наследником кластера Parallel Sysplex, построенным на «обычном» оборудовании. В 2009 году вышел продукт DB2 pureScale, представляющий собой комплект программного обеспечения, а в 2012 года IBM предлагает программно-аппаратный комплект (appliance) под названием Pure Data Systems for Transactions. Не следует путать его с Pure Data Systems for Analytics, которая есть не что иное, как переименованная Netezza.
Архитектура pureScale на первый взгляд похожа на Oracle RAC: точно так же несколько узлов подключены к общей системе хранения данных, и на каждом узле работает свой экземпляр СУБД со своими областями памяти и журналами транзакций. Но, в отличие от Oracle, в DB2 есть выделенный сервис блокировок, представленный набором процессов db2LLM*. В кластерной конфигурации этот сервис выносится на отдельный узел, который в Parallel Sysplex называется coupling facility (CF), а в Pure Data – PowerHA.
PowerHA предоставляет следующие сервисы:
Если узлу нужна страница, и этой страницы нет в кэше, то узел запрашивает страницу в глобальном кэше, и только в том случае, если и там её нет, читает её с диска. В отличие от Oracle, запрос идёт только в PowerHA, а не в соседние узлы.
Если экземпляр собирается менять строку, он блокирует её в эксклюзивном режиме, а страницу, где находится строка, – в разделяемом режиме. Все блокировки регистрируются в глобальном менеджере блокировок. Когда транзакция завершается, узел посылает сообщение менеджеру блокировок, который копирует изменённую страницу в глобальный кэш, снимает блокировки и инвалидирует изменённую страницу в кэшах других узлов.
Если страница, в которой находится изменяемая строка, уже заблокирована, то менеджер блокировок прочитает изменённую страницу из памяти узла, сделавшего изменения, снимет блокировку, инвалидирует изменённую страницу в кэшах других узлов и отдаст блокировку страницы узлу, который её запросил.
«Грязные», то есть изменённые, страницы могут быть записаны на диск как с обычного узла, так и с PowerHA (castout).
При отказе одного из узлов pureScale восстановление ограничено только теми транзакциями, которые в момент сбоя ещё не были завершены: страницы, изменённые этим узлом в завершившихся транзакциях, есть в глобальном кэше на PowerHA. Узел перезапускается в урезанной конфигурации на одном из серверов кластера, откатывает незавершённые транзакции и освобождает блокировки.
PowerHA работает на двух серверах, и основной узел синхронно реплицирует своё состояние. При отказе основного узла PowerHA кластер продолжает работу с резервным узлом.
Разумеется, если обращаться к набору данных через один узел, общая производительность кластера будет выше. PureScale даже может заметить, что некоторая область данных обрабатываются одним узлом, и тогда все блокировки, относящиеся к этой области, будут обрабатываться узлом локально без коммуникаций с PowerHA. Но как только приложение попытается обратиться к этим данным через другой узел, централизованная обработка блокировок будет возобновлена.
Внутренние тесты IBM на нагрузке, состоящей из 90% чтения и 10% записи, что очень похоже на реальную промышленную нагрузку, показывают почти линейное масштабирование до 128 узлов. Условия тестирования, увы, не раскрываются.
HPE NonStop SQL
Своя высокодоступная платформа есть и в портфеле Hewlett-Packard Enterprise. Это платформа NonStop, выпущенная на рынок в 1976 году компанией Tandem Computers. В 1997 году компания была поглощена компанией Compaq, которая, в свою очередь, в 2002 году влилась в Hewlett-Packard.
NonStop используется для построения критичных приложений – например, HLR или процессинга банковских карт. Платформа поставляется в виде программно-аппаратного комплекса (appliance), включающего в себя вычислительные узлы, систему хранения данных и коммуникационное оборудование. Сеть ServerNet (в современных системах – Infiniband) служит как для обмена между узлами, так и для доступа к системе хранения данных.
