Страничная организация памяти
Презентацию к данной лекции Вы можете скачать здесь.
Введение
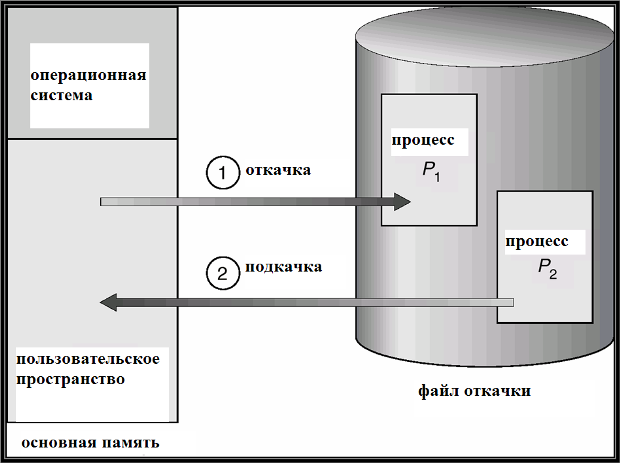
Откачка и подкачка
Наибольшие временные затраты на откачку – это затраты на передачу данных: полный образ процесса может занимать большую область памяти. Общее время откачки пропорционально размеру откачиваемых данных.
Схема откачки и подкачки изображена на рис. 16.1.
Смежное распределение памяти
Общая задача распределения памяти и стратегии ее решения
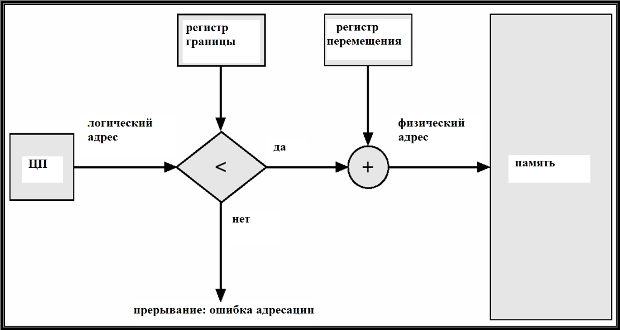
В общем случае, в операционных системах может использоваться смежное распределение памяти в нескольких смежных областях. Свободная область – это смежный блок свободной памяти. Свободные области могут быть произвольно разбросаны по памяти. При загрузке процесса ему предоставляется память из любой свободной смежной области, которая достаточно велика для его размещения. При этом операционная система хранит список свободных областей памяти и список занятых областей памяти. Все эти области могут быть произвольно расположены в памяти и иметь различную длину.
Возникает общая задача распределения памяти: Имеется список свободных областей памяти и список занятых областей разного размера. Разработать и реализовать оптимальный ( по некоторому критерию) алгоритм выделения свободного смежного участка памяти длины n (слов или байтов).
Для решения данной задачи применяются следующие стратегии: метод первого подходящего (first-fit), метод наиболее подходящего (best-fit) и метод наименее подходящего (worst-fit).Рассмотрим каждую из них подробнее.
Метод первого подходящего:Выбирается первый по списку свободный участок подходящего размера (не меньшего, чем n ). На первый взгляд, данная стратегия оптимальна, но далее мы увидим, что это не всегда так.
Метод наиболее подходящего:Выбирается из списка наиболее подходящий свободный участок (минимального размера, не меньшего, чем n ). В отличие от предыдущего метода, требует просмотра всего списка, если список не упорядочен по размеру областей. Применение метода приводит к образованию оставшейся части самого маленького размера.
Метод наименее подходящего: Выбирается из списка подходящая область наибольшего размера. Почему наибольшего? Чтобы избежать фрагментации (проблема фрагментации подробно рассмотрена далее в данной лекции).
Применение первой и второй стратегий лучше со следующих точек зрения: скорость выполнения и минимальность объема использованной памяти. Однако их применение может создать фрагментацию.
Фрагментация
Внешняя фрагментация может быть уменьшена или ликвидирована путем применения компактировки (compaction) – сдвига или перемешивания памяти с целью объединения всех не смежных свободных областей в один непрерывный блок. Компактировка может выполняться либо простым сдвигом всех свободных областей памяти, либо путем перестановки занятых областей, с выбором на каждом шаге подходящей свободной области методом наиболее подходящего. Компактировка возможна, только если связывание адресов и перемещение (см. лекцию 15) происходит динамически. Компактировка выполняется во время исполнения программы.
