Как понять слова в видео на иностранном языке, который не знаешь 27.11.2016 16:07
Представим ситуацию, что есть видео на немецком (японском, корейском, английском) и вам надо быстро узнать о чем в нем говорят. Но навык понимания устной речи на этом языке у вас развит очень плохо или отсутствует. Что делать?
Расскажем о некоторых трюках, которые могут пригодиться в такой ситуации.
1. Скачиваем субтитры
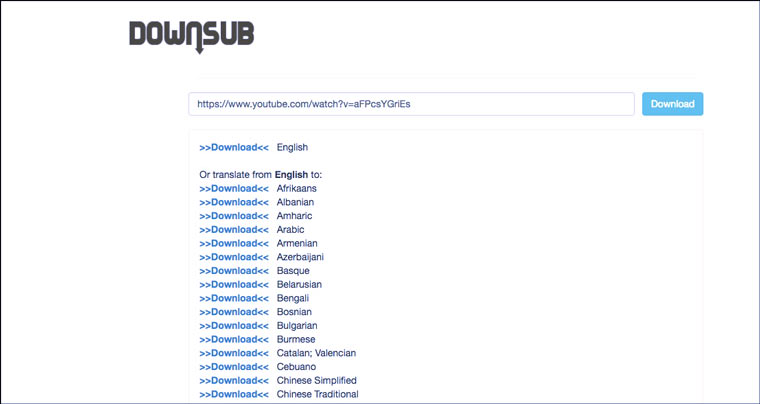
Наличие текстовой версии видео очень помогает в этой ситуации. Ее можно скопировать в Google Translate или читать со словарем.
2. Ищем видео с субтитрами
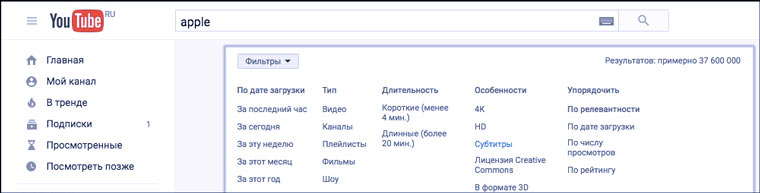
Если Downsub выдал сообщение об отсутствии субтитров, то можно попробовать поискать на YouTube его копию, но уже с субтитрами. Это можно сделать с помощью расширенного поиска.
3. Автоматически создаем субтитры
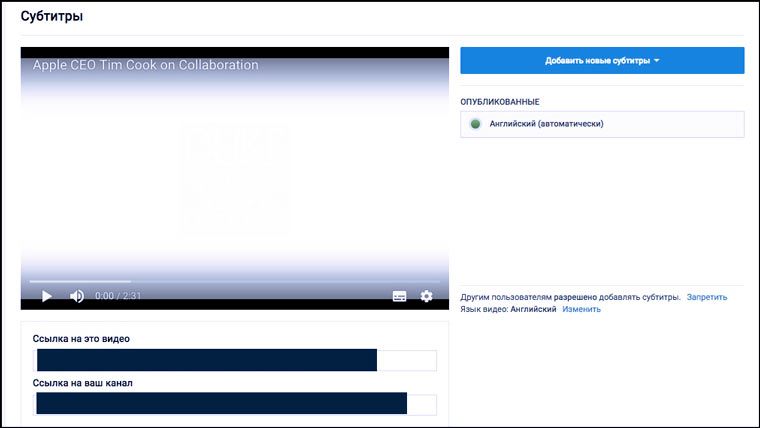
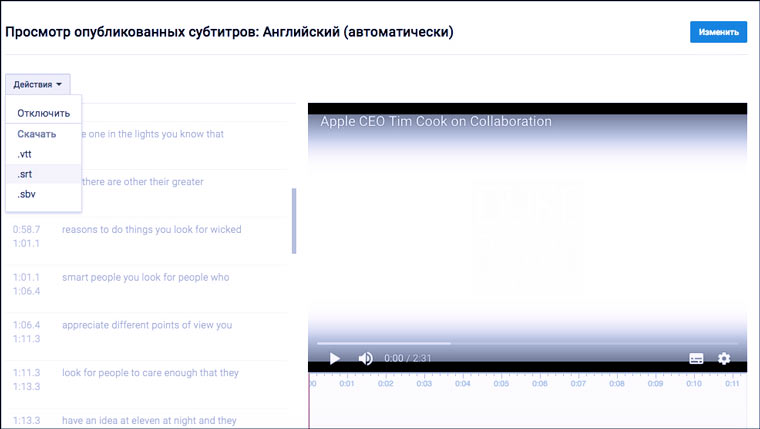
Если версии с субтитрами для интересного вас видео на YouTube нет, то можно загрузить оригинальный файл на свой канал (не забудьте указать настройку «Доступ по ссылке» или «Ограниченный доступ») и воспользоваться функцией автоматического создания субтитров.