В ранних версиях системы использовались проприетарные процессоры, которые были синхронизированы друг с другом: все операции исполнялись синхронно несколькими процессорами, и как только один из процессоров ошибался, он отключался, а второй продолжал работу. Позднее система перешла на обычные процессоры (сначала MIPS, затем Itanium и, наконец, x86), а для синхронизации стали использоваться другие механизмы:
Вся база данных делится на части, и за каждую часть отвечает свой процесс Data Access Manager (DAM). Он обеспечивает запись данных, кэшировние и механизм блокировок. Обработкой данных занимаются процессы-исполнители (Executor Server Process), работающие на тех же узлах, что и соответствующие менеджеры данных. Планировщик SQL/MX делит задачи между исполнителями и объединяет результаты. При необходимости внести согласованные изменения используется протокол двухфазной фиксации, обеспечиваемый библиотекой TMF (Transaction Management Facility).
NonStop SQL умеет приоритезировать процессы так, чтобы длинные аналитические запросы не мешали исполнению транзакций. Однако её назначение – именно обработка коротких транзакций, а не аналитика. Разработчик гарантирует доступность кластера NonStop на уровне пять «девяток», то есть простой составляет всего 5 минут в год.
SAP HANA
Первый стабильный релиз СУБД HANA (1.0) состоялся в ноябре 2010 года, а пакет SAP ERP перешёл на HANA с мая 2013 года. Платформа базируется на купленных технологиях: TREX Search Engine (поиска в колоночном хранилище), СУБД P*TIME и MAX DB.
Само слово «HANA» – акроним, High performance ANalytical Appliance. Поставляется эта СУБД в виде кода, который может работать на любых серверах x86, однако промышленные инсталляции допускаются только на оборудовании, прошедшем сертификацию. Имеются решения HP, Lenovo, Cisco, Dell, Fujitsu, Hitachi, NEC. Некоторые конфигурации Lenovo допускают даже эксплуатацию без SAN – роль общей СХД играет кластер GPFS на локальных дисках.
В отличие от перечисленных выше платформ, HANA – СУБД в памяти, т. е. первичный образ данных хранится в оперативной памяти, а на диск записываются только журналы и периодические снимки – для восстановления в случае аварии.
Каждый узел кластера HANA отвечает за свою часть данных, а карта данных хранится в специальном компоненте – Name Server, расположенном на узле-координаторе. Данные между узлами не дублируются. Информация о блокировках также хранится на каждом узле, но в системе есть глобальный детектор взаимных блокировок.
Клиент HANA при соединении с кластером загружает его топологию и в дальнейшем может обращаться напрямую к любому узлу в зависимости от того, какие данные ему нужны. Если транзакция затрагивает данные единственного узла, то она может быть выполнена этим узлом локально, но если изменяются данные нескольких узлов, то узел-инициатор обращается к узлу-координатору, который открывает и координирует распределённую транзакцию, фиксируя её при помощи оптимизированного протокола двухфазной фиксации.
Узел-координатор дублирован, поэтому в случае выхода координатора из строя в работу немедленно вступает резервный узел. А вот если выходит из строя узел с данными, то единственный способ получить доступ к его данным – перезапустить узел. Как правило, в кластерах HANA держат резервный (spare) сервер, чтобы как можно быстрее перезапустить на нём потерянный узел.
Направления развития баз данных
14.2. Распределенные базы данных
База данных – интегрированная совокупность данных, с которой работают много пользователей. Изложение всех предыдущих разделов предполагало единую базу данных, размещаемую на одном компьютере. Напомним основные принципы, положенные в основу теории баз данных:
Заметим, что базы данных появились в период господства больших ЭВМ. База данных велась на одной ЭВМ, все пользователи работали именно на ЭВМ (возможные режимы работы описаны в «Различные архитектурные решения, используемые при реализации многопользовательских СУБД. Краткий обзор СУБД» ). Других вариантов использования вычислительной техники в то время просто не существовало. Если проанализировать работу пользователей с данными в компаниях, организациях, предприятиях в «докомпьютерное» время, то нетрудно заметить, что на отдельных участках пользователи работали со «своими» данными (осуществляли сбор определенных данных, их хранение, обработку, передачу обработанных данных на другие участки или уровни управления).
