Как получить список всех таблиц в базе данных Microsoft SQL Server?
Если у Вас встала задача определить количество таблиц в базе данных Microsoft SQL Server, то данная статья Вам поможет, так как в ней мы рассмотрим несколько способов реализации того, как можно получить список всех пользовательских таблиц, включая некоторые их характеристики с помощью SQL запроса.

Всю информацию о таблицах и других объектах SQL сервера можно посмотреть в графической среде SQL Server Management Studio, но иногда требуется выгрузить данную информацию или просто получить к ней доступ, для того чтобы использовать ее, например, в своих SQL инструкциях, это можно сделать несколькими способами, и сейчас мы их рассмотрим.
Получаем список всех таблиц с помощью представления информационной схемы
В Microsoft SQL Server есть специальная схема, предназначенная для получения информации о метаданных — это INFORMATION_SCHEMA. Подробно о ней мы говорили в материале – «Представления информационной схемы Microsoft SQL Server».
Для того чтобы получить информацию о таблицах в БД, существует представление информационной схемы TABLES. Допустим, нам нужно получить просто перечень таблиц, для этого пишем следующий SQL запрос (в моей тестовой базе всего одна таблица).
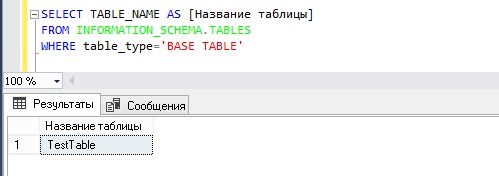
В данном случае мы указали условие table_type=’BASE TABLE’, так как данное представление содержит еще и информацию о представлениях (VIEW).
Недостатком данного способа является то, что никакой больше полезной информации в представлении INFORMATION_SCHEMA.TABLES нет.
Получаем список всех таблиц с помощью системного представления sys.tables
Альтернативным способом и более удачным, если Вам нужна дополнительная информация о таблицах, является способ с использованием системного представления sys.tables. Давайте сейчас с помощью этого представления выведем список таблиц, а также получим дополнительные сведения о дате создания таблицы и дате последнего редактирования этой таблицы.
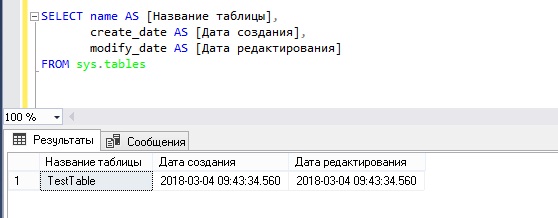
Получаем список всех таблиц с помощью системной процедуры
Еще одним способом получения списка таблиц в базе данных Microsoft SQL Server является использование системной процедуры sp_Tables, но, на мой взгляд, данный способ менее удобный, к тому же он возвращает также немного сведений, по сути, только название таблиц.
Для того чтобы получить сведения о таблицах в БД нам нужно указать параметр @table_type со значением ‘TABLE’, так как данная процедура возвращает еще данные о представлениях и системных таблицах. Следует обратить внимание на то, что значение параметра нужно заключать в двойные кавычки, а каждое значение типа в одиночные кавычки, так как через запятую возможно указывать несколько типов (например, для того чтобы получить таблицы и представления, в значение параметра нужно указать — «‘TABLE’, ‘VIEW’»). Также мы укажем параметр @table_owner, для того чтобы ограничиться одним владельцем.
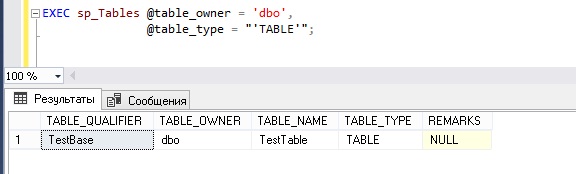
Вот мы с Вами и рассмотрели три возможности получения списка таблиц в Microsoft SQL Server. Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу «SQL код» – это самоучитель по языку SQL, которую написал я, и в которой я подробно, и в то же время простым языком, рассказываю о языке SQL.
Заметка! Для профессионального изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL.
Базы данных
Про Postgresql есть отдельная статья

Подключение к базе даных MySQL
Из консоли наберите
Нажмите Enter и введите пароль.