Если у вас нет исходного файла с роликом, а есть только ссылка на него, то попробуйте скачать его с помощью сайта ru.savefrom.net.
Как автоматически создать субтитры? Очень просто. YouTube самопроизвольно пытается транслировать в текст все видео на русском, английском, французском, немецком, испанском, итальянском, нидерландском, португальском, корейском и японском.
Ссылка на автоматически созданные субтитры появляется через некоторое время после загрузки видео. Для трехминутного ролика их пришлось ждать больше пяти минут. Субтитры для видео, которые размещены на вашем канале можно скачать непосредственно с YouTube.
Иногда текст получается вполне себе соответствующим видео. Но если речь в нем звучит непонятно, то результат может рассмешить и удивить. Справка YouTube предупреждает, что для роликов совсем плохого качества автоматически субтитры могут так и не сгенерироваться.
Этот способ — неплохой лайфхак для студентов. Задали посмотреть трехчасовое видео с лекцией? Автоматически созданный файл с субтитрами и Command+F поможет быстро найти в каких отрезках ролика освещаются нужные вам темы.
4. Конвертируем аудио в видео
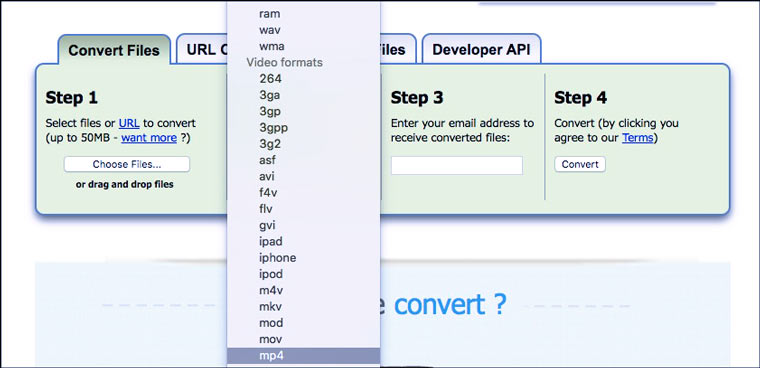
5. Преобразуем речь в текст
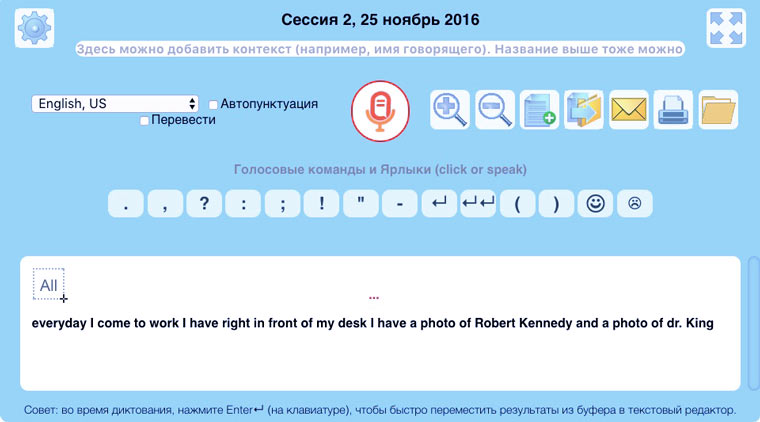
Если вам не нужно переводить все видео целиком, а только понять только короткие отдельные фрагменты, то удобнее воспользоваться плагином SpeechLogger для браузера Google Chrome.