Развитие вычислительных компьютерных сетей обусловило новые возможности в организации и ведении баз данных, позволяющие каждому пользователю иметь на своем компьютере свои данные и работать с ними и в то же время позволяющие работать всем пользователям со всей совокупностью данных как с единой централизованной базой данных. Соответствующая совокупность данных называется распределенной базой данных.
Распределенная база данных – совокупность логически взаимосвязанных разделяемых данных (и описаний их структур), физически распределенных в компьютерной сети.
Система управления распределенной базой данных – программная система, обеспечивающая работу с распределенной базой данных и позволяющая пользователю работать как с его локальными данными, так и со всей базой данных в целом.
Объединение данных организуется виртуально. Соответствующий подход, по сути, отражает организационную структуру предприятия (и даже общества в целом), состоящего из отдельных подразделений. Причем, хотя каждое подразделение обрабатывает свой набор данных (эти наборы, как правило, пересекаются), существует необходимость доступа к этим данным как к единому целому (в частности, для управления всем предприятием).
Одним из примеров реализации такой модели может служить сеть Интернет : данные вводятся и хранятся на разных компьютерах по всему миру, любой пользователь может получить доступ к этим данным, не задумываясь о том, где они физически расположены.
К.Дж. Дейт провозглашает следующий фундаментальный принцип распределенной базы данных [ [ 2.1 ] ]. Для пользователя распределенная система должна выглядеть точно так же, как нераспределенная. Из этого принципа следует ряд правил:
Заметим, что понятие распределенной базы данных можно интерпретировать как следующий шаг в развитии понятий о данных (см. «Введение в базы данных. Общая характеристика основных понятий» ), обусловленный распределенностью данных в реальных предметных областях, а также новым этапом развития средств вычислительной техники – широким использованием вычислительных сетей.
В этой интерпретации распределенную базу данных можно понимать как совокупность логически взаимосвязанных распределенных по разным компьютерам баз данных.
Поэтому очевидно, что задача проектирования, создания и функционирования распределенных баз данных является весьма существенной, активно изучается в настоящее время и будет решаться и далее.

Краткое описание: Распределенные базы данных
§ 1 Распределенные базы данных
 1.1 Введение
1.1 Введение
1.2 Основные понятия
1.3 Распределенная обработка
1.4 Параллельные СУБД
1.5 Преимущества и недостатки распределенных СУБД
§ 1.5.1 Обзорная таблица
1.6 Однородные и разнородные распределенные СУБД
1.7 Правила Дейта для распределенных СУБД
Появление вычислительных систем с базами данных привело к смене прежних способов обработки данных, в которых для каждого приложения определялись и поддерживались собственные наборы данных, новыми, в которых все данные определялись и поддерживались централизованно. А в последнее время происходит быстрое развитие технологий сетевой связи и обмена данными, вызванное созданием Internet, появлением мобильных и беспроводных вычислительных средств, а также «интеллектуальных» устройств. Теперь под влиянием этих двух противоположных тенденций технология распределенных баз данных способствует обратному переходу от централизованной обработки данных к децентрализованной. Создание технологии систем управления распределенными базами данных является одним из самых больших достижений в области баз данных.
В основном мы рассматривали централизованные системы баз данных, т. е. системы, в которых единственная логическая база данных размещалась в пределах одного узла и находилась под управлением одной СУБД. Теперь обсудим принципы и проблемы, связанные с распределенными СУБД, позволяющими конечным пользователям иметь доступ не только к данным, сохраняемым на их собственном узле, но и к данным, размещенным на различных удаленных узлах. В прессе уже неоднократно делались заявления о том, что в связи с нарастающим процессом перехода организаций к технологии распределенных баз данных централизованные базы данных буквально через несколько лет превратятся в антикварную редкость.
