Парсинг резюме
Те кто сталкивался с задачами автоматизированного анализа резюме, представляют современное состояние дел в этой области — существующие парсеры в основном ограничиваются выделением контактных данных и ещё нескольких полей, таких как «должность» и «город».
Для сколько-нибудь осмысленного анализа этого мало. Важно не только выделить некие строки и пометить их тегами, но и определить, что за объекты кроются за ними.
Живой пример (кусок XML результата анализа резюме от одного из лидеров области Sovren):
Парсер Sovren прекрасно справился с выделением полей. Ребята не зря занимаются этим делом без малого 20 лет!
Но что дальше делать с «Ведущий специалист отдела развития информационных систем»? Как понять, что же это за должность, насколько опыт работы этого человека релевантен для той или иной вакансии?
Если ваша задача — поиск сотрудника под требования вакансии или наоборот — вакансии под опыт и пожелания кандидата, то поиск ключевых слов, сравнение bag of words дают посредственные результаты. Для объектов, которым соответствует множество возможных синонимичных наименований такой подход не сработает.
Для начала нужно нормализовать наименования, превратить «специалистов в чём-либо» в программистов, сисадминов и прочих отоларингологов.
Для этого придётся составить базу знаний, таксономию объектов. Причём специфика такова, что недостаточно описать, например только строителей — люди меняют области деятельности и в резюме строителя могут встречаться и другие, не связанные со строительством места работы.
И если таксономия будет описывать только строительство — в текстах, относящихся к другим областям деятельности, будут ложные срабатывания. В строительстве «архитектор» — это одно, а в IT — совсем другое. «Операция», «Акция», «Объект» и множество словосочетаний, содержащих эти слова — примеры неоднозначностей, которые необходимо разрешать.
Простая нормализация тоже не спасёт отца русской демократии. Фантазия людей пишущих резюме и составляющих штатные расписания не перестаёт удивлять. К сожалению для нас, разработчиков, это значит, что в общем случае из строки описывающей объект идентифицировать этот объект нельзя. То есть вы конечно можете попытаться обучить какой-нибудь классификатор, скармливая ему поле и желаемую должность.
И он даже будет работать. На «бухгалтерах», «секретарях», «программистах».
Только вот в резюме люди пишут «специалист отдела N» и понять, бухгалтер он или секретарь, можно лишь по контексту, набору выполняемых обязанностей.
Казалось бы — хорошо, учтём контекст, пусть классификатор обучается ещё и на обязанностях. Так, да не так — при определении набора обязанностей та же проблема: неоднозначность трактовки, всякие непонятные анафоры).
Мы решили применить вероятностный (байесовский) подход:
Анализируя исходный текст, для всех строк (например, «архитектор», «работа
с клиентами») мы определяем множество всех возможных трактовок
(например, для «архитектора» это будет «архитектор зданий», «архитектор программного
обеспечения» и т.д.). В результате получается набор множеств трактовок. Затем
ищем такое сочетание трактовок из всех множеств, чтобы его правдоподобность
была максимальной.
Для того, чтобы выбрать между «менеджером по работе с клиентами» и «продавцом» мы оцениваем правдоподобность сочетания этих должностей с найденными в этом месте работы навыками. При этом навыки могут таким же образом выбираться из нескольких вариантов, поэтому задача состоит в выборе наиболее правдоподобного сочетания из множества найденных в тексте объектов.
Количество объектов разных типов (навыки, должности, отрасли, города и пр.) очень большое (сотни тысяч в нашей базе знаний), поэтому пространство, которому принадлежат резюме очень-очень многомерное. Для обучения большинства machine learning алгоритмов понадобится астрономическое количество примеров.
Мы решили резать. То есть кардинально сокращать количество параметров и использовать результат обучения только там, где у нас есть достаточное количество примеров.