При компактировке памяти и анализе свободных областей может быть выявлена проблема зависшей задачи: какая-либо задача может «застрять» в памяти, так как выполняет ввод-вывод в свою область памяти ( по этой причине откачать ее невозможно). Решение данной проблемы: ввод-вывод должен выполняться только в специальные буфера, выделяемой для этой цели операционной системой.
Что раздувает память в Ruby?
У нас в Phusion работает простой многопоточный HTTP-прокси на Ruby (раздаёт пакеты DEB и RPM). Я видел на нём потребление памяти 1,3 ГБ. Но это безумие для stateless-процесса…
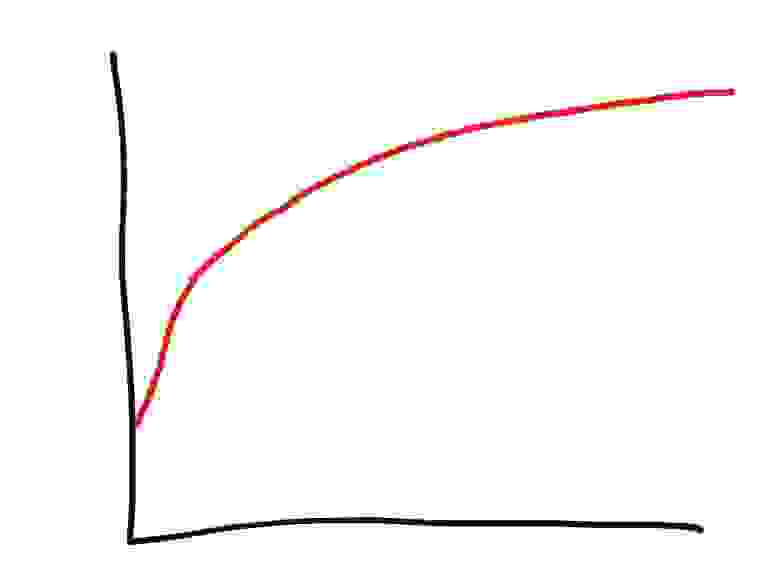
Вопрос: Что это? Ответ: Использование памяти процессом Ruby с течением времени!
Оказывается, я не одинок в этой проблеме. Приложения Ruby могут использовать много памяти. Но почему? Согласно Heroku и Нейту Беркопеку, в основном раздутие связано с фрагментацией памяти и чрезмерным распределением по кучам.
Беркопек пришёл к выводу, что существует два решения:
Магия — это просто наука, которую мы пока не понимаем. Поэтому я отправился в исследовательское путешествие, чтобы узнать всю правду. В этой статье осветим следующие темы:
Содержание
Распределение памяти в Ruby: введение
Распределение памяти в Ruby происходит на трёх уровнях, сверху вниз:
На своей стороне Ruby организует объекты в областях памяти, называемых страницами кучи Ruby. Такая страница кучи разбита на слоты одинакового размера, где один объект занимает один слот. Будь то строка, хеш-таблица, массив, класс или что-то ещё, он занимает один слот.

Слоты на странице кучи могут быть заняты или свободны. Когда Ruby выделяет новый объект, тот сразу пытается занять свободный слот. Если свободных слотов нет, то будет выделена новая страница кучи.
Слот небольшой, около 40 байт. Очевидно, что некоторые объекты в него не поместятся, например, строки по 1 МБ. Тогда Ruby сохраняет информацию в другом месте за пределами страницы кучи, а в слот помещает указатель на эту внешнюю область памяти.
Данные, которые не помещаются в слот, хранятся вне страницы кучи. Ruby помещает в слот указатель на эти внешние данные
Как страницы кучи Ruby, так и любые внешние области памяти выделяются с помощью распределителя памяти системы.
Системный распределитель памяти
Распределитель памяти операционной системы является частью glibc (среда выполнения C). Он используется почти всеми приложениями, а не только Ruby. У него простой API:
В свою очередь, распределитель памяти обращается к API ядра. Он забирает из ядра гораздо большие куски памяти, чем запрашивают его собственные абоненты, поскольку вызов ядра дорогостоящий и у API ядра есть ограничение: оно может выделять память только кратно 4 КБ.