Основной предпосылкой разработки систем, использующих базы данных, является стремление объединить все обрабатываемые в организации данные в единое целое и обеспечить к ним контролируемый доступ. Хотя интеграция и предоставление контролируемого доступа могут способствовать централизации, последняя не является самоцелью. На практике создание компьютерных сетей приводит к децентрализации обработки данных. Децентрализованный подход, по сути, отражает организационную структуру многих компаний, логически состоящих из отдельных подразделений, отделов, проектных групп и т. п., которые физически распределены по разным офисам, отделениям, предприятиям или филиалам, причем каждая отдельная производственная единица имеет дело с собственным набором обрабатываемых данных. Разработка распределенных баз данных, отражающих организационные структуры предприятий, позволяет сделать общедоступными данные, поддерживаемые каждым из существующих подразделений, обеспечив при этом их хранение именно в тех местах, где они чаще всего используются. Подобный подход расширяет возможности совместного использования информации, одновременно повышая эффективность доступа к ней.
Распределенные системы призваны решить проблему информационных островов. Если на предприятии имеется несколько баз данных, их иногда рассматривают как некие разрозненные территории, представляющие собой отдельные и труднодоступные для многих места, подобные удаленным друг от друга островам. Данное положение может являться следствием географической разобщенности, несовместимости используемой компьютерной архитектуры, несовместимости используемых протоколов связи и т. д. Подобное положение дел способна изменить интеграция отдельных баз данных в одно логическое целое.
Чтобы начать обсуждение проблем, связанных с распределенными СУБД, прежде всего необходимо уяснить, что же такое распределенная база данных.
Распределенная база данных: Набор логически связанных между собой совокупностей разделяемых данных (и их описаний), которые физически распределены в некоторой компьютерной сети.
Из этого вытекает следующее определение распределенной СУБД:
Распределенная СУБД: Программный комплекс, предназначенный для управления распределенными базами данных и обеспечивающий прозрачный доступ пользователей к распределенной информации.
Распределенная система управления базой данных (распределенная СУБД) состоит из единой логической базы данных, разделенной на некоторое количество фрагментов. Каждый фрагмент базы данных сохраняется на одном или нескольких компьютерах, работающих под управлением отдельных СУБД и соединенных между собой сетью связи. Любой узел способен независимо обрабатывать запросы пользователей, требующие доступа к локально сохраняемым данным (т. е. каждый узел обладает определенной степенью автономности), а также способен обрабатывать данные, сохраняемые на других компьютерах сети.
Пользователи взаимодействуют с распределенной базой данных через приложения. Приложения могут подразделяться на не требующие доступа к данным на других узлах (локальные приложения) и требующие подобного доступа (глобальные приложения). В распределенной СУБД должно существовать хотя бы одно глобальное приложение, поэтому любая такая СУБД должна иметь следующие характеристики:
§ Имеется набор логически связанных разделяемых данных.
§ Сохраняемые данные разбиты на некоторое количество фрагментов.
§ Может быть предусмотрена репликация фрагментов данных.
§ Фрагменты и их копии распределяются по разным узлам.
§ Узлы связаны между собой сетевыми соединениями.
§ Доступ к данным на каждом узле происходит под управлением СУБД.
§ СУБД на каждом узле способна поддерживать автономную работу локальных приложений.
§ СУБД каждого узла поддерживает хотя бы одно глобальное приложение.