Для начала мы стали собирать статистику по сочетаниям кортежей признаков, например: должность-отрасль, должность-отдел, должность-навык. На основе этой статистики мы оцениваем правдоподобность новых, ещё не встречаемых ранее, сочетаний
объектов и выбираем лучшее сочетание.
В примере выше набор навыков склоняет парсер в сторону менеджера в первом случае и в сторону продавца во втором.
Использование простых счётчиков и оценки вероятности по Байесу позволяет получать хорошие результаты при небольшом количестве примеров. В нашей базе знаний сейчас около ста тысяч размеченных специалистами вакансий и резюме, и это позволяет разрешать большинство неоднозначностей для распространённых объектов.
На выходе мы получаем JSON объект, описывающий вакансию или резюме в терминах нашей базы знаний, а не в тех, которые придумал соискатель или работодатель.
Это представление можно использовать для точного поиска по параметрам, оценки («скоринга») резюме соискателя или сопоставления пар «резюме-вакансия».
Мы сделали простой интерфейс, в котором можно загрузить резюме (doc, docx, pdf (не картинкой) и другие форматы) и получить его представление в JSON. Только не забывайте про 152ФЗ! Не надо эксперементировать с резюме с реальными персональными данными 🙂
Например вот такое резюме:
Пупкин Василий Львович
г. Омск
тел +7923123321123
Ответственный и трудолюбивый менеджер по продажам.
Превращается в следующий JSON:
На мой предвзятый взгляд, результат интересный и применений ему — множество. Хотя до точности распознавания объектов, сравнимой с человеческой, ещё очень далеко. Нужно развивать базу знаний, обучать алгоритм на примерах, вводить дополнительные эвристики и, возможно, узкоспециализированные классификаторы, например для определения отраслей.
Интересно, какие методики используете или использовали бы Вы? Особенно интересно, использует ли кто-нибудь семантический подход а-ля Compreno от ABBYY?
5 способов облегчить себе жизнь с помощью парсера
Эта статья поможет тем, кому необходимо обрабатывать большой объем информации в интернете. Это может быть ваш сайт, сайт конкурентов или соцсети.
Unsplash Darwin Vegher @darwiiiin
Об использовании парсинга говорят мало. Это подтверждает статистика запросов в Яндексе. В марте 2020 года было 7521 запросов. С апреля 2018 года эта цифра выросла всего на 38%. Парсинг может быть эффективен во многих сферах. Можно обрабатывать данные веб-страниц интернет-магазинов, форумов, блогов и других интернет-ресурсов, а также файлов различных форматов. Расскажу, что такое парсер и как он может вам помочь.
Данные в сети интернет расположены на веб-сайтах и представлены для человека в виде некоторого набора графических элементов, текста, изображений. Человек осуществляет парсинг каждый день: ищет номер телефона на веб-страничке, нужное изображение, просматривает товары в интернет-магазине.
С английского языка «to parse» – разбирать, анализировать. Однако способности человека ограничены. Поиск больше нескольких десятков номеров на сайте может стать современной пыткой.
А если необходимо найти сотни и тысячи номеров, адресов страниц в соцсетях на сотнях веб-страниц по определенным условиям и запросам? Тогда знающие люди используют специальные программы – парсеры. Вручную нереально освоить такой объем информации.
Также какая-то информация может быть скрыта от глаз пользователя, но она есть в коде веб-страницы.
Специальные программы анализируют код страницы с помощью различных алгоритмов от совсем простых (которые может написать начинающий программист) до сложнейших статистических моделей с использованием теории хаоса и нейронных сетей.
Парсеры вытаскивают нужную информацию, даже если владелец информации не хотел ею делиться. На многих сайтах номера телефонов отображаются не цифрами, а картинкой. Но хороший парсер справиться с таким препятствием.
Парсинг имеет сомнительную репутацию, так как часто его используют для составления спам-баз. Вспомните, как после размещения резюме на HeadHunter, всю следующую неделю вам постоянно звонили сомнительные организации и предлагали работу. Фирмы получили ваш номер и другие данные с помощью парсера.