Если вы подлючаетеся к базе данных своего сайта и не знаете ip сделайте в консоли.
Например, сайт andreyolegovich.ru имеет IP 87.236.19.34

После ввода пароля должно появиться приветствие MySQL

Посмотреть все базы данных можно с помощью команды
Обратите внимание на точку с запятой в конце
Выбрать определённую БД
Как узнать какие таблицы находятся в БД MySQL
Посмотреть список содержащихся в БД таблиц
Как посмотреть содержимое таблицы MySQL
Посмотреть структуру определённой таблицы
Посмотреть содержание определённой таблицы
Упорядоченный по ID вывод таблицы имя_таблицы
SELECT * FROM имя_таблицы ORDER BY ID;
В обратном порядке:
SELECT * FROM имя_таблицы ORDER BY ID DESC;
Запрос с условием показать только китайских производителей
SELECT * FROM table_manuf WHERE (country=’China’);
Запрос с условием показать только страны с кодом 7 или 358
SELECT * FROM table_countries WHERE (code=’7′ OR code=’358′);
Как переименовать таблицу MySQL
Переименовать таблицу car в auto с помощью ALTER TABLE (mysql.ru)
ALTER TABLE car RENAME auto;
Как добавить столбец в таблицу MySQL
Добавить новый столбец типа TEXT с именем Body:
ALTER TABLE имя_таблицы ADD Body text;
Как добавить строку в таблицу БД
Добавляем запись в таблицу с названием Имя_таблицы
INSERT INTO Имя_таблицы VALUES(100, ‘Компания’, ‘Страна’, ‘Что-то ещё’);
Как удалить строку в таблице БД
Удалить строку с ID 1 в таблице с названием Имя_таблицы
DELETE FROM Имя_таблицы WHERE ;
Как изменить значение в таблице MySQL
Изменить поле Country на Russia у записи с ID 7
UPDATE имя_таблицы SET Country = ‘Russia’ WHERE ;
Как найти все таблицы с определённым столбцом
Ищем по всей базе данных таблицы у которых есть столбец с именем Name
SELECT TABLE_NAME FROM INFORMATION_SCHEMA.COLUMNS WHERE COLUMN_NAME = ‘Name’;
Как обратиться к базе данных с помощью PHP
Ошибки
MS SQL
Вывести на экран список таблиц MS SQL
SELECT TABLE_NAME FROM information_schema.tables select table_name, column_name from information_schema.columns;
Ошибки MS SQL
server management studio error 4064
Если при попытке соединения с базой данных Вы получаете следующую ошибку:
Cannot open user default database. Login failed.
Login failed for user ‘UserName’. (Microsoft SQL Server, Error: 4064)

Перейдите в Options

Если в поле Connect to database: стоит замените его на имя Вашей базы данных.

В данном примере вместо andreyolegovich.ru_db должно быть имя базы данных, к которой Вы хотите подлючиться.

Postgres
Получить список таблиц Postgres
select table_name from information_schema.tables;
Получить список таблиц и столбцов Postgres
select table_name, column_name from information_schema.columns;
Получить список таблиц исключая служебные и отсортировать по имени таблицы
select table_name from information_schema.tables where table_schema=’public’ ORDER BY table_name;
Выбрать из таблицы диапазон значений
username нужно заменить на настоящее имя пользователя БД
Вполне возможен вариант, когда username и db_name одинаковые
Tables_in_db_name
Table01
Table02
CRUD — акроним, обозначающий четыре базовые функции, используемые при работе с базами данных: создание (англ. create), чтение (read), модификация (update), удаление (delete). Введён Джеймсом Мартином (англ. James Martin) в 1983 году[2] как стандартная классификация функций по манипуляции данными.
В SQL этим функциям, операциям соответствуют операторы Insert (создание записей), Select (чтение записей), Update (редактирование записей), Delete (удаление записей). В некоторых CASE-средствах использовались специализированные CRUD-матрицы или CRUD-диаграммы, в которых для каждой сущности указывалось, какие базовые функции с этой сущностью выполняет тот или иной процесс или та или иная роль. В системах, реализующих доступ к базе данных через API в стиле REST, эти функции реализуются зачастую (но не обязательно) через HTTP-методы PUT, GET, PATCH и DELETE соответственно.