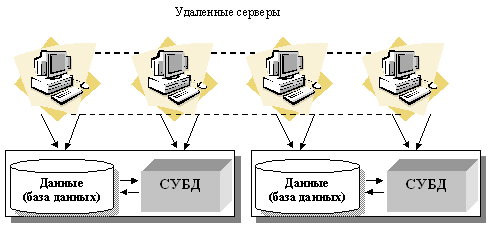
Но нет необходимости в том, чтобы на каждом из узлов системы существовала своя собственная локальная база данных, что и показано на примере топологии распределенной СУБД, представленной на рисунке:


Топология распределенной СУБД
Из определения СУБД следует, что она должна сделать само это распределение данных прозрачным (незаметным) для конечного пользователя. Другими словами, от пользователей должен быть полностью скрыт тот факт, что распределенная база данных состоит из нескольких фрагментов, которые могут размещаться на различных компьютерах и для которых, возможно, даже организована репликация данных. Цель обеспечения прозрачности состоит в том, чтобы распределенная система внешне выглядела как централизованная. Иногда это требование называют основным принципом создания распределенных СУБД. Данный принцип требует предоставления конечному пользователю широкого набора функциональных возможностей, но, к сожалению, одновременно ставит перед программным обеспечением распределенной СУБД множество дополнительных задач.
Очень важно понимать различия между распределенными СУБД и средствами распределенной обработки данных.
Распределенная обработка: Обработка с использованием централизованной базы данных, доступ к которой может осуществляться с различных компьютеров сети.
Ключевым моментом в определении распределенной СУБД является утверждение, что система работает с данными, физически распределенными в сети. Бели данные хранятся централизованно, то даже в том случае, когда доступ к ним обеспечивается для любого пользователя по сети, эта система просто поддерживает распределенную обработку, но не может рассматриваться как распределенная СУБД. Схематически подобная топология распределенной обработки представлена на рисунке. Сравните этот вариант, содержащий центральную базу данных на узле 2, с вариантом, представленным на предыдущем рисунке, в котором присутствует несколько узлов, каждый из которых имеет собственную базу данных:

Топология системы с распределенной обработкой
Кроме того, следует четко понимать различия, существующие между распределенными и параллельными СУБД.
Параллельная СУБД: Система управления базой данных, функционирующей с использованием нескольких процессоров и жестких дисков, что позволяет ей (если это возможно) распараллеливать выполнение некоторых операций с целью повышения общей производительности обработки.
Появление параллельных СУБД было вызвано тем фактом, что системы с одним процессором оказались не способны удовлетворять растущие требования к масштабируемости, надежности и производительности обработки данных. Эффективной и экономически обоснованной альтернативой однопроцессорным СУБД стали параллельные СУБД, функционирующие одновременно на нескольких процессорах. Применение параллельных СУБД позволяет объединить несколько маломощных машин для получения такого же уровня производительности, как и в случае одной, но более мощной машины, с дополнительным выигрышем в масштабируемости и надежности системы по сравнению с однопроцессорными СУБД.
Для предоставления нескольким процессорам совместного доступа к одной и той же базе данных параллельная СУБД должна обеспечивать управление совместным доступом к ресурсам. То, какие именно ресурсы разделяются и как это разделение реализовано на практике, непосредственно влияет на показатели производительности и масштабируемости создаваемой системы, что, в свою очередь, определяет пригодность конкретной СУБД к условиям заданной вычислительной среды и требованиям приложений. Три основных типа архитектуры параллельных СУБД представлены на рисунке ниже. К ним относятся:
§ системы с разделением памяти;
§ системы с разделением дисков;
§ системы без разделения вычислительных ресурсов.
Хотя параллельная система без разделения вычислительных ресурсов иногда рассматривается как распределенная СУБД, в такой системе распределение данных обусловлено лишь стремлением к повышению производительности. Более того, узлы распределенной СУБД обычно разделены географически, находятся под управлением разных администраторов и соединены между собой относительно медленными сетевыми соединениями, тогда как узлы параллельной СУБД чаще всего располагаются на одном и том же компьютере или в пределах одной и той же производственной площадки.