Распределитель памяти выделяет большие куски — они называются системные кучи — и делит их содержимое для удовлетворения запросов из приложений
Область памяти, которую распределитель памяти выделяет из ядра, называется кучей. Обратите внимание, что она не имеет ничего общего со страницами кучи Ruby, поэтому для ясности будем использовать термин системная куча.
Затем распределитель памяти назначает части системных куч своим вызывающим объектам, пока не останется свободного места. В этом случае распределитель памяти выделяет из ядра новую системную кучу. Это похоже на то, как Ruby выделяет объекты из страниц кучи Ruby.
Ruby выделяет память из распределителя памяти, который, в свою очередь, выделяет её из ядра
Ядро может выделять память только юнитами по 4 КБ. Один такой блок 4 КБ называется страницей. Чтобы не путать со страницами кучи Ruby, для ясности будем использовать термин системная страница (OS page).
Причину сложно объяснить, но так работают все современные ядра.
Выделение памяти через ядро оказывает значительное влияние на производительность, поэтому распределители памяти пытаются минимизировать количество вызовов ядра.
Определение использования памяти
Таким образом, память выделяется на нескольких уровнях, и каждый уровень выделяет больше памяти, чем ему действительно нужно. На страницах кучи Ruby могут быть свободные слоты, как и в системных кучах. Поэтому ответ на вопрос «Сколько памяти используется?» полностью зависит от того, на каком уровне вы спрашиваете!
Инструменты вроде top или ps показывают использование памяти с точки зрения ядра. Это означает, что верхние уровни должны согласованно работать, чтобы освободить память с точки зрения ядра. Как вы узнаете далее, это сложнее, чем кажется.
Что такое фрагментация?
Фрагментация памяти означает, что выделения памяти беспорядочно разбросаны. Это может вызвать интересные проблемы.
Фрагментация на уровне Ruby
Рассмотрим сборку мусора Ruby. Сборка мусора для объекта означает маркировку слота страницы кучи Ruby как свободного, что позволяет его повторно использовать. Если вся страница кучи Ruby состоит только из свободных слотов, то всю её целиком можно освободить обратно в распределитель памяти (и, возможно, обратно в ядро).
Но что произойдёт, если свободны не все слоты? Что делать, если у нас много страниц кучи Ruby, а сборщик мусора освобождает объекты в разных местах, так что в конечном итоге остаётся много свободных слотов, но на разных страницах? В такой ситуации у Ruby есть свободные слоты для размещения объектов, но распределитель памяти и ядро продолжат выделять память!
Фрагментация на уровне распределителя памяти
У распределителя памяти похожая, но совсем другая проблема. Ему не нужно освобождать сразу целые системные кучи. Теоретически, он может освободить любую отдельную системную страницу. Но поскольку распределитель памяти имеет дело с выделениями памяти произвольного размера, на системной странице может находиться несколько выделений. Он не может освободить системную страницу, пока не освободятся все выделения.
Подумайте, что произойдёт, если у нас есть выделение на 3 КБ, а также выделение на 2 КБ, разбитое на две системные страницы. Если вы освободите первые 3 КБ, обе системные страницы останутся частично заняты и не могут быть освобождены.
Поэтому при неудачном стечении обстоятельств на системных страницах будет много свободного места, но целиком они не освбождаются.
Ещё хуже: что делать, если много свободных мест, но ни одно из них не достаточно велико, чтобы удовлетворить новый запрос на выделение? Распределителю памяти придётся выделить совершенно новую системную кучу.
Является ли фрагментация страниц кучи Ruby причиной раздутия памяти?
Вполне вероятно, что фрагментация является причиной чрезмерного использования памяти в Ruby. Если так, то какая из двух фрагментаций наносит больший вред? Это…
ObjectSpace.memsize_of_all возвращает память, занятую всеми активными объектами Ruby. То есть всё место в своих слотах и любые внешние данные. На приведённой выше диаграмме это размер всех синих и оранжевых объектов.