Хотя традиционно оперирование в стиле CRUD применяется к базам данных, такой подход может быть распространён на любые хранимые вычислительные сущности (файлы, структуры в памяти, объекты). Шаблон проектирования ActiveRecord обеспечивает соответствие функций CRUD объектно-ориентированному подходу, и широко используется в различных фреймворках для доступа к базам данных из объектно-ориентированных языков программирования.
Ошибки при работе с Postgres
ERROR: update or delete on table » TABLE_NAME violates foreign key constraint » fk_ANOTHER_TABLE_SOME_id » on table » ANOTHER_TABLE » DETAIL: Key (id)=( SOME_ID ) is still referenced from table » ANOTHER_TABLE «. SQL state: 23503
Эта ошибка возникает в случае, когда Вы пытаетесь удалить что-то из реляционной базы данных и это что-то является ключом для элементов из другой таблицы.
Чтобы её обойти нужно удалить элементы другой таблицы ( ANOTHER_TABLE ) которые ссылаются на ту, из которой Вы хотите удалить ( TABLE_NAME ).
Вычислить эти элементы можно по значению Key ( SOME_ID )
Желательно убедиться, что все Ваши действия осознаны и не представляют угрозы базе данных.
Ошибки MySQL
Ошибка: 1064
ERROR 1064 (42000) at line 3: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘
Говорит о том, что в синтаксисе допущены ошибки. Допустим, Вы создаёте таблицу и задаёте столбцы неправильно.
id INT ; model VARCHAR(20) ; modified_time TIMESTAMP ; name VARCHAR(20) ;
Или не указали длину для VARCHAR
id INT, model VARCHAR, modified_time TIMESTAMP, name VARCHAR,
Это легко исправить
id INT, model VARCHAR(20), modified_time TIMESTAMP, name VARCHAR(20),
Изучите внимательно документацию по MySQL
Ошибка: Table X already exists
ERROR 1050 (42S01) at line 3: Table ‘tableName’ already exists
Исследуем базы данных с помощью T-SQL
Как dba и консультант по оптимизации производительности SQL Server в Ambient Consulting, я часто сталкиваюсь с необходимостью анализа узких мест производительности на экземплярах SQL Server, которые вижу первый раз в жизни. Это может быть сложной задачей. Как правило, у большинства компаний нет документации по их базам данных. А если есть, то она устарела, или же её поиск занимает несколько дней.
В этой статье я поделюсь базовым набором скриптов, раскапывающим информацию о метаданных с помощью системных функций, хранимых процедур, таблиц, dmv. Вместе они раскрывают все секреты баз данных на нужном экземпляре – их размер, расположение файлов, их дизайн, включая столбцы, типы данных, значения по умолчанию, ключи и индексы.
Если вы когда-нибудь пытались получить часть этой информации, с помощью GUI, я думаю вы будете приятно удивлены количеством той информации, которая, с помощью этих скриптов, получается мнгновенно.
Как и с любыми скриптами, сначала проверьте их в тестовом окружении, прежде чем запускать в продакшене. Я бы рекомендовал вам погонять их на тестовых базах MS, таких как AdventureWorks или pubs.
Ну, хватит слов, давайте я покажу скрипты!
Изучаем сервера
Начнём с запросов, предоставляющих информацию о ваших серверах.
Базовая информация
Во-первых, несколько простых @@Функций, которые предоставят нам базовую информацию.
Как долго ваш SQL Server работает после последнего перезапуска? Помните, что системная база данных tempdb пересоздаётся при каждом перезапуске SQL Server. Вот один из методов определения времени последнего перезапуска сервера.
Связанные сервера
Связанные сервера – это соединения, позволяющие SQL Server’у обращаться к другим серверам с данными. Распределённые запросы могут быть запущенны на разных связанных серверах. Полезно знать – является ли ваш сервер баз данных изолированным от других, или он связан с другими серверами.
Список всех баз данных
Во-первых, получим список всех баз данных на сервере. Помните, что на любом сервере есть четыре или пять системных баз данных (master, model, msdb, tempdb и distribution, если вы пользуетесь репликацией). Вы, вероятно, захотите исключить эти базы в следующих запросах. Очень просто увидеть список баз данных в SSMS, но, эти запросы будут нашими «строительными блоками» для более сложных запросов.