Естественно, с его помощью можно преобразовать в текст и весь ролик. В плагине удобно работать с кусочками текста (записывать по одной фразе и сразу корректировать ошибки).
Готовый результат можно сохранить на Google Drive или скачать себе на компьютер для дальнейшего редактирования.
Как и в случае с автоматическими субтитрами, качество результата — лотерея. Неторопливая речь человека с хорошей дикцией на простую бытовую тему может распознаваться на отлично. А быстрый монолог с фоновыми шумами плагин может проигнорировать.
6. Меняем настройки воспроизведения

Способ очень банальный, но очень действенный. Если в два раза уменьшить скорость воспроизведения, то звук воспринимается совершенно по другому. Это касается не только людей, но и плагинов/приложений для распознавания речи. Чем медленнее темп, тем меньше они делают ошибок.
7. Пробуждаем свой мозг

Этот способ подходит для тех, кто очень хорошо понимает печатный текст на иностранном языке, но немного тормозит с пониманием устной речи. Такое бывает, когда статьи и книги приходится читать каждый день, а смотреть видео/слушать аудио гораздо реже или почти никогда.
Перед просмотром ролика на какую-то тему надо взять несколько статей на эту же тему (чтоб терминов побольше) и прослушать их с помощью плагина SpeakIt. При этом не забывать внимательно вчитываться в текст и соотносить его со звуком. В настройках расширения можно поменять женский голос на мужской, который звучит приятнее и понятнее.
Кому-то достаточно 20 минут, чтобы проснулись навыки понимания устной речи (при условии, что вы их когда-то отрабатывали), а кому-то ощутимо больше. Эффект такой же, как при визите в другую страну. Сначала легкий шок, но в течении нескольких дней все слова и фразы, которые когда-то были выучены вспоминаются и речь людей вокруг из шумового фона постепенно превращается в нечто осмысленное и понятное.
В заключении стоит напомнить, что перевод — совсем недорогая услуга. В случае с английским это будет стоить не более 100 рублей за каждую минуту расшифровки аудио/видео + 200–400 рублей за страницу переведенного текста. Для других языков выйдет немного дороже.
Как написать годный текст на английском, если плохо знаешь язык
Как я научилась читать французские и английские книги
Как превратить голос в текст: тестируем 5 сервисов для расшифровки
Я работаю с текстом и мечтаю о программе, которая сможет превратить голос в напечатанные слова.
Например, расшифрует за меня интервью длиной в несколько часов. Или позволит наговорить идеи, а в ответ пришлет заметку. Наконец, «напишет» за меня смс: поймет несколько обрывистых фраз и отправит адресату текст — потому что голосовые сообщения любят не все.
Я протестировал 5 таких сервисов: наговорил один и тот же текст, а потом сравнил результаты. Я использовал два способа: сначала давал программе послушать и расшифровать живой голос, а потом — в записи.
Текст для теста
Вот текст для теста: «Привет. Это тестовая запись для статьи об инструментах, которые умеют превращать голос в текст. Как думаете, этот сервис справится? Распознает интонацию вопроса и, например, числа — один, два, три? Вот что получилось».
Google Keep
Где работает: Android, iOS
Сколько стоит: бесплатно
Что умеет. Это приложение для создания и хранения заметок можно использовать как расшифровщик. Если на главном экране нажать на иконку микрофона и начать говорить, то сервис будет переводить звук в текст — это называется транскрибацией. Загрузить и расшифровать аудиофайл не получится.
У сервиса есть еще один минус: запись останавливается, если молчать две-три секунды, поэтому расшифровывать длинные интервью не получится. Разве что делать это небольшими кусками. Наговорить несколько идей и получить их в блокноте получится отлично.
Результат. Я проверил два способа: наговорил текст самостоятельно и включил запись того же текста через колонку — никакой разницы нет. Вышло хорошо: сервис не распознал только знаки препинания и напечатал числа без пробелов.
Сообщения «Вконтакте»
Где работает: Android, iOS
Сколько стоит: бесплатно
Что умеет. В мобильном приложении соцсеть умеет расшифровывать входящие голосовые сообщения. Это можно использовать и в наших целях: отправлять сообщения самому себе.