GC.stat позволяет узнать размер всех свободных слотов, т. е. всю серую область на иллюстрации выше. Вот алгоритм:
Если суммировать их — то это вся память, о которой знает Ruby, и она включает в себя фрагментацию страниц кучи Ruby. Если с точки зрения ядра использование памяти выше, то оставшаяся память уходит куда-то вне контроля Ruby, например, на сторонние библиотеки или фрагментацию.
Я написал простую тестовую программу, которая создает кучу потоков, каждый из которых выделяет строки в цикле. Вот какой результат получился через некоторое время:
это… просто… безумие!
Результат показывает, что Ruby настолько слабо влияет на общий объём используемой памяти, что не имеет значения, фрагментированы страницы кучи Ruby или нет.
Придётся искать виновника в другом месте. По крайней мере, теперь мы знаем, что Ruby не виновата.
Исследование фрагментации на уровне распределителя памяти
Ещё один вероятный подозреваемый — распределитель памяти. В конце концов, Нейт Беркопек и Heroku заметили, что возня с распределителем памяти (либо полная замена на jemalloc, либо установка магической переменной среды MALLOC_ARENA_MAX=2 ) резко снижает использование памяти.
Давайте сначала посмотрим, что делает MALLOC_ARENA_MAX=2 и почему это помогает. Затем исследуем фрагментацию на уровне распределителя.
Чрезмерное распределение памяти и glibc
В каждый момент времени только один поток может работать с системной кучей. В многопоточных задачах возникает конфликт и, следовательно, снижается производительность
В распределителе памяти на такой случай есть оптимизация. Он пытается создать несколько системных куч и назначить их разным потокам. Бóльшую часть времени поток работает только со своей кучей, избегая конфликтов с другими потоками.
Фактически, максимальное количество системных куч, выделенных таким образом, по умолчанию равно количеству виртуальных процессоров, умноженному на 8. То есть в двухъядерной системе с двумя гиперпотоками на каждом получается 2 * 2 * 8 = 32 системные кучи! Это то, что я называю чрезмерным распределением.
Почему множитель по умолчанию такой большой? Потому что ведущий разработчик распределителя памяти — Red Hat. Их клиенты — большие компании с мощными серверами и тонной оперативной памяти. Вышеуказанная оптимизация позволяет повысить среднюю производительность многопоточности на 10% за счёт значительного увеличения использования памяти. Для клиентов Red Hat это хороший компромисс. Для большинства остальных — вряд ли.
Нейт в своём блоге и статья Heroku утверждают, что увеличение числа системных куч увеличивает фрагментацию, и ссылаются на официальную документацию. Переменная MALLOC_ARENA_MAX уменьшает максимальное количество системных куч, выделяемых для многопоточности. По такой логике, она уменьшает фрагментацию.
Визуализация системных куч
Верно ли утверждение Нейта и Heroku, что увеличение количества системных куч увеличивает фрагментацию? На самом деле, есть ли вообще проблема с фрагментацией на уровне распределителя памяти? Я не хотел принимать ни одно из этих предположений как должное, поэтому начал исследование.
К сожалению, не существует инструментов для визуализации системных куч, поэтому я сам написал такой визуализатор.
Во-первых, нужно как-то сохранить схему распределения системных куч. Я изучил исходники распределителя памяти и посмотрел, как он внутренне представляет память. Далее написал библиотеку, которая перебирает эти структуры данных и записывает схему в файл. Наконец, написал инструмент, который берёт такой файл в качестве входных данных и компилирует визуализацию в виде изображений HTML и PNG (исходный код).
Вот пример визуализации одной конкретной системной кучи (их гораздо больше). Небольшие блоки в этой визуализации представляют системные страницы.
Хотя фрагментация остаётся проблемой, но дело не в ней!
Скорее, проблема в большом количестве серого цвета: это распределитель памяти не отдаёт память обратно в ядро!
После повторного изучения исходного кода распределителя памяти оказалось, что по умолчанию он отдаёт в ядро только системные страницы в конце системной кучи, и даже это делает редко. Вероятно, такой алгоритм реализован из соображений производительности.
Волшебный трюк: обрезание
К счастью, я нашёл один фокус. Есть один программный интерфейс, который заставит распределитель памяти освободить для ядра не только последние, а все подходящие системные страницы. Он называется malloc_trim.
Я знал об этой функции, но не думал, что она полезна, потому что в руководстве сказано следующее:
Функция malloc_trim() пытается освободить свободную память в верхней части кучи.