Есть несколько путей для получения списка всех БД на T-SQL и ниже вы увидите некоторые из них. Каждый метод возвращает похожий результат, но с некоторыми отличиями.
Последний бэкап?
Стоп! Прежде чем двигаться дальше, каждый хороший dba должен узнать есть ли у него свежий бэкап.
Будет лучше, если вы сразу узнаете путь к файлу с последним бэкапом.
Активные пользовательские соединения
Хорошо было бы понимать какие БД сейчас используются, особенно, если вы собираетесь разбираться с проблемами производительности.
Примечание переводчика: это будет работать только в SQL Server 2012 и выше, в предыдущих редакциях, в dmv sys.dm_exec_sessions отсутствовал столбец database_id. Чтобы узнать в каких БД в данный момент работают пользователи, можно воспользоваться sp_who.
Изучаем базы данных
Давайте заглянем поглубже и посмотрим, как мы можем собрать информацию об объектах во всех ваших БД, используя различные представления каталога и dmv. Большинство из запросов, представленных в этом разделе, смотрят «внутрь» только одной БД, поэтому не забывайте выбирать нужную БД в SSMS или с помощью команды use database. Также помните, что вы всегда можете посмотреть в контексте какой БД будет выполнен запрос, с помощью select db_name().
Системная таблица sys.objects одна из ключевых для сбора информации об объектах, составляющих вашу модель данных.
Ниже представлен список типов объектов, информацию о которых мы можем получить (смотрите документацию на sys.objects в MSDN)
Другие представления каталога, такие как sys.tables и sys.views, обращаются к sys.objects и предоставляют информацию о конкретном типе объектов. С этими представлениями, плюс функцией OBJECTPROPERTY, мы можем получить огромное количество информации по каждому из объектов, составляющих нашу схему БД.
Расположение файлов баз данных
Физическое расположение выбранной БД, включая основной файл данных (mdf), и файл журнала транзакций (ldf), могут быть получены с помощью этих запросов.
Таблицы
Конечно, Object Explorer в SSMS показывает полный список таблиц в выбранной БД, но часть информации с помощью GUI получить сложнее, чем с помощью скриптов. Стандарт ANSI предполагает обращение к представлениям INFORMATION_SCHEMA, но они не предоставят информацию об объектах, которые не являются частью стандарта (такие как триггеры, extended procedures и т.д.), поэтому лучше использовать представления каталога SQL Server.
Количество записей в таблице
Если вы ничего не знаете о таблице, то все таблицы одинаково важны. Чем больше вы узнаёте о таблицах, тем больше вы их разделяете на условно более важные и условно менее важные. В целом, таблицы с огромным количеством записей чаще оказывают серьёзное влияние на производительность.
В SSMS мы можем нажать правой кнопкой мыши на любую таблицу, открыть свойства на вкладке Storage и увидеть количество записей в таблице.
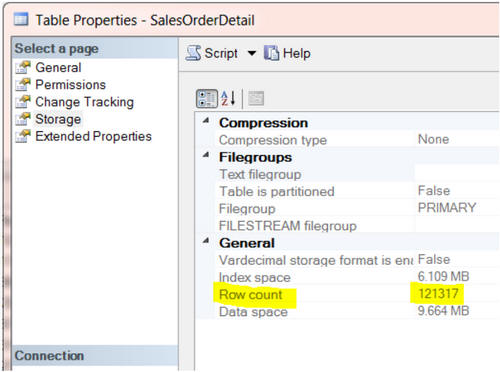
Довольно тяжело собрать вручную эту информацию обо всех таблицах. Опять же, если мы будем писать SELECT COUNT(*) FROM TABLENAME для каждой таблицы, нам придётся очень много печатать.
Намного удобнее использовать T-SQL для генерирования скрипта. Скрипт, приведённый ниже, сгенерирует набор инструкций T-SQL для получения количества строк в каждой таблице текущей базы данных. Просто выполните его, скопируйте результат в новое окно и запустите.
