FAQ: Как проверить кодировку в текстовом файле?
Учитывая, что многие инструменты по работе с текстом не отображают, в какой именно кодировке задан текст в текстовом файле и/или не поддерживают преобразование кодировок, то у новичков часто возникает вопрос о том, как именно привести кодировку текстового файла с русским текстом к понятному для SocialKit формату CP1251.
Следует сразу отметить, что большинство текстовых редакторов для ОС Windows (например, встроенный Блокнот и Wordpad) по умолчанию создают текстовые файлы именно с кодировкой по стандарту Windows-1251. Однако, эта кодировка по умолчанию может быть изменена в следствие тех или иных действий.
Если вы не уверены в том, в какой именно кодировке задан текст, то проще всего этот текст пересохранить через стандартный Блокнот Windows. При пересохранении Блокнот также покажет, в каком формате текст сейчас.
Опишем эту простую процедуру по шагам.
Пример текстового файла, в котором русский текст задан в формате UTF, но это не очевидно при открытии.
2. В открывшемся диалоговом окне вы сразу видите, в какой кодировке был сохранён текст в текстовом файле.
Диалоговое окно пересохранения текстового файла, в котором можно сразу изменить кодировку.
Как видно, в примере текст в текстовом файле был ранее сохранён в кодировке UTF-8. Для изменения кодировке достаточно выбрать в выпадающем списке кодировку ANSI и нажать кнопку «Сохранить«.
При этом зрительно для вас ничего не изменится, но многое изменится для программы и алгоритмов, занимающихся обработкой текста в процессе отправки. Корректно Instagram’у будет отправлен только ANSI-текст.
Выбор кодировки текста при открытии и сохранении файлов
Как правило, при совместной работе с текстовыми файлами нет необходимости вникать в технические аспекты хранения текста. Однако если необходимо поделиться файлом с человеком, который работает с текстами на других языках, скачать текстовый файл из Интернета или открыть его на компьютере с другой операционной системой, может потребоваться задать кодировку при его открытии или сохранении.
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
В этой статье
Общие сведения о кодировке текста
То, что отображается на экране как текст, фактически хранится в текстовом файле в виде числового значения. Компьютер преобразует числические значения в видимые символы. Для этого используется кодикон.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке «Кириллица (Windows)» знаку «Й» соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка «Кириллица (Windows)», компьютер считывает число 201 и выводит на экран знак «Й».
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка «Западноевропейская (Windows)», знак «Й» из исходного текстового файла на основе кириллицы будет отображен как «É», поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
Выбор кодировки при открытии файла
Если в открытом файле текст искажен или выводится в виде вопросительных знаков либо квадратиков, возможно, Word неправильно определил кодировку. Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
Откройте вкладку Файл.
Нажмите кнопку Параметры.
Нажмите кнопку Дополнительно.
Перейдите к разделу Общие и установите флажок Подтверждать преобразование формата файла при открытии.
Примечание: Если установлен этот флажок, Word отображает диалоговое окно Преобразование файла при каждом открытии файла в формате, отличном от формата Word (то есть файла, который не имеет расширения DOC, DOT, DOCX, DOCM, DOTX или DOTM). Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось.
Закройте, а затем снова откройте файл.
В диалоговом окне Преобразование файла выберите пункт Кодированный текст.
В диалоговом окне Преобразование файла установите переключатель Другая и выберите нужную кодировку из списка.
В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Если почти весь текст выглядит одинаково (например, в виде квадратов или точек), возможно, на компьютере не установлен нужный шрифт. В таком случае можно установить дополнительные шрифты.
Чтобы установить дополнительные шрифты, сделайте следующее:
Нажмите кнопку Пуск и выберите пункт Панель управления.
Выполните одно из указанных ниже действий.
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
На панели управления щелкните элемент Установка и удаление программ.
В списке Установленные программы щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В группе Изменение установки Microsoft Office нажмите кнопку Добавить или удалить компоненты и затем нажмите кнопку Продолжить.
В разделе Параметры установки разверните элемент Общие средства Office, а затем — Многоязыковая поддержка.