Для этого зайдите в раздел с диалогами и в поисковом окне вбейте свое имя. Дальше зажмите значок микрофона и наговорите сообщение. Когда оно появится в диалоговом окне, нажмите на «Аа» справа от записи.
Результат. «Вконтакте» расшифровал живой голос с ошибками в склонениях и перепутал несколько слов: например, «сервис» услышал как «серый». Но справился с числами. Записанный и пропущенный через колонку голос сервис расшифровал намного хуже — получился набор слов, который нужно буквально переписывать.
Закадровый перевод англоязычных видео в Яндекс.Браузере
О технологии автоматического закадрового перевода англоязычных видео в Интернете от Яндекса, появившейся в Яндекс.Браузере. Что являет собой эта технология, как её включить на YouTube.

Не успели ещё мы, пользователи Интернета привыкнуть к тому, что автоматический перевод веб-страниц в браузерах – сегодня это уже вещь вполне достойного уровня, с помощью которой мы можем как минимум понять суть изложенного в текстах на иностранном языке, как технологии автоматизации перевода шагнули ещё дальше. И замахнулись они на закадровый перевод видеороликов, выложенных в Интернете. Относительно недавно Яндекс представил интегрированную в свой браузер Яндекс.Браузер технологию автоматического голосового перевода англоязычных видео на YouTube, Vimeo и некоторых других интернет-площадках. Что за функция, и как она работает?
Цель создания Яндексом закадрового автоматического перевода видео в Интернете – сделать англоязычные видео доступными русскоязычным пользователям. Далеко не все русскоязычные владеют английским языком на должном уровне, чтобы понимать происходящее в обучающих, технических, научных и т.п. видео. Единственным решением, как русскоязычным смотреть YouTube-видео на английском, до недавнего времени были только субтитры. Но всерьёз рассматривать инструмент субтитров на YouTube можно, если только они созданы не автоматически, а на каналах, где авторы занимаются субтитрами и редактируют их. А таких немного. Предложенная Яндексом технология, во-первых, решает проблему низкого качества самого перевода субтитров за счёт реализации своих механизмов распознавания речи и перевода. Во-вторых, предлагает закадровый перевод, т.е. перевод с переозвучиванием видео. Переозвучивание базируется на механизме синтезирования речи Яндекса. Выполнено по принципу профессионального закадрового перевода: оригинальный звук заглушается и поверх него пускаются русскоязычные голосовые движки, озвучивающие переведённую речь. Технология закадрового перевода распознаёт оригинальные женские и мужские голоса и переозвучивает их, соответственно, женским и мужским голосовыми движками. Где, кстати, в женском голосовом движке каждый узнает голос Алисы – голосового ассистента Яндекс.Браузера. Также технология учитывает темп речи говорящих в оригинале.
Технология закадрового перевода интегрирована в Яндекс.Браузер, пока что её без проблем можно обнаружить только в десктопной версии браузера, но также она может быть доступна уже и на некоторых мобильных устройствах. В любом случае необходима последняя актуальная версия Яндекс.Браузера. В десктопной версии при открытии видео, где поддерживается закадровый перевод, увидим его кнопку «Перевести видео» в числе функций на самом видео. Кликаем эту кнопку.

Если ролик непродолжительный, закадровый перевод начнётся практически мгновенно. Если ролик длинный, придётся немного подождать, при больших объёмах обработки данных технологии нужно какое-то время на перевод и озвучку. В общем принцип работы перевода видео таков: при включении этой функции в видеоролике в фоне запускается распознавание речи, далее текст переводится, затем озвучивается голосовыми движками с применением мужского и женского голоса, а также различных темпов их воспроизведения. При этом закадровый перевод осуществляется максимально синхронно, насколько это возможно сделать автоматически. Для этого в процессе перевода учитываются временные отрезки оригинального звучания и в соответствии с ними запускается переозвучивание голосовыми движками.
Пока что технология работает только для видеороликов на английском языке. И только для видео, которые выложены в общем доступе. Использовать её предпочтительнее для видео разговорного жанра, но иногда она кое-как справляется с переводом текста в музыкальных клипах и видео концертов. Где-то с неточностями перевода, где-то с пропуском больших отрезков речи, но справляется. Но в каких-то видеороликах закадровый перевод работать не будет. Это могут быть музыкальные видео, видео с плохим звучанием и прочие случаи, где механизм распознавания речи столкнётся с какими-то трудностями.