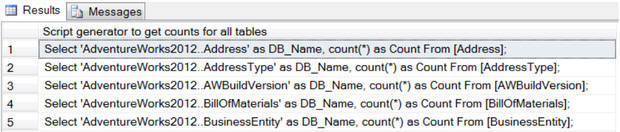
Примечание переводчика: у меня запрос не работал, добавил схему к имени таблицы.
sp_msForEachTable
Sp_msforeachtable – это недокументированная функция, которая «проходит» по всем таблицам в БД и выполняет запрос, подставляя вместо ‘?’ имя текущей таблицы. Так же существует похожая функция sp_msforeachdb, работающая на уровне баз данных.
Известно несколько проблем с этой недокументированной функцией, например, использование спецсимволов в именах объектов. Т.е. если имя таблицы или базы данных содержит знак ‘-‘, хранимая процедура, листинг которой ниже, завершится с ошибкой.
Самый быстрый способ получения количества записей – кластерный индекс
Все предыдущие метода использовали COUNT(*), который медленно отрабатывает, если в таблице больше чем 500K записей.
Самый быстрый способ получения количества записей в таблице – получать количество записей в кластерном индексе или куче. Помните, что хоть этот метод и самый быстрый, MS говорит, что информация о количестве записей индекса и реальное количество строк в таблице может не совпадать, из-за того, что на обновление информации требуется хоть и небольшое, но время. В большинстве же случаев, эти значения или одинаковы, или очень-очень близки и вскоре станут одинаковыми.
Поиск куч (таблиц без кластерных индексов)
Работа с кучами – это как работа с плоским файлом, вместо базы данных. Если вы хотите гарантированно получать полное сканирование таблицы при выполнении любого запроса, используйте кучи. Обычно я рекомендую добавлять primary key ко всем таблицам-кучам.
Разбираемся с активностью в таблице
При работах по оптимизации производительности, очень важно знать какие таблицы активно читаются, а в какие идёт активная запись. Ранее мы узнали сколько записей в наших таблицах, сейчас посмотрим как часто в них пишут и читают.
Помните, что эта информация из dmv, очищается при каждом перезапуске SQL Server. Чем дольше сервер работает, тем более надёжна статистика. Я чувствую себя намного более уверенно со статистикой, собранной за 30 дней, чем со статистикой, собранной за неделю.
Намного более продвинутая версия этого запроса представлена курсором, собирающим информацию по всем таблицам всех баз данных на сервере. Вообще, я не фанат курсоров из-за их невысокой производительности, но перемещение по разным базам данных – это отличное применение для них.
Примечание переводчика: курсор не отработает, если у вас в списке есть базы данных с состоянием, отличным от ONLINE.
Представления
Представления – это, условно говоря, запросы, хранящиеся в БД. Вы можете думать о них, как о виртуальных таблицах. Данные не хранятся в представлениях, но в наших запросах мы ссылаемся на них точно так же, как и на таблицы.
В SQL Server, в некоторых случаях, мы можем обновлять данные с использованием представления. Чтобы получить представление «только для чтения», можно использовать SELECT DISTINCT при его создании. Данные «через» представление можно менять только в том случае, если каждой строке представления соответствует только одна строка в «базовой» таблице. Любое представление, не отвечающее этому критерию, т.е. построенное на нескольких таблицах, или с использованием группировок, агрегатных функций и вычислений, будет доступно только для чтения.
Синонимы
Несколько раз в моей карьере я сталкивался с ситуацией, когда не мог понять к какой же таблице обращается запрос. Представьте простой запрос SELECT * FROM Client. Я ищу таблицу под именем Client, но я не могу найти её. Хорошо, думаю я, должно быть это представление, ищу представление с именем Client и всё равно не могу найти. Может быть я ошибся базой данных? В итоге выясняется, что Client – это синоним для покупателей и таблица, на самом деле, называется Customer. Отдел маркетинга хотел обращаться к этой таблице как к Client и из-за этого был создан синоним. К счастью, использование синонимов – это редкость, но разбирательства могут вызвать определённые затруднения, если вы к ним не готовы.
Хранимые процедуры
Хранимые процедуры – это группа скриптов, которые компилируются в единственный план выполнения. Мы можем использовать представления каталога, чтобы определить какие ХП созданы, какие действия они выполняют и над какими таблицами.