Выберите нужный шрифт, щелкните стрелку рядом с ним и выберите пункт Запускать с моего компьютера.
Совет: При открытии текстового файла в той или иной кодировке в Word используются шрифты, определенные в диалоговом окне Параметры веб-документа. (Чтобы вызвать диалоговое окно Параметры веб-документа, нажмите кнопку Microsoft Office, затем щелкните Параметры Word и выберите категорию Дополнительно. В разделе Общие нажмите кнопку Параметры веб-документа.) С помощью параметров на вкладке Шрифты диалогового окна Параметры веб-документа можно настроить шрифт для каждой кодировки.
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке «Китайская традиционная (Big5)». В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание: Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке «Кириллица (Windows)», текст на иврите не отобразится, а если сохранить его в кодировке «Иврит (Windows)», то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Выбор кодировки
Откройте вкладку Файл.
Выберите пункт Сохранить как.
Чтобы сохранить файл в другой папке, найдите и откройте ее.
В поле Имя файла введите имя нового файла.
В поле Тип файла выберите Обычный текст.
Нажмите кнопку Сохранить.
Если появится диалоговое окно Microsoft Office Word — проверка совместимости, нажмите кнопку Продолжить.
В диалоговом окне Преобразование файла выберите подходящую кодировку.
Чтобы использовать стандартную кодировку, выберите параметр Windows (по умолчанию).
Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS.
Чтобы задать другую кодировку, установите переключатель Другая и выберите нужный пункт в списке. В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание: Чтобы увеличить область отображения документа, можно изменить размер диалогового окна Преобразование файла.
Если появилось сообщение «Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке», можно выбрать другую кодировку или установить флажок Разрешить подстановку знаков.
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в поле Завершать строки.
Поиск кодировок, доступных в Word
Word распознает несколько кодировок и поддерживает кодировки, которые входят в состав системного программного обеспечения.
Ниже приведен список письменностей и связанных с ними кодировок (кодовых страниц).
Юникод (UCS-2 с прямым и обратным порядком байтов, UTF-8, UTF-7)
Стандартный шрифт для стиля «Обычный» локализованной версии Word
Windows 1256, ASMO 708
Китайская (упрощенное письмо)
GB2312, GBK, EUC-CN, ISO-2022-CN, HZ
Китайская (традиционное письмо)
BIG5, EUC-TW, ISO-2022-TW
Windows 1251, KOI8-R, KOI8-RU, ISO8859-5, DOS 866
Английская, западноевропейская и другие, основанные на латинице
Как выбрать кодировку и исправить все проблемы с ней
ыЙТПЛБС ØàÞÚÐï ╒┌тр╪ф╪┌ПрЎ.ТруНЬ_аЭШЩ ФРбв ЬЮ.
Нет, мы не сошли с ума. Просто сегодня будем разбираться, как устранить ошибки кодировки и вернуть на сайт читаемый текст. Узнаем, как кодировка влияет на SEO-оптимизацию, и познакомимся с полезными сервисами, которые позволят вовремя идентифицировать ошибки.
Что такое кодировка, и когда возникают ошибки с отображением текста
Если вместо нормального текста на вашем сайте отображается странный набор символов, значит, есть проблемы с кодировкой. Впрочем, иногда кодировка на сайте является стандартизированной и выбрана корректно, но вместо текста все равно отображаются иероглифы.
Кодировка – это набор символов и система их передачи для последующего вывода на экран. Кроме алфавита при помощи кодировки передаются также специальные символы и цифры.
Сегодня массово используются 2 вида кодировки: Windows-1251 и UTF-8. Чаще всего «кракозябра» появляется, когда на одном сайте используется сразу несколько видов кодировки (да, такое бывает чаще, чем может показаться на первый взгляд).
Можно выделить и другие причины неполадок:
Как поменять кодировку в браузере
Проблему с кодировкой на стороне браузера исправить легко.
Internet Explorer
Chrome
Chrome современный и модный браузер, но вот кодировку стандартными средствами поменять в нем нельзя (сюрприз!). Будем делать это через расширение.