Системы с разделением памяти состоят из тесно связанных между собой компонентов, в число которых входит несколько процессоров, разделяющих общую системную память. Эта архитектура, называемая также архитектурой с симметричной многопроцессорной обработкой (SMP), в настоящее время получила широкое распространение и применяется для самых разных вычислительных платформ, от персональных рабочих станций, содержащих несколько параллельно работающих микропроцессоров, больших RISC-систем и вплоть до крупнейших мэйнфреймов. Эта архитектура обеспечивает быстрый доступ к данным для ограниченного набора процессоров, количество которых обычно не превосходит 64. В противном случае взаимодействие по сети становится узким местом всей системы.
Системы с разделением дисков создаются из менее тесно связанных между собой компонентов. Они являются оптимальным вариантом для приложений, которые унаследовали высокую централизацию обработки и должны обеспечивать самые высокие показатели доступности и производительности. Каждый из процессоров имеет непосредственный доступ ко всем совместно используемым дисковым устройствам, но обладает собственной оперативной памятью. Как и в случае архитектуры без разделения вычислительных ресурсов, архитектура с разделением дисков исключает узкие места, связанные с совместно используемой памятью. Однако, в отличие от архитектуры без разделения вычислительных ресурсов, данная архитектура исключает упомянутые узкие места без внесения дополнительных издержек, связанных с физическим распределением данных по отдельным устройствам. Разделяемые дисковые системы иногда называют кластерами.

Архитектура систем баз данных с параллельной обработкой: а) с разделением памяти; б) с разделением дисков; в) без разделения
Системы без разделения вычислительных ресурсов (эту архитектуру иначе называют архитектурой с массовой параллельной обработкой) используют схему, в которой каждый процессор, являющийся частью системы, имеет свою собственную оперативную и дисковую память. База данных распределена между всеми дисковыми устройствами, подключенным к отдельным, связанным с этой базой данных вычислительным подсистемам, в результате чего все данные прозрачно доступны пользователям каждой из этих подсистем. Такая архитектура обеспечивает более высокий уровень масштабируемости, чем системы с разделяемой памятью, и позволяет легко поддерживать большое количество процессоров. Однако оптимальной производительности удается достичь только в том случае, если требуемые данные хранятся локально.
Параллельные технологии обычно используются в случае исключительно больших баз данных, размеры которых могут достигать нескольких терабайтов (  байт), или в системах, обеспечивающих выполнение тысяч транзакций в секунду. Подобные системы нуждаются в доступе к большому объему данных и должны обеспечивать приемлемое время реакции на запрос. Параллельные СУБД могут использовать различные вспомогательные технологии, позволяющие повысить производительность обработки сложных запросов за счет применения методов распараллеливания операций просмотра, соединения и сортировки, что позволяет нескольким процессорным узлам автоматически распределять между собой текущую нагрузку. В данный момент достаточно отметить, что все крупные разработчики СУБД в настоящее время поставляют параллельные версии созданных ими машин баз данных.
байт), или в системах, обеспечивающих выполнение тысяч транзакций в секунду. Подобные системы нуждаются в доступе к большому объему данных и должны обеспечивать приемлемое время реакции на запрос. Параллельные СУБД могут использовать различные вспомогательные технологии, позволяющие повысить производительность обработки сложных запросов за счет применения методов распараллеливания операций просмотра, соединения и сортировки, что позволяет нескольким процессорным узлам автоматически распределять между собой текущую нагрузку. В данный момент достаточно отметить, что все крупные разработчики СУБД в настоящее время поставляют параллельные версии созданных ими машин баз данных.
Преимущества и недостатки распределенных СУБД
Распределенные системы баз данных имеют дополнительные преимущества перед традиционными централизованными системами баз данных, К сожалению, эта технология не лишена и некоторых недостатков. В этом разделе описаны как преимущества, так и недостатки, свойственные распределенным СУБД.