В целом же Яндексу большой зачёт, весьма неплохо как для первых наработок. Остаётся надеться, что и идея, и её технология не будут заброшены, а будут эволюционировать. В процессе эволюции избавятся от шероховатостей и угловатостей и превратятся в годный качественный продукт отечественного производства.
Как узнать на каком языке говорят в видео



Как правило, по объёму оригинальный текст должен примерно совпадать с переводом в каждой ячейке. Чем короче отрывок, тем ближе должно быть соответствие. Если текста слишком много, диктору придётся читать в очень высоком темпе. Если же мало, появятся чересчур долгие паузы и хвосты. Чтобы избежать этого, редактор просматривает перевод, сверяет его с видеорядом, и корректирует укладку. В идеале во время самой записи на укладке уже не останавливаются.
В сравнении с другими языками английский — довольно емкий. Нередко перевод с английского на десять-двадцать процентов длиннее оригинала, особенно в случае с русским и арабским языками. Если бюджет проекта позволяет, видео можно удлинить из-за большого объёма переводного текста. Но чаще всего дополнительной редакции видео мы стараемся избегать, вместо этого сокращаем перевод. В некоторых же случаях, если, например, видео состоит из неподвижных графиков и диаграмм, увеличение продолжительности видео — недорогая альтернатива редактуре текста.



Взгляд на продукт конечного пользователя — важная часть локализации видео. «Клиент» и «конечный пользователь» — это разные люди. Первый заказывает проект, а второй непосредственно с ним взаимодействует. В офисе клиента, например, во Франции и Китае лучше разбираются в уместной для их аудитории терминологии, а также в том, какие правила и законы, упомянутые в видео, применимы в их стране. Материал, специфичный лишь для страны производителя, при локализации видеоролика можно опустить.
Привлекаем к созданию образовательного продукта будущих пользователей. Тестировщик должен быть в курсе ограничений тайминга, а также рекомендаций по произношению, в частности аббревиатур. Тестирование необходимо, чтобы проверить, отшлифован ли проект до блеска. Соответственно, поправки со стороны клиента должны быть минимальны. Большая часть работы лежит на плечах локализаторов.
Важный шаг — кастинг дикторов. Для коммерческих видео достаточно одного диктора, для обучающих же программ чаще всего требуется несколько голосов. Вовлекаем в выбор дикторов конечного пользователя. От диалекта и акцента говорящего зависит успех финального продукта — если вас устраивает речь диктора, не факт, что носители языка воспримут её так же. Для озвучания программы, транслируемой в Техасе, не возьмут британского диктора, так же как и для проекта в Анголе не подойдёт актёр из Бразилии.
Обращаем внимание на местные традиции озвучания. Женщина-диктор уместна практически для любой программы в США или Европе, но в других странах женский закадровый голос могут воспринимать иначе. Опять же узнаём требования конечного пользователя.
Составляем список персонажей и определяем минимальное требуемое количество голосов. Часто это количество зависит от вида озвучания. Если на видео — интервью, двух-трёх голосов будет достаточно, например, мужской голос для мужских персонажей, женский — для женских и один актёр-рассказчик. При липсинке, смысл которого — создать впечатление, словно человек на экране на самом деле говорит на языке перевода, все персонажи должны звучать разными голосами. Иногда для создания этого эффекта достаточно, чтобы один диктор не озвучивал двух персонажей, пока те одновременно находятся в кадре.
Распознавание речи для чайников

В этой статье я хочу рассмотреть основы такой интереснейшей области разработки ПО как Распознавание Речи. Экспертом в данной теме я, естественно, не являюсь, поэтому мой рассказ будет изобиловать неточностями, ошибками и разочарованиями. Тем не менее, главной целью моего «труда», как можно понять из названия, является не профессиональный разбор проблемы, а описание базовых понятий, проблем и их решений. В общем, прошу всех заинтересовавшихся пожаловать под кат!