Руководство ошибается! Анализ исходного кода говорит, что программа освобождает все подходящие системные страницы, а не только верхние.
Что произойдёт, если вызывать эту функцию во время сборки мусора? Я изменил исходный код Ruby 2.6, чтобы вызывать malloc_trim() в функции gc_start из gc.c, например:
И вот результаты теста:
Вот как всё выглядит в визуализации:
Мы видим много белых областей, которые соответствуют системным страницам, освобождённым обратно в ядро.
Заключение
Оказалось, что фрагментация, в основном, ни при чём. Дефрагментация по-прежнему полезна, но основная проблема заключается в том, что распределитель памяти не любит освобождать память обратно в ядро.
К счастью, решение оказалось очень простым. Главное было найти первопричину.
Исходный код визуализатора
Что насчёт производительности?
Производительность оставалась одним из главных опасений. Вызов malloc_trim() не может обходиться бесплатно, а по коду алгоритм работает в линейном времени. Поэтому я обратился к Ною Гиббсу, который запустил бенчмарк Rails Ruby Bench. К моему удивлению, патч вызвал небольшое увеличение производительности.


Это взорвало мой разум. Эффект непонятный, но новость хорошая.
Что такое фрагментация памяти?
Я слышал, как термин «фрагментация памяти» несколько раз использовался в контексте динамического выделения памяти в C ++. Я нашел несколько вопросов о том, как бороться с фрагментацией памяти, но не могу найти прямой вопрос, который касается самой этой проблемы. Так:
Представьте, что у вас есть «большое» (32 байта) пространство свободной памяти:
Теперь выделим некоторые из них (5 выделений):
Теперь освободите первые четыре распределения, но не пятое:
Теперь попробуйте выделить 16 байтов. Ой, я не могу, хотя там почти вдвое больше свободных.
В системах с виртуальной памятью фрагментация представляет собой меньшую проблему, чем вы думаете, потому что большие выделения должны быть непрерывными только в виртуальном адресном пространстве, а не в физическом адресном пространстве. Так что в моем примере, если бы у меня была виртуальная память с размером страницы 2 байта, я мог бы без проблем выполнить распределение в 16 байтов. Физическая память будет выглядеть так:
тогда как виртуальная память (будучи намного больше) может выглядеть так:
Тактика для предотвращения фрагментации памяти в C ++ работает путем выделения объектов из разных областей в соответствии с их размером и / или ожидаемым временем жизни. Поэтому, если вы собираетесь создать много объектов и затем уничтожить их все вместе, выделите их из пула памяти. Любые другие распределения, которые вы делаете между ними, не будут из пула, следовательно, не будут располагаться между ними в памяти, поэтому память не будет фрагментирована в результате.
Как правило, вам не нужно сильно беспокоиться об этом, если ваша программа не работает долго и не занимает много места на диске. Когда у вас есть смесь недолговечных и долгоживущих объектов, вы подвергаетесь наибольшему риску, но даже тогда malloc сделаете все возможное, чтобы помочь. По сути, игнорируйте его до тех пор, пока в вашей программе не возникнут сбои выделения или если система неожиданно не исчерпает память (поймайте это в тестировании, если хотите!)
Стандартные библиотеки ничем не хуже всего, что выделяет память, и все стандартные контейнеры имеют Alloc параметр шаблона, который можно использовать для точной настройки их стратегии распределения, если это абсолютно необходимо.
Что такое фрагментация памяти?
Как я могу определить, является ли фрагментация памяти проблемой для моего приложения? Какая программа больше всего страдает?
Когда память сильно фрагментирована, выделение памяти, вероятно, займет больше времени, потому что распределитель памяти должен сделать больше работы, чтобы найти подходящее пространство для нового объекта. Если, в свою очередь, у вас много выделений памяти (что вы, вероятно, делаете с момента фрагментации памяти), время выделения может даже привести к заметным задержкам.
Каковы хорошие распространенные способы борьбы с фрагментацией памяти?
Используйте хороший алгоритм для выделения памяти. Вместо того, чтобы выделять память для множества небольших объектов, предварительно выделите память для непрерывного массива этих меньших объектов. Иногда немного расточительно при распределении памяти может повлиять на производительность и избавить вас от необходимости иметь дело с фрагментацией памяти.