Зато парсинг любят маркетологи и предприниматели. Они ищут клиентов с в соцсетях, на тематических форумах, торговых площадках, анализируя страницы, хэштеги и прочие данные. Создают себе свою базу клиентов, которую могут собирать годами.
А потом можно делать рекламу не по безликим настройкам таргета, а уже по готовой базе живых людей.
Таким образом, парсер — это программа, которая анализирует данные с интернет-ресурсов и систематизирует их в файл.
Парсер может решить следующие проблемы:
В маленьком онлайн-магазине возможно описать и выставить цены нескольким десяткам или сотням товаров. Но у крупных магазинов могут быть тысячи наименований. При том, что и цены, и информация постоянно меняются.
Парсер позволит собирать описания к товарам с сайтов поставщиков и наполнять свой сайт. Он не только соберет текстовое наполнение, но и поработает с изображениями. Парсер может сразу выгружать данные на ваш сайт.
Я советую подходить с умом к такому лайфхаку. Проверяйте, адаптируйте описания. И всегда есть риск, что поисковикам не понравится неоригинальный контент, и на первые позиции ваш ресурс не попадет Уникальный контент всегда ценится выше. Используйте механизм с умом.
Для таких целей подойдет программа Elbuz.
Разработчики утверждают, что с ней вы наполните интрнет-магазин в 10 раз быстрее, чем самостоятельно.
Также справятся с задачей Дигернаут.
Парсер нужен не только, чтобы «заглядывать» в окна конкурентам. Парсер поможет оптимизировать свой сайт: найти битые ссылки, пробелы в тексте, отсутствие изображений. Сервис соотнесет информацию о наличии товара на складе и информацию на сайте. И информация будет постоянно обновляться.
Для парсинга собственного сайта или соцсетей можно обратиться к специалисту. Но не все начинающие предприниматели готовы платить за это. Тогда можно выбрать простую программу для парсинга, которая рассчитана на людей без навыков программирования.
Как правило, используют SEO-парсеры для анализа собственного сайта.
С задачей хорошо справится сервис PR-CY. Этот парсер не только проверит внутренние, внешние и технические характеристики веб-страницы, но и даст рекомендации, как исправить.
Если вам не нужен такой полный анализ, установите специальное расширение для браузера. Это самый простой вид парсеров. Например, расширение Parsers или Scraper.
У известной кладовой всех вакансий и резюме HeadHunter есть API, но пока его функционал не решает все потребности клиентов, поэтому они обращаются к парсерам. (Хоть и администрация HH против парсинга данных).
Например, нужно найти на сайте с вакансиями всех программистов младше 35 лет с высшим образованием и стажем работы более трех лет, проживающими в городе Новосибирске. И потом вытащить их ФИО и номера телефонов и сохранить это в табличку Excel.
Работодатель и соискатель смогут находить подходящие варианты без ручного поиска.
Главное, не нарушать нормальную активность, иначе ваш аккаунт могут заблокировать. Чтобы избежать блокировки, имитируйте скорость человеческой активности при работе с парсером.
Из-за политики HeadHunter работайте только с надежным парсером. Многие обращаются к программистам, которые напишут скрипт на Python и Pandas.
Или можете воспользоваться Zennoposter.
Парсинг поможет составить списки контактов с дополнительной информацией: номера телефонов, почта, адрес. Данные потенциальных клиентов бесценны для бизнеса. Можно рассылать выгодные предложения на почту, оповещать об акциях по sms, сегментировать аудиторию.
Обычно контактную информацию собирают с соцсетей. В связи с их популярностью и эффективностью таргетированной рекламы есть много специальных парсеров. Самые популярные для Instagram Zengram, Tooligram, Pepper.Ninja. Для работы с вконтакте используют TargetHunter, Церебро Таргет, Segmento Target.
Работа агентства таргетированной рекламы неизбежно сопряжена с работой в сервисах парсинга.