Пролог
Начнём с того, что наша речь — это последовательность звуков. Звук в свою очередь — это суперпозиция (наложение) звуковых колебаний (волн) различных частот. Волна же, как нам известно из физики, характеризуются двумя атрибутами — амплитудой и частотой.

Для того, что бы сохранить звуковой сигнал на цифровом носителе, его необходимо разбить на множество промежутков и взять некоторое «усредненное» значение на каждом из них.
Таким вот образом механические колебания превращаются в набор чисел, пригодный для обработки на современных ЭВМ.
Отсюда следует, что задача распознавания речи сводится к «сопоставлению» множества численных значений (цифрового сигнала) и слов из некоторого словаря (русского языка, например).
Давайте разберемся, как, собственно, это самое «сопоставление» может быть реализовано.
Входные данные
Допустим у нас есть некоторый файл/поток с аудиоданными. Прежде всего нам нужно понять, как он устроен и как его прочесть. Давайте рассмотрим самый простой вариант — WAV файл.
Формат подразумевает наличие в файле двух блоков. Первый блок — это заголовка с информацией об аудиопотоке: битрейте, частоте, количестве каналов, длине файла и т.д. Второй блок состоит из «сырых» данных — того самого цифрового сигнала, набора значений амплитуд.
Логика чтения данных в этом случае довольно проста. Считываем заголовок, проверяем некоторые ограничения (отсутствие сжатия, например), сохраняем данные в специально выделенный массив.
Распознавание
Чисто теоретически, теперь мы можем сравнить (поэлементно) имеющийся у нас образец с каким-нибудь другим, текст которого нам уже известен. То есть попробовать «распознать» речь… Но лучше этого не делать 🙂
Наш подход должен быть устойчив (ну хотя бы чуть-чуть) к изменению тембра голоса (человека, произносящего слово), громкости и скорости произношения. Поэлементным сравнением двух аудиосигналов этого, естественно, добиться нельзя.
Поэтому мы пойдем несколько иным путём.
Фреймы
Первым делом разобьём наши данные по небольшим временным промежуткам — фреймам. Причём фреймы должны идти не строго друг за другом, а “внахлёст”. Т.е. конец одного фрейма должен пересекаться с началом другого.
Фреймы являются более подходящей единицей анализа данных, чем конкретные значения сигнала, так как анализировать волны намного удобней на некотором промежутке, чем в конкретных точках. Расположение же фреймов “внахлёст” позволяет сгладить результаты анализа фреймов, превращая идею фреймов в некоторое “окно”, движущееся вдоль исходной функции (значений сигнала).
Опытным путём установлено, что оптимальная длина фрейма должна соответствовать промежутку в 10мс, «нахлёст» — 50%. С учётом того, что средняя длина слова (по крайней мере в моих экспериментах) составляет 500мс — такой шаг даст нам примерно 500 / (10 * 0.5) = 100 фреймов на слово.
Разбиение слов
Первой задачей, которую приходится решать при распознавании речи, является разбиение этой самой речи на отдельные слова. Для простоты предположим, что в нашем случае речь содержит в себе некоторые паузы (промежутки тишины), которые можно считать “разделителями” слов.
Как вы уже догадались, речь сейчас пойдёт о последнем пункте 🙂 Начнём с того, что энтропия — это мера беспорядка, “мера неопределённости какого-либо опыта” (с). В нашем случае энтропия означает то, как сильно “колеблется” наш сигнал в рамках заданного фрейма.
И так, мы получили значение энтропии. Но это всего лишь ещё одна характеристика фрейма, и для того, что бы отделить звук от тишины, нам по прежнему нужно её с чем-то сравнивать. В некоторых статьях рекомендуют брать порог энтропии равным среднему между её максимальным и минимальным значениями (среди всех фреймов). Однако, в моём случае такой подход не дал сколь либо хороших результатов.
К счастью, энтропия (в отличие от того же среднего квадрата значений) — величина относительно самостоятельная. Что позволило мне подобрать значение её порога в виде константы (0.1).