Добавив простое условие в WHERE мы можем получить информацию только о тех хранимых процедурах, которые, например, выполняют операции INSERT.
Немного модифицировав условие в WHERE, мы можем собрать информацию о ХП, производящих обновление, удаление или же обращающихся к определённым таблицам.
Функции
Функции хранятся в SQL Server, принимают какие-либо параметры и выполняют определённые действия, либо вычисления, после чего возвращают результат.
Триггеры
Триггер – это что-то вроде хранимой процедуры, которая выполняется в ответ на определённые действия с той таблицей, которой этот триггер принадлежит. Например, мы можем создать INSERT, UPDATE и DELETE триггеры.
CHECK-ограничения
CHECK-ограничения – это неплохое средство для реализации бизнес-логики в базе данных. Например, некоторые поля должны быть положительными, или отрицательными, или дата в одном столбце должна быть больше даты в другом.
Углубляемся в модель данных
Ранее, мы использовали скрипты, которые дали нам представление о «верхнем уровне» объектов, составляющих нашу базу данных. Иногда нам нужно получить больше данных о таблице, включая столбцы, их типы данных, какие значения по умолчанию заданы, какие ключи и индексы существуют (или должны существовать) и т.д.
Запросы, представленные в этом разделе, предоставляют средства почти что реверс-инжиниринга существующей модели данных.
Столбцы
Следующий скрипт описывает таблицы и столбцы из всей базы данных. Результат этого запроса, можно скопировать в Excel, где можно настроить фильтры и сортировку и хорошо разобраться с типами данных, использующимися в БД. Так же, обратите внимание на столбцы с одинаковыми именами, но разными типами данных.
Значения по умолчанию
Значение по умолчанию – это значение, которое будет сохранено, если никакого значения для столбца не будет задано при вставке. Зачастую, для столбцов хранящих дату ставят get_date(). Также, значения по умолчанию используются для аудита – вставляется system_user для определения учётной записи пользователя, совершившего определённое действие.
Вычисляемые столбцы
Вычисляемые столбцы – это столбцы, значения в которых вычисляются на основании, как правило, значений в других столбцах таблицы.
Столбцы identity
Столбцы IDENTITY автоматически заполняются системой уникальными значениями. Обычно используются для хранения порядкового номера записи в таблице.
Ключи и индексы
Как я писал ранее, наличие первичного ключа и соответствующего индекса у таблицы – это одна из best practice. Ещё одна best practice заключается в том, что внешние ключи так же должны иметь индекс, построенный по столбцам, входящим во внешний ключ. Индексы, построенные «по внешним ключам» отлично подходят для соединения таблиц. Эти индексы так же хорошо сказываются на производительности при удалении записей.
Какие индексы у нас есть?
Скрипт для поиска всех индексов во всех таблицах текущей БД.
Каких индексов не хватает?
На основании ранее исполнявшихся запросов, SQL Server предоставляет информацию об отсутствующих индексах в БД, создание которых может увеличить производительность.
Не добавляйте эти индексы вслепую. Я бы подумал о каждом из предложенных индексов. Использование включенных столбцов, например, может аукнуться серьёзным увеличением объёмов.
Внешние ключи
Внешние ключи определяют связь между таблицами и используются для контроля ссылочной целостности. На диаграмме сущность-связь линии между таблицами обозначают внешние ключи.
Пропущенные индексы по внешним ключам
Как я уже говорил, желательно иметь индекс, построенный по столбцам, входящим во внешний ключ. Это значительно ускоряет соединения таблиц, которые, обычно, всё равно соединяются по внешнему ключу. Эти индексы так же значительно ускоряют операции удаления. Если такого индекса нет, SQL Server будет производить table scan связанной таблицы, при каждом удалении записи из «первой» таблицы.
Зависимости
Это зависит… Я уверен, вы слышали это выражение раньше. Я рассмотрю три разных метода для «реверс-инжиниринга» зависимостей в БД. Первый метода – использовать хранимую процедуру sp_msdependecies. Второй – системные таблицы, связанные со внешними ключами. Третий метод – использовать CTE.
sp_msdependencies
Sp_msdependencies – это недокументированная хранимая процедура, которая может быть очень полезна для разбора сложных взаимозависимостей таблиц.