Если говорить о работе с таргетированной рекламой во ВКонтакте, то функционал их рекламного кабинета довольно скудный, поэтому чтобы более эффективно расходовать бюджет и показывать рекламу только нужным нам пользователям, необходимо использовать парсеры.
Мы собираем данные об интересах пользователей и показа более релевантных рекламных предложений. Мы видим улучшение результатов рекламных кампаний, соответственно больше заявок, больше клиентов и больше прибыли для бизнеса.
Законно ли это? Нет. Это нарушение ФЗ “о персональных данных”. За такими действиями последует правовая ответственность. Многие отстаивают позицию, что раз человек разместил данные в социальной сети — он делает их публичными. Но судебная практика так не считает. Человек должен лично и осознанно разрешить использование его данных.
Хотя в мире есть противоречивая судебная практика. Например, hiQ Labs выиграла суд у гиганта Linkedin. Компания собирала открытые данные для научных исследований. Суд встал на позицию ограничения монополий на данные крупных корпораций. При этом есть решения суда с противоположной позицией. Кроме того соблюдение правил и персональных данных еще не гарантирует соблюдение норм об авторском праве.
Мы знаем из закона, что любая информация, относящаяся прямо или косвенно к физическому лицу, является персональной. Из этого определения нельзя сказать, что аккаунт не попадает под это определение. В каждом конкретном случае вопрос о данных будет решать суд. Тем более на аватарке часто стоят реальные фотографии.
Мы в 5 CATS используем парсинг для разных целей, от сбора ключевых слов для контекстной рекламы до составления баз ретаргетинга для социальных сетей. Парсинг всегда помогает собрать данные более точно и сэкономить время (всё, что делают парсеры, можно сделать вручную, затратив на это миллионы лет).
Сейчас почти каждый проект по продвижению ВКонтакте не обходится без парсеров, используем мы разные, в основном это Церебро Таргет и Таргет Хантер. Однако некоторые парсеры мы писали сами с нуля. Например, однажды перед нами стояла задача собрать сообщества ВКонтакте, которые подключены к маркет-платформе и при этом их суммарный охват превышает 20.000 человек. Маркет-платформа позволяет их все проранжировать, но не позволяет выгрузить в документ в виде списка ссылок. Такой парсер мы написали сами за 20 минут и моментально выполнили задачу.
Любой парсинг всегда даёт разные результаты в зависимости от той задачи, которую ему ставят. Программы могут собирать аккаунты пользователей, которые ведут себя определенным образом: ставят лайки на посты, подписываются на разные сообщества, участвуют в опросах. Как правило, базы ретаргетинга, которые мы получаем с помощью парсинга, работают более эффективно и оптимизируют стоимость целевого действия, чем похожие настройки, выставленные без помощи дополнительных инструментов. Мы постоянно тестируем разные программы и опытным путём находим то, что выполняет конкретную задачу.
Парсер резюме hh.ru
Парсер HH.ru выгружает резюме с hh.ru. Он собирает такие данные: возраст, пол, город, желаемая должность, желаемая зарплата, краткое описание требований, опыт работы, ключевые навыки, информация о соискателе, образование, знание языков и ссылка на страницу. Набор данных можно дополнять/менять при необходимости.
Вы можете сохранить выгрузку для дальнейшего редактирования или экспорта на сайт. Доступны такие варианты экспорта данных, собранных парсером резюме hh.ru:
![]()
Если у вас не получается самостоятельно загрузить собранные данные в свою CMS или в свой интернет магазин/сайт, оставьте заявку — и мы постараемся Вам помочь.

Как протестировать парсинг резюме с hh.ru
Протестируйте работу парсера резюме с hh.ru бесплатно в демо-версии Datacol. Инструкция по тестированию приведена на видео:
Чтобы протестировать работу парсера резюме с hh.ru:
Шаг 1. Установите демо-версию программы Datacol. Демо-версия программы имеет все возможности платной, но сохраняет только первые 25 результатов парсинга.