Safari
Firefox
Как выбрать кодировку
Если в качестве CMS вы используете WordPress, Joomla, Drupal, OpenCart или TYPO3, то дополнительно настраивать ничего не нужно. Эти движки по умолчанию работает именно с UTF-8. Все должно работать из коробки. Просто убедитесь, что везде прописана UTF-8.
В самых сложных случаях придется отдельно скачивать шаблоны под конкретную кодировку, предварительно создав MySQL. Последнее актуально, например, для DLE. Если же ваш cайт полностью самописный, просто проследите за тем, чтобы везде была установлена идентичная кодировка, желательно – UTF-8.
Какую кодировку выбрать
Сегодня большинство экспертов солидарны в том, что наиболее удобной кодировкой является UTF-8. Этот стандарт поддерживает большинство браузеров, баз данных, серверов и языков. Еще одно преимущество – она изначально была кроссплатформенной.
UTF-8 может закодировать любой unicode-символ. Пожалуй, именно это достоинство позволило кодировке стать одной из самых популярных в мире.
Windows-1251 известна в меньшей степени, но Windows-1251 и не отличается такой универсальностью и распространенностью как UTF-8. Проблемы с кодировкой могут встречаться на всех сайтах, даже на отлаженных площадках, которые работают в течение многих лет. Чтобы предотвратить проблемы с «кракозябрами» на своем сайте в будущем, необходимо с самого начала выбирать единую кодировку. Как вы уже догадались, лучший кандидат на эту роль – UTF-8.
Как узнать, какая кодировка используется на моем сайте
Узнать, какая кодировка используется на всем сайте или на конкретной странице, можно за несколько секунд. Для этого нужно просмотреть исходник HTML-страницы. Чтобы увидеть его, используем одновременное нажатие горячих клавиш Сtrl + U (на «Маке» активируем шорткатом Option/Alt + Command + U). Появится такое окно:

Теперь используем сочетание горячих клавиш Ctrl + F (Command + F) – откроется окно поиска. Вводим в поисковую строку атрибут charset (он же character set, кодировка документа). После этого атрибута мы увидим знак равенства. За ним и будет указана кодировка страницы.