Тем не менее проблемы на этом не заканчиваются 🙁 Энтропия может проседать по середине слова (на гласных), а может внезапно вскакивать из-за небольшого шума. Для того, что бы бороться с первой проблемой, приходится вводить понятие “минимально расстояния между словами” и “склеивать” близ лежачие наборы фреймов, разделённые из-за проседания. Вторая проблема решается использованием “минимальной длины слова” и отсечением всех кандидатов, не прошедших отбор (и не использованных в первом пункте).
Если же речь в принципе не является “членораздельной”, можно попробовать разбить исходный набор фреймов на определённым образом подготовленные подпоследовательности, каждая из которых будет подвергнута процедуре распознавания. Но это уже совсем другая история 🙂
И так, мы у нас есть набор фреймов, соответствующих определённому слову. Мы можем пойти по пути наименьшего сопротивления и в качестве численной характеристики фрейма использовать средний квадрат всех его значений (Root Mean Square). Однако, такая метрика несёт в себе крайне мало пригодной для дальнейшего анализа информации.
Давайте рассмотрим процесс вычисления MFCC коэффициентов для некоторого фрейма.
Представим наш фрейм в виде вектора , где N — размер фрейма.
Разложение в ряд Фурье
Первым делом рассчитываем спектр сигнала с помощью дискретного преобразования Фурье (желательно его “быстрой” FFT реализацией).
Так же к полученным значениям рекомендуется применить оконную функцию Хэмминга, что бы “сгладить” значения на границах фреймов.
То есть результатом будет вектор следующего вида:
Важно понимать, что после этого преобразования по оси Х мы имеем частоту (hz) сигнала, а по оси Y — магнитуду (как способ уйти от комплексных значений):
Расчёт mel-фильтров
Начнём с того, что такое mel. Опять же согласно Википедии, mel — это “психофизическая единица высоты звука”, основанная на субъективном восприятии среднестатистическими людьми. Зависит в первую очередь от частоты звука (а так же от громкости и тембра). Другими словами, эта величина, показывающая, на сколько звук определённой частоты “значим” для нас.
Преобразовать частоту в мел можно по следующей формуле (запомним её как «формула-1»):
Обратное преобразование выглядит так (запомним её как «формула-2»):
График зависимости mel / частота:
Но вернёмся к нашей задаче. Допустим у нас есть фрейм размером 256 элементов. Мы знаем (из данных об аудиоформате), что частота звука в данной фрейме 16000hz. Предположим, что человеческая речь лежит в диапазоне от [300; 8000]hz. Количество искомых мел-коэффициентов положим M = 10 (рекомендуемое значение).
Для того, что бы разложить полученный выше спектр по mel-шкале, нам потребуется создать “гребёнку” фильтров. По сути, каждый mel-фильтр это треугольная оконная функция, которая позволяет просуммировать количество энергии на определённом диапазоне частот и тем самым получить mel-коэффициент. Зная количество мел-коэффициентов и анализируемый диапазон частот мы можем построить набор таких вот фильтров:
Обратите внимание, что чем больше порядковый номер мел-коэффициента, тем шире основание фильтра. Это связано с тем, что разбиение интересующего нас диапазона частот на обрабатываемые фильтрами диапазоны происходит на шкале мелов.
Но мы опять отвлеклись. И так для нашего случая диапазон интересующих нас частот равен [300, 8000]. Согласно формуле-1 в на мел-шкале этот диапазон превращается в [401.25; 2834.99].
Далее, для того, что бы построить 10 треугольных фильтров нам потребуется 12 опорных точек:
m[i] = [401.25, 622.50, 843.75, 1065.00, 1286.25, 1507.50, 1728.74, 1949.99, 2171.24, 2392.49, 2613.74, 2834.99]
Обратите внимание, что на мел-шкале точки расположены равномерно. Переведём шкалу обратно в герцы с помощью формулы-2:
h[i] = [300, 517.33, 781.90, 1103.97, 1496.04, 1973.32, 2554.33, 3261.62, 4122.63, 5170.76, 6446.70, 8000]
Как видите теперь шкала стала постепенно растягиваться, выравнивая тем самым динамику роста “значимости” на низких и высоких частотах.