Шаг 2. В дереве кампаний найдите настройку ad-parsers/hh.ru-resume.par.
Шаг 3. В блоке Входные данные укажите ссылку на выборку, резюме из которой хотите собрать.

По умолчанию в настройке задано ограничение на просмотр 120 страниц (текущее суточное ограничение на НН). Лимиты могут отличаться и зависят от вашего тарифного плана. Изменить эту настройку можно в Настройки->Общие->Результатов за парсинг.

Шаг 4. Для старта сбора данных нажмите кнопку Запуск.

Шаг 5. После запуска у вас появиться окно браузера Google Chrome с вашей ссылкой. В нем выполните авторизацию на сайте.

Шаг 6. После авторизации нажмите кнопку Продолжить, которая будет в отдельном окне.

Шаг 7. Дождитесь появления результатов работы парсера hh.ru. После появления результатов можно принудительно остановить парсинг (нажав кнопку Стоп).
![]()
Шаг 8. После окончания/принудительной остановки парсера в папке Мои документы можно найти файл hh.ru-resume.xlsx:
![]()
Если сайт-источник забанит ваш IP адрес (обычно в результате этого перестают находиться новые результаты), задействуйте прокси.
Обработка и экспорт данных
Способы обработки данных, собранных парсером резюме hh.ru:
Форматы экспорта данных, собранных парсером резюме hh.ru:
Загрузка в CMS/магазин/сайт»
Если у вас не получается самостоятельно загрузить собранные данные в свою CMS/интернет магазин/сайт, оставьте заявку и мы постараемся Вам помочь.
Мониторинг объявлений
Сколько стоит парсер резюме hh.ru
Парсер резюме hh.ru – это настройка (пресет/конфигурация) программы Datacol. Настройка доступна в демо-версии программы. Демо-версия имеет все возможности платной версии, но сохраняет только первые 25 результатов парсинга. Узнать актуальную стоимость лицензии Datacol и купить программу можно здесь, также вам необходимо оплатить тарифный план на hh.ru.
Что делать, если hh.ru блокирует (банит) парсинг?
Если hh.ru забанит ваш IP-адрес (обычно в результате этого перестают находиться новые результаты), задействуйте прокси или VPN.
Как разобраться в Datacol?
Ознакомьтесь, пожалуйста, с видеоуроками по Datacol (хотя бы первые 3-5 уроков). Если при дальнейшей настройке программы у вас возникнут вопросы, задайте их нам. Поддержка Datacol отвечает с понедельника по пятницу.
Какие условия покупки Datacol?
Все условия приобретения программы приведены здесь.
Как я получу программу после ее оплаты?
После поступления оплаты за лицензию вы получите код активации программы и информацию о сроках действия вашей лицензии на адрес электронной почты, указанный при покупке. Инструкцию по активации можно посмотреть здесь.
Как мы разработали HR-систему: парсер резюме, чистый PHP и база данных ClickHouse
Авторизуйтесь
Как мы разработали HR-систему: парсер резюме, чистый PHP и база данных ClickHouse

Разработчик программного обеспечения Neti
До 2019 года в компании, где я работаю, использовали внешнюю платную систему. Из-за неё рекрутеры страдали: сервис зависал, в нём не было нужных отчетов. А иногда он ломался и блокировал работу HR-отдела на полдня. Когда мириться с багам надоело, мы разработали собственный сервис, которым пользуемся уже год. В статье расскажу, как проходила разработка HR-системы, какие трудности возникли в процессе и как мы с ними справились.
Как появилась HR-система
В нашей компании собеседования проводят не только рекрутеры, но и программисты. Сначала HR-менеджеры созваниваются с кандидатом, чтобы уточнить информацию в резюме. Если всё нормально, человека приглашают на техническое собеседование, которое проводит опытный разработчик.