Если атрибут charset не задан, его придется задать. Предварительно нужно проверить сайт при помощи сторонних сервисов. Один из них – Browserstack. Платформа платная, но, чтобы проверить кодировку, платить необязательно. Достаточно открыть сайт и выбрать пункт Get started free, создать аккаунт (можно просто залогиниться при помощи «Google-аккаунта»). После авторизации появится такое окно:
Выбираем интересующую нас операционную систему / устройство и вводим сайт, который нужно протестировать:
Если с кодировкой на сайте что-то не так, все ошибки будут представлены в результатах теста.
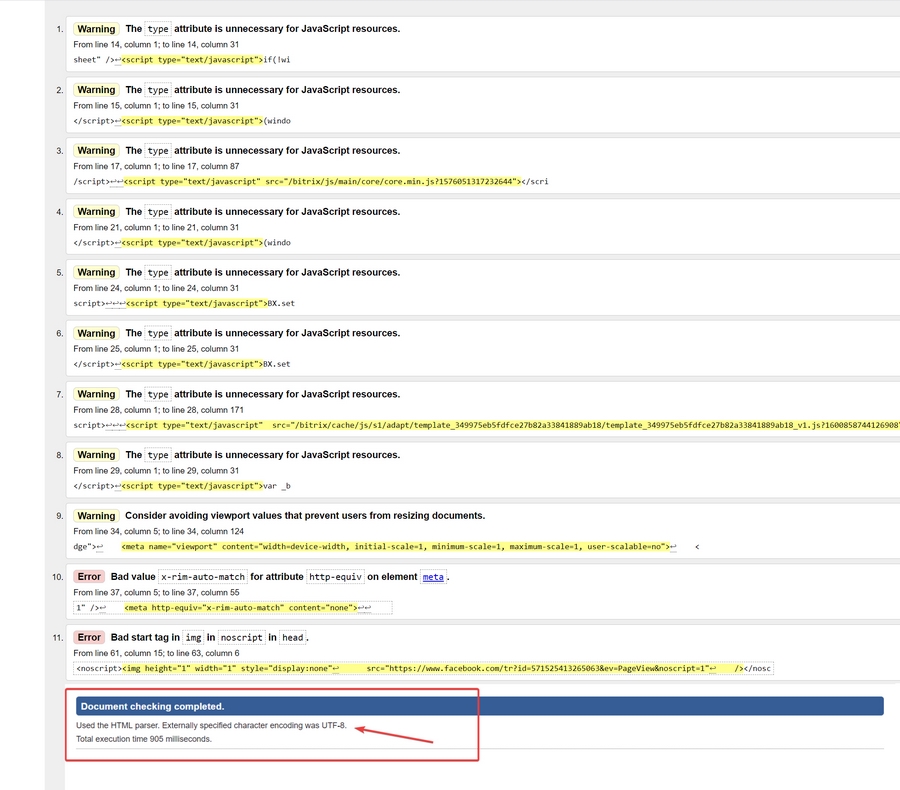
Для проверки и определения ошибок кодировки можно использовать не только Browserstack. Альтернатива – бесплатный сервис Validator. Он позволит идентифицировать кодировку сразу по нескольким данным, включая заголовки. Пример ошибки кодировки в результатах анализа Validator:
Также неплохие возможности для проверки технических ошибок сайта дает pr-cy.ru. Не забудьте выбрать пункт «Аудит страниц»:
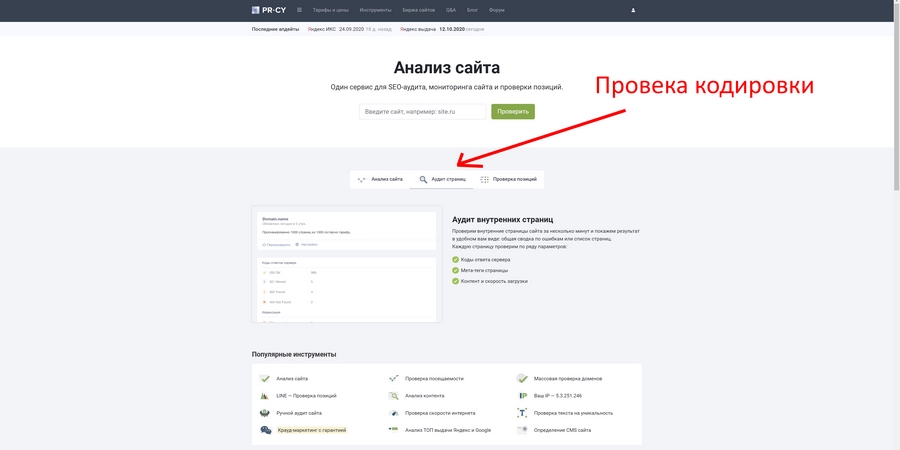
Хорошие инструменты для проверки кодировки предоставляют сервисы NetPeak и SeoFrog. Последний удобен еще тем, что позволяет проверить кодировку сразу по всем страницам сайта, а не только по одной.
Кодировка и оптимизация
Даже если кодировка на сайте не совсем обычная или отличается на разных страницах, Google и «Яндекс» все равно проиндексируют такой сайт, но при условии, что контент уникален и не переспамлен ключами. Одна из самых неприятных ошибок здесь – несовместимость кодировки веб-ресурса с той, которая используется на сервере. Даже в таком случае Google, например, способен корректно идентифицировать ошибку. Сайт будет в выдаче, если соответствующие условия были соблюдены.
Ошибки кодировки сами по себе не влияют на оптимизацию сайта прямым образом. Они сказываются на отказах и времени, проведенном на сайте, а также на иных поведенческих показателях аудитории.
Если на вашем сайте возникают ошибки кодировки, и контент отображается некорректно, то посетитель ни при каких обстоятельствах не будет тратить свое время, пытаясь настроить правильную кодировку и, тем более, пытаться ее преобразовать в читаемую. Большинство посетителей просто не знают, как это сделать, но даже если знают, не будут тратить время и точно уйдут к конкурентам на тот сайт, где содержимое изначально отображается корректно.