Предположим для простого игрушечного примера, что у вас есть десять байтов памяти:
Теперь давайте выделим три трехбайтовых блока с именами A, B и C:
Теперь освободите блок B:
Что произойдет, если мы попытаемся выделить четырехбайтовый блок D? Ну, у нас есть четыре байта свободной памяти, но у нас нет четырех смежных свободных байтов памяти, поэтому мы не можем выделить D! Это неэффективное использование памяти, потому что мы должны были хранить D, но мы не смогли. И мы не можем переместить C, чтобы освободить место, потому что очень вероятно, что некоторые переменные в нашей программе указывают на C, и мы не можем автоматически найти и изменить все эти значения.
Откуда ты знаешь, что это проблема? Ну, самый большой признак в том, что размер виртуальной памяти вашей программы значительно больше, чем объем памяти, который вы фактически используете. В реальном примере у вас было бы намного больше, чем десять байтов памяти, поэтому D просто выделялся бы, начиная с байта 9, а байты 3-5 оставались бы неиспользованными, если позже вы не выделите что-нибудь длиной три байта или меньше.
Как вы это предотвращаете? Наихудшие случаи, как правило, возникают, когда вы часто создаете и уничтожаете небольшие объекты, поскольку это имеет тенденцию вызывать эффект «швейцарского сыра», когда множество мелких объектов разделено множеством маленьких отверстий, что делает невозможным размещение более крупных объектов в этих отверстиях. Когда вы знаете, что собираетесь это делать, эффективная стратегия состоит в том, чтобы предварительно выделить большой блок памяти в качестве пула для ваших небольших объектов, а затем вручную управлять созданием небольших объектов в этом блоке, вместо того, чтобы Распределитель по умолчанию обрабатывать его.
В общем, чем меньше выделений вы делаете, тем меньше вероятность фрагментации памяти. Однако STL справляется с этим довольно эффективно. Если у вас есть строка, которая использует все ее текущее размещение, и вы добавляете к ней один символ, она не просто перераспределяет ее текущую длину плюс один, она удваивает ее длину. Это вариант стратегии «пул для частых небольших выделений». Строка захватывает большой кусок памяти, так что она может эффективно справляться с многократным небольшим увеличением размера без повторных небольших перераспределений. Все контейнеры STL на самом деле делают подобные вещи, поэтому обычно вам не нужно слишком беспокоиться о фрагментации, вызванной автоматически перераспределяемыми контейнерами STL.
Хотя, конечно, контейнеры STL не объединяют память между собой, поэтому, если вы собираетесь создать много небольших контейнеров (а не несколько контейнеров, которые часто меняются в размерах), вам, возможно, придется позаботиться о предотвращении фрагментации таким же образом, как вы. будет для любых часто создаваемых небольших объектов, STL или нет.
Фрагментация памяти является проблемой, если ваша программа использует намного больше системной памяти, чем требовалось бы для ее фактических данных о выплате (и вы исключили утечки памяти).
Используйте хороший распределитель памяти. IIRC, те, которые используют стратегию «наилучшего соответствия», как правило, намного лучше избегают фрагментации, хотя и немного медленнее. Однако было также показано, что для любой стратегии распределения существуют наихудшие патологические случаи. К счастью, типичные схемы распределения большинства приложений на самом деле относительно благоприятны для обработки распределителями. Там есть куча статей, если вы заинтересованы в деталях:
Обновление:
Google TCMalloc: Malloc с кэшированием потоков
Было обнаружено, что он довольно хорошо справляется с фрагментацией в длительном процессе.
Я разрабатывал серверное приложение, в котором были проблемы с фрагментацией памяти в HP-UX 11.23 / 11.31 ia64.
Это выглядело так. Был процесс, который делал выделения памяти и освобождения и работал в течение нескольких дней. И хотя утечек памяти не было, потребление памяти процессом продолжало расти.
Я знаю, что одним из способов избежать фрагментации памяти в HP-UX является использование Small Block Allocator или MallocNextGen. В RedHat Linux распределитель по умолчанию, кажется, довольно хорошо справляется с распределением множества маленьких блоков. На Windows есть Low-fragmentation Heap и она решает проблему большого количества небольших выделений.