В 2018 году я возглавил новое направление веб-разработки и стал набирать людей. Ребята из 1С поделились со мной Google-таблицей, где фиксировали результаты технических собеседований. Мне она показалась неудобной, и в свободное время я написал веб-приложение для проведения тестирований. После собеседования программа выдавала комплексный отчет, который помогал быстро оценить сильные и слабые стороны кандидата.
Я показал приложение коллегам из 1С, и они захотели на него перейти. Техническое собеседование для разработчика 1С состоит из двух частей: теории и практики. Оба этапа проходят по Skype. Во время теории кандидат отвечает на вопросы программиста, а на практике решает задачи, при этом собеседующий наблюдает за ходом решения по демонстрации экрана. Несмотря на то, что у 1С-ников собеседование более объёмное, чем у моего направления, расширять функционал тестирований в приложении не пришлось — он изначально был достаточно гибким.
Профиль разработчика, который проводит собеседования
Дальше программу увидели наши HR-специалисты. К тому времени они уже настрадались со сторонним сервисом и попросили заняться разработкой полноценной HR-системы. Для работы над проектом я выделил штатного веб-программиста. Он реализовывал «хотелки» HR-отдела, а я выступал в качестве архитектора и второго разработчика. Техническое задание мы не составляли, разработка велась in material.
PHP без MVC
Я писал приложение на чистом PHP, не используя MVC-фреймворк, потому что не ожидал, что система получит дальнейшее развитие. Но когда к проекту подключился второй разработчик, выяснилось, что писать без MVC — ошибка.
В нашем случае в представлениях было много логики и запросов к базе данных, которые второму программисту иногда приходилось вычищать. Целые куски кода дублировались и не были вынесены в отдельные классы и функции. Чтобы изменить обращение к новым или измененным полям, приходилось тратить на 10–20% времени больше, чем если бы правки вносились через MVC.
Из этой истории я сделал вывод, что даже когда пишешь для себя, лучше использовать MVC-фреймворк. Ведь если проект перерастет во что-то большое, без MVC дальнейшая разработка станет сложной.
Сейчас мы подключили к HR-системе Doctrine ORM и постепенно переводим её на Symfony Framework, где-то используем View JS.
Парсер файлов резюме вместо нейросети
Раньше данные из резюме HR-специалисты переносили в карточку кандидата вручную. На заполнение полей уходило много времени. Хотелось автоматизировать этот процесс.
Сначала мы планировали подключить к системе нейросеть, которая бы создавала карточку кандидата и сама переносила в неё из резюме основную информацию: имя, фамилию, город, должность и так далее. Но оказалось, что существующие механизмы ИИ не способны распознать все нужные данные. Например нейросеть не может определить стаж работы или город соискателя. Чтобы обучить ИИ, необходимо загрузить в систему минимум пять тысяч резюме, а лучше десять. Это очень долгий процесс, а на разработку HR-системы было всего полгода. Поэтому мы решили задачу по-другому и разработали парсинг файлов резюме на регулярных выражениях.
В нём используются сторонние библиотеки tika-server (Apache Tika), которая работает с PDF, и LibreOffice, обрабатывающая DOC и XLM. Рекрутеры загружают резюме в форматах PDF, DOC, XLM, TXT в HR-систему, а библиотеки преобразуют эти файлы в обычный текст. Обработчик через регулярные выражения вытаскивает из текста данные, раскидывает их в подходящие поля карточки кандидата и записывает в базу данных. Процесс короткий, но кода много. Чтобы вытаскивать корректную информацию, мы написали множество регулярных выражений под разные структуры резюме. При этом учитывались и русский, и английский языки.
Несмотря на то, что мы многое предусмотрели, около 20% резюме парсер распознает с ошибками. Это происходит, когда документ приходит в нетипичном формате, например в виде картинки. Однажды нам прислали фотографию с резюме, написанным от руки. Такое тоже бывает.