Устранить проблемы кодировки сложно: мало поменять ее на одной или нескольких страницах. Обычно приходится исправлять ее также в мете (одноименных тегах), БД MySQL, файле htaccess и других системных файлах сайта.
Как исправить ошибки кодировки на своем сайте
Инструкция предназначена только для опытных пользователей и не является призывом к действию. Код и настройки я привожу исключительно в качестве примера. Если вы решитесь вносить изменения в БД и системные файлы, особенно в root, обязательно сделайте резервную копию всех данных сайта!
Документы / HTML-файлы
Если возникают проблемы с документами, необходимо удостовериться в том, что они имеют одинаковую кодировку, и в том, что она вообще задана. Для этого открываем HTML-файл при помощи любого редактора, который позволяет работать с кодом. Например, через Notepad++. Открываем проблемный документ и выполняем следующую последовательность действий:
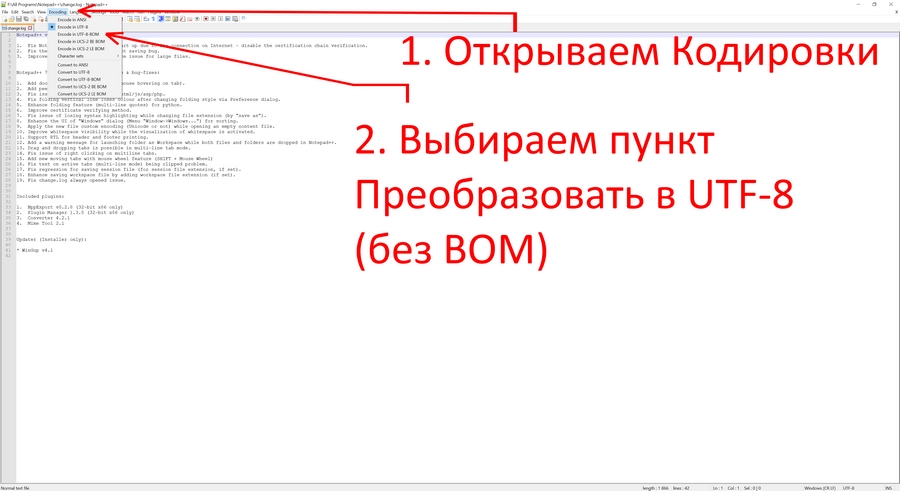
Htaccess
«Кракозябра» может появляться даже в тех случаях, когда ошибки в документах уже исправлены. В таком случае нужно проверить файл htaccess. Открываем его при помощи редактора кода, затем, используя одновременное сочетание горячих клавиш Ctrl + F, открываем окно «Поиск по странице» и вводим уже знакомый нам атрибут Charset. Если атрибут найден, его необходимо исправить на тот, который является стандартным для вашего сайта. Если его нет вообще, добавляем атрибут AddDefaultCharset UTF-8 в любом месте в самом начале документа.
Теги типа meta
Именно мета-тег используется для установки требуемой кодировки. Кроме этого, в нем прописываются и другие мета-теги, которые задействованы для хранения информации, используемой браузерами. Прописываются теги типа meta в head-разделе. Выглядит следующим образом:
Что нужно знать каждому разработчику о кодировках и наборах символов для работы с текстом
Это первая часть перевода статьи What Every Programmer Absolutely, Positively Needs To Know About Encodings And Character Sets To Work With Text
Если вы работаете с текстом в компьютере, вам обязательно нужно знать про кодировки. Даже если вы посылаете электронные письма. Даже если вы их только получаете. Необязательно понимать каждую деталь, но надо хотя бы знать, что из себя представляют кодировки. И вот первая хорошая новость: статья может быть немного запутанной, но основная идея очень и очень простая.
Эта статья о кодировках и наборах символов.