Теперь нам нужно наложить полученную шкалу на спектр нашего фрейма. Как мы помним, по оси Х у нас находится частота. Длина спектра 256 — элементов, при этом в него умещается 16000hz. Решив нехитрую пропорцию можно получить следующую формулу:
что в нашем случае эквивалентно
f(i) = 4, 8, 12, 17, 23, 31, 40, 52, 66, 82, 103, 128
Вот и всё! Зная опорные точки на оси Х нашего спектра, легко построить необходимые нам фильтры по следующей формуле:
Применение фильтров, логарифмирование энергии спектра
Применение фильтра заключается в попарном перемножении его значений со значениями спектра. Результатом этой операции является mel-коэффициент. Поскольку фильтров у нас M, коэффициентов будет столько же.
Однако, нам нужно применить mel-фильтры не к значениям спектра, а к его энергии. После чего прологарифмировать полученные результаты. Считается, что таким образом понижается чувствительность коэффициентов к шумам.
Косинусное преобразование
Дискретное косинусное преобразование (DCT) используется для того, что бы получить те самые “кепстральные” коэффициенты. Смысл его в том, что бы “сжать” полученные результаты, повысив значимость первых коэффициентов и уменьшив значимость последних.
В данном случае используется DCTII без каких-либо домножений на (scale factor).
Теперь для каждого фрейма мы имеем набор из M mfcc-коэффициентов, которые могут быть использованы для дальнейшего анализа.
Примеры код для вышележащих методов можно найти тут.
Алгоритм распознавания
Вот тут, дорогой читатель, тебя и ждёт главное разочарование. В интернетах мне довелось увидеть множество высокоинтеллектуальных (и не очень) споров о том, какой же способ распознавания лучше. Кто-то ратует за Скрытые Марковские Модели, кто-то — за нейронные сети, чьи-то мысли в принципе невозможно понять 🙂
В любом случае немало предпочтений отдаётся именно СММ, и именно их реализацию я собираюсь добавить в свой код… в будущем 🙂
На данный момент, предлагаю остановится на гораздо менее эффективном, но в разы более простом способе.
И так, вспомним, что наша задача заключается в распознавании слова из некоторого словаря. Для простоты, будем распознавать называния первых десять цифр: “один“, “два“, “три“, “четыре“, “пять“, “шесть“, “семь“, “восемь“, “девять“, “десять“.
Теперь возьмем в руки айфон/андроид и пройдёмся по L коллегам с просьбой продиктовать эти слова под запись. Далее поставим в соответствие (в какой-нибудь локальной БД или простом файле) каждому слову L наборов mfcc-коэффициентов соответствующих записей.
Это соответствие мы назовём “Модель”, а сам процесс — Machine Learning! На самом деле простое добавление новых образцов в базу имеет крайне слабую связь с машинным обучением… Но уж больно термин модный 🙂
Однако, одно и тоже слово может произносится как Андреем Малаховым, так и каким-нибудь его эстонским коллегой. Другими словами размер mfcc-вектора для одного и того же слова может быть разный.
К счастью, задача сравнения последовательностей разной длины уже решена в виде Dynamic Time Warping алгоритма. Этот алгоритм динамическо программирования прекрасно расписан как в буржуйской Wiki, так и на православном Хабре.
Единственное изменение, которое в него стоит внести — это способ нахождения дистанции. Мы должны помнить, что mfcc-вектор модели — на самом деле последовательность mfcc-“подвекторов” размерности M, полученных из фреймов. Так вот, DTW алгоритм должен находить дистанцию между последовательностями эти самых “подвекторов” размерности M. То есть в качестве значений матрицы расстояний должны использовать расстояния (евклидовы) между mfcc-“подвекторами” фреймов.
Эксперименты
У меня не было возможности проверить работу данного подхода на большой “обучающей” выборке. Результаты же тестов на выборке из 3х экземпляров для каждого слова в несинтетических условиях показали мягко говоря нелучший результат — 65% верных распознаваний.
Тем не менее моей задачей было создание максимального простого приложения для распознавания речи. Так сказать “proof of concept” 🙂
Реализация
Внимательный читатель заметил, что статья содержит множество ссылок на GitHub-проект. Тут стоит отметить, что это мой первый проект на С++ со времён университета. Так же это моя первая попытка рассчитать что-то сложнее среднего арифметического со времён того же университета… Другими словами it comes with absolutely no warranty (с) 🙂