Удобный визуальный редактор
Первое время в системе стоял стандартный визуальный редактор LTE Admin, который иногда неправильно отображал данные в карточке кандидата после распарсивания резюме. Так как редактор не основной инструмент, мы решили не покупать его, а поискать бесплатный. Хотелось, чтобы он был удобным, так что мы перепробовали 5–6 вариантов, прежде чем нашли подходящий.
Сейчас в HR-системе стоит Trumbowyg с расширенным функционалом. Рекрутеры хотели при вводе данных переключаться с текстового редактора на визуальный и обратно. В текстовом варианте содержится много html-тегов, и другие бесплатные редакторы при переключении плохо их обрабатывали. В Trumbowyg есть специальные API-методы, которые позволяют это обойти.
Добавили метрики «источники» и «каналы»
Один из важнейших отчетов для рекрутеров — это воронка кандидатов, которая показывает эффективность работы HR-отдела. В стороннем сервисе, которым мы пользовались раньше, можно было формировать воронку по источникам. Источники — аналитика, которая позволяет увидеть, откуда пришло резюме: HeadHunter, почта, сайт. С её помощью рекрутеры, например, понимают, что в рамках вакансии 1С-программиста HeadHunter — эффективная площадка, а для вакансий битрикс-разработчика или разработчика Dynamics она не подходит.
Мы перенесли этот механизм в нашу систему и доработали. Теперь, если резюме приходит через сайт или на почту, сервис сам распознает и проставляет источник в карточке кандидата. В остальных случаях источник рекрутеры заполняют вручную.
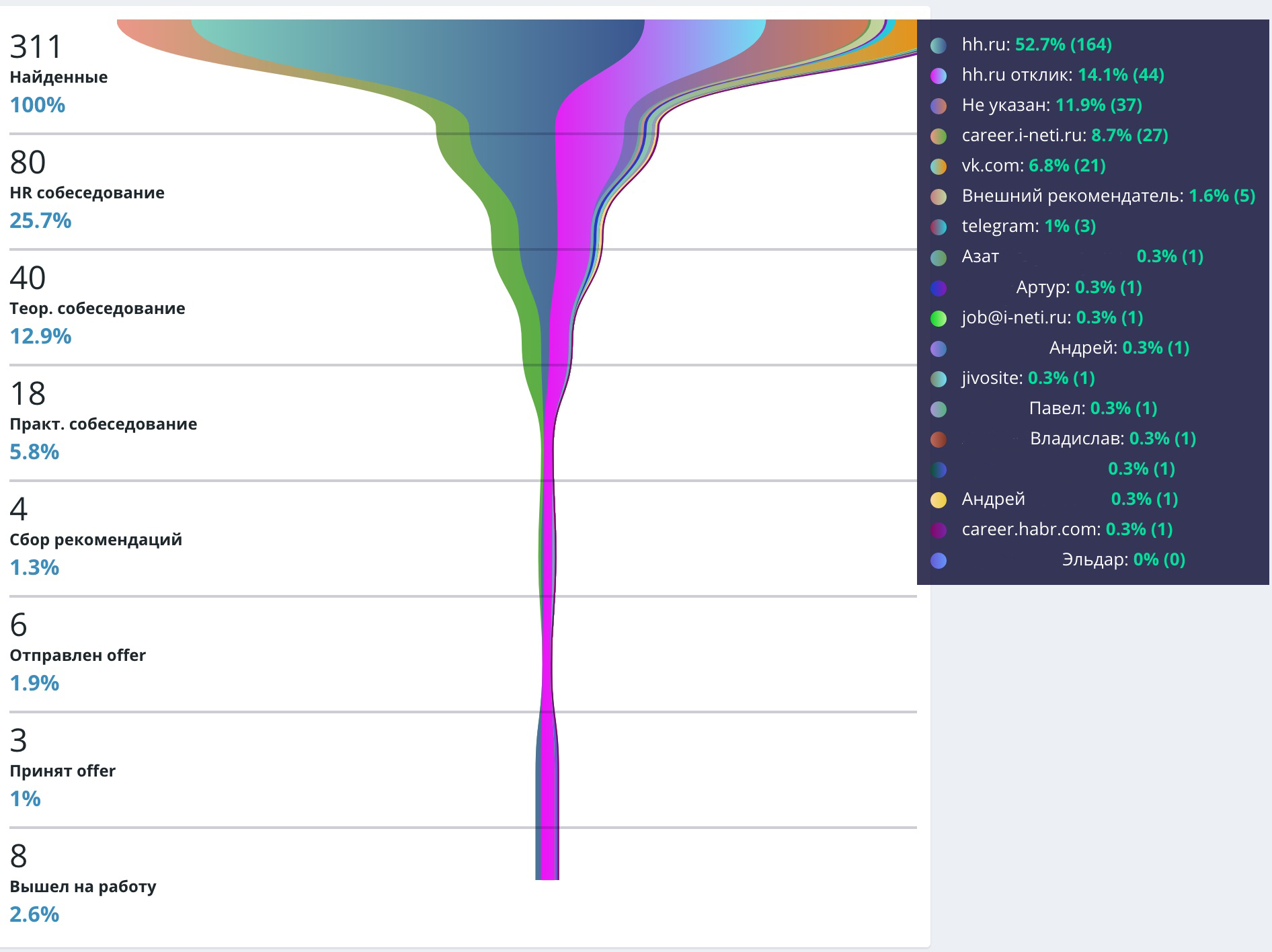
Воронка кандидатов по источникам с 1 ноября по 21 декабря 2020 года
Но наши HR-менеджеры мечтали о том, чтобы воронка использовалась для более глубокой аналитики и с её помощью выявлялись наилучшие каналы для рекламы вакансий. Так была придумана метрика «каналы», которую мы не встречали в описаниях других систем, даже платных. Аналитика по каналам позволяет узнать, как кандидат попал в то место, откуда отправил резюме: через поиск в Google, рекламу в Яндексе или на каком-то другом сайте.