Если мы выведем все зависимости, используя sp_msdependencies, мы получим четыре столбца: Type, ObjName, Owner(Schema), Sequence.
Обратите внимание на номер последовательности (Sequence) – он начинается с 1 и последовательно увеличивается. Sequence – это «порядковый номер» зависимости.
Я несколько раз использовал этот метод, когда мне нужно было выполнить архивирование или удаление на очень большой БД. Если вы знаете зависимости таблицы, значит у вас есть «дорожная карта» — в каком порядке вам нужно архивировать или удалять данные. Начните с таблицы с самым большим значение в столбце Sequence и двигайтесь от него в обратном порядке – от большего к меньшему. Таблицы с одинаковым значением Sequence могут быть удалены одновременно. Этот метод не нарушает ни одного из ограничений внешних ключей и позволяет перенести/удалить записи без временного удаления и перестроения ограничений (constraints).
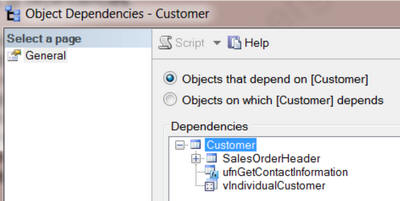
В SSMS, если вы нажмёте правой кнопкой мыши на имя таблицы, вы сможете выбрать «View Dependencies» и «Объекты, которые зависят от TABLENAME»:
Мы также можем получить эту информацию следующим способом:
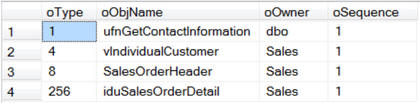
Если в SSMS, в окне просмотра зависимостей, выбрать «Объекты которые зависят от TABLENAME», а затем раскрыть все уровни, мы увидим следующее:
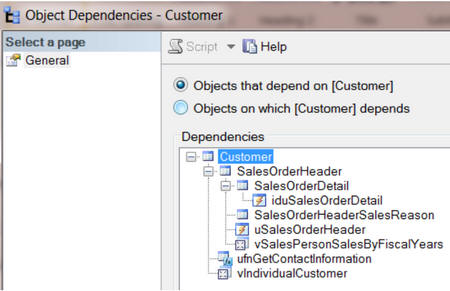
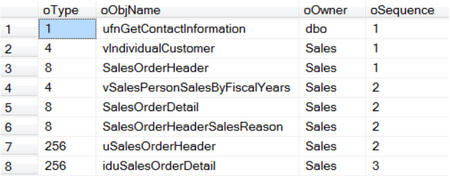
Ту же самую информацию вернёт sp_msdependencies.
Так же, в SSMS, мы можем увидеть от каких объектов зависит выбранная таблица.
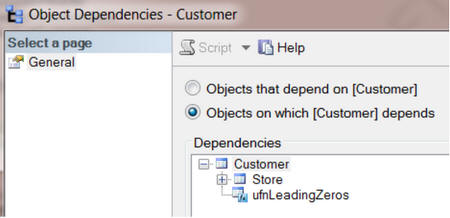
Следующий запрос, с использованием msdependencies, вернёт ту же самую информацию.
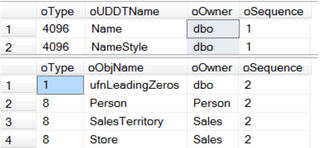
Если вы хотите получить список зависимостей таблиц, вы можете использовать временную таблицу, чтобы отфильтровать зависимости по типу.
Запросы к системным представлениям каталога
Второй метод «реверс-инжиниринга» зависимостей в вашей БД – это запросы к системным представлениям каталога, связанным со внешними ключами.
Использование CTE
Третий метод, для получения иерархии зависимостей – использование рекурсивного CTE.
Заключение
Таким образом, за час или два, можно получить неплохое представление о внутренностях любой базы данных, используя методы «реверс-инжиниринга», описанные выше.
Примечание переводчика: все запросы в тексте (за исключением одного, в тексте он отмечен) будут работать на SQL Server 2005 SP3 и в более поздних редакциях. Текст достаточно объёмный, я старался как мог его вычитать и найти свои ошибки (стилистические, синтаксические, смысловые и прочие), но, наверняка что-то не заметил, напишите мне в личку, пожалуйста, если что-то будет резать глаз.