Статья Джоеэля Спольски под названием «Абсолютный минимум о Unicode и наборе символов для каждого разработчика(без исключений!)» будет хорошей вводной и мне доставляет большое удовольствие перечитывать ее время от времени. Я стесняюсь отсылать к ней тех людей, которые испытывают трудности с пониманием проблем с кодировкам, хотя она довольно легкая в плане технических деталей. Я надеюсь, эта статья прольет немного света на то, чем именно являются кодировки, и почему все ваши тексты оказываются испорченными в самый ненужный момент. Статья предназначена для разработчиков(главным образом, на PHP), но пользу от нее может получить любой пользователь компьютера.
Основы
Все более или менее слышали об этом, но каким-то образом знание испаряется, когда дело доходит до обсуждения, так что вот вам: компьютер не может хранить буквы, числа, картинки или что-либо еще. Он может запомнить только биты. Бит имеет только два значения: ДА или НЕТ, ПРАВДА или ЛОЖЬ, 1 или 0 или любую другую пару, которую вы можете вообразить. Раз уж компьютер работает с электричеством, бит представлен электрическим зарядом: он либо есть, либо его нет. Людям проще представлять это в виде 1 и 0, так что я буду придерживаться этих обозначений.
Чтобы с помощью битов представлять нечно полезное, нам нужны правила. Надо сконвертировать последовательность бит в что-то похожее на буквы, числа и изображения, используя схему кодирования, или, коротко, кодировку. Вот так, например:
01100010 01101001 01110100 01110011
b i t s
В этой кодировке, 01100010 представляет из себя ‘b’, 01101001 — ‘i’, 01110100 — ‘t’, 01110011 — ‘s’. Конкретная последовательность бит соответствует букве, а буква – конкретной последовательности битов. Если вы можете запомнить последовательности для 26 букв или умеете действительно быстро находить нужное соответствие, то вы сможете читать биты, как книги.
Упомянутая схема носит название ASCII. Строка с нолями и единицами разбивается на части по 8 бит(по байтам). Кодировка ASCII определяет таблицу перевода байтов в человеческие буквы. Вот небольшой кусочек этой таблицы:
01000001 A
01000010 B
01000011 C
01000100 D
01000101 E
01000110 F
В ней 95 символов, включая буквы от A до Z, в нижнем и верхнем регистре, цифры от 0 до 9, с десяток знаков препинания, амперсанд, знак доллара и прочие. В нее также включены 33 значения, такие как пробел, табуляция, перевод строки, возврат символа и прочие. Это непечатаемые символы, хотя они видимы человеку и используются им. Некоторые значения полезны только компьютеру, такие как коды начала и конца текста. Всего в кодировку ASCII включены 128 символов — прекрасное ровное число для тех, кто смыслит в компьютерах, так как оно использует все комбинации 7ми битов (от 0000000 до 1111111).
Вот вам способ представить человеческую строку, используя только единицы и нули:
01001000 01100101 01101100 01101100 01101111 00100000
01010111 01101111 01110010 01101100 01100100
Важные термины
Для кодирования чего-либо в ASCII двигайтесь справа налево, подменяя буквы на биты. Для декодирования битов в символы, следуйте по таблице слева направо, подменяя биты на буквы.
encode |enˈkōd|
verb [ with obj. ]
convert into a coded form
code |kōd|
noun
a system of words, letters, figures, or other symbols substituted for other words, letters, etc.
Кодирование – это представление чего-либо чем-нибудь другим. Кодировка – это набор правил, описывающий способ перевода одного представления в другое.
Прочие термины, заслуживающие прояснения:
Набор символов, чарсет, charset – Набор символов, который может быть закодирован. «Кодировка ASCII включает набор из 128 символов». Синоним к кодировке.
Кодовая страница – страница кодов, закрепляюшая за символом набор битов. Таблица. Синоним к кодировке.
Строка – пачка чего-нибудь, объединенных вместе. Битовая строка – это пачка бит, такая как 00011011. Символьная строка – это пачка символов, например «Вот эта». Синоним к последовательности.
Двоичный, восьмеричный, десятичный, шестнадцатеричный
Существует множество способов записывать числа. 10011111 – это бинарная запись для 237 в восьмеричной, 159 в десятичной и 9F в шестнадцатиричной системах. Значения у всех этих чисел одинаково, но шестнадцатиричная система короче и проще для понимания, чем двоичная. Я буду придерживаться двоичной системы в этой статье, чтобы улучшить понимание и убрать лишний уровень абстракции. Не пугайтесь, встречая коды символов в других нотациях, все значения эквиваленты.
Excusez-Moi?
Раз уж мы теперь знаем, о чем говорим, заметим: 95 символов – это совсем немного, когда речь идет о языках. Этот набор покрывает базовый английский, но как насчет французских символов? А вот это Straßen¬übergangs¬änderungs¬gesetz из немецкого языка? А приглашение на smörgåsbord в шведском? В-общем, не получится. Не в ASCII. Спецификация на представление é, ß, ü, ä, ö просто отсутствует.
“Постойте-ка”, скажут европейцы, “в обычных компьютерах с 8 битами в байте, ASCII никак не использует бит, который всегда равен 0! Мы можем использовать его, чтобы расширить таблицу еще на 128 значений”. И было так. Но способов обозначить звучание гласных еще слишком много. Не все сочетания букв и значений, используемые в европейских языках, влезают в таблицу из 256 записей. Так мир пришел к изобилию кодировок, стандартов, стандартов де-факто и недостандартов, которые покрывают все субнаборы символов. Кому-то понадобилось написать документ на шведском или чешском, и, не найдя нужной кодировки, просто изобрел еще одну. Или я думаю, что все так и произошло.
Не забывайте о русском, хинди, арабском, корейском и множестве других живых языков планеты. Про мертвые уж молчим. Как только вы найдете способ писать документ, использующий несколько языков, попробуйте добавить китайский. Или японский. Оба содержат тысячи символов. И у вас всего 256 значений. Вперед!
Многобайтные кодировки
Для создания таблиц, которые содержат более 256 символов, одного байта просто недостаточно. Двух байтов (16 бит) хватит для кодировки 65536 различных значений. Big-5 например, кодировка двухбайтная. Вместо разбиения последовательности битов в блоки по 8, она использует блоки по 16 битов и содержит большую(я имею ввиду БОЛЬШУЮ) таблицу с соответствием. Big-5 в своем основном виде покрывает большинство символов традиционного китайского. GB18030 – это похожая кодировка, но она включает как традиционный, так и упрощенный китайский. И, прежде чем вы спросите, да, есть кодировки только для упрощенного китайского. А разве одной недостаточно?
Вот кусок таблицы GB18030:
bits character
10000001 01000000 丂
10000001 01000001 丄
10000001 01000010 丅
10000001 01000011 丆
10000001 01000100 丏
GB18030 покрывает довольно большой диапазон символов, включая большую часть латинских символов, но в конце концов, это всего лишь еще одна кодировка среди многих других.
Путаница с Unicode
В итоге тем, кому больше всех надоела эта каша, пришла в голову идея разработать единый стандарт, объединяющий все кодировки. Этим стандартом стал Unicode. Он определяет невероятную таблицу из 1 114 112 пунктов, используемую для всех вариантов букв и символов. Этого хватит для кодирования всех европейских, средне-азиатских, дальневосточных, южных, северных, западных, доисторических и будущих символов, о которых человечеству известно. Unicode позволяет создать документ на любом языке любыми символами, которые можно ввести в компьютер. Это было невозможно, или очень затруднительно до эры Unicode. В стандарте есть даже неофициальная секция под клингонский. Вы поняли, Unicode настолько большой, чтобы допускает неофициальные секции.
Итак, и сколько же байт использует Unicode для кодирования? Нисколько. Потому что Unicode – это не кодировка.
Смущены? Не вы одни. Unicode в первую и главную очередь определяет таблицу пунктов для символов. Это такой способ сказать «65 – A, 66 – B, 9731 – »(я не шучу, так и есть). Как эти пункты кодируются в байты является предметом другого разговора. Для представления 1 114 112 значений двух байт недостаточно. Трех достаточно, но 3 – странное число, так что 4 является комфортным минимумом. Но, пока вы не используете китайский, или другой язык со множеством символов, которые требуют большого количества битов для кодирования, вам никогда не придет в голову использовать толстую