Чтобы вытаскивать эти данные, мы сначала хотели подключить к системе API Яндекс.Метрики. Но оказалось, что оно не отслеживает путь пользователя. Из документации Яндекса узнали о базе данных ClickHouse, которая полностью синхронизируется с Яндекс.Метрикой. Когда человек заходит на наши сайты, ему присваивается идентификационный номер. Если этот пользователь отправит резюме, то его идентификатор попадет вместе с заявкой в HR-систему, и по нему мы сможем посмотреть весь путь кандидата до отклика. Пока мы подключили ClickHouse к тестовой HR-системе и проверяем, как база работает. Позже перенесём её в рабочий сервис.
Приложение для автотестирований
Для коллег из 1С мы реализовали отдельное приложение для автотестирований на View JS, которое через API обращается к HR-системе для получения данных. Автотестирование — это упрощенное техническое собеседование: там есть вопросы с вариантами ответов. Если человек не уверен, что готов к собеседованию, он может пройти автотестирование и узнать свой результат.
Для прохождения необходимо указать адрес электронной почты. Этот адрес будет автоматически добавлен в карточку кандидата, которую создаст HR-система. Если пользователь через некоторое время пришлет нам резюме, программа распознает его электронную почту и подтянет его карточку вместе с результатом тестирования.
На разработку HR-системы ушло полгода и около 800 тыс. рублей. Точной суммы нет, потому что делали сами и сметы не составляли. По моим подсчетам, эти затраты уже окупились. Мы не тратим деньги на сторонний сервис, который ломается после каждого обновления, а наши рекрутеры счастливы, что работают в удобной гибкой системе.
Если вы тоже занимались разработкой HR-системы, поделитесь опытом, как прошло. А если у вас есть идеи, что еще можно улучшить в её функционале, пишите в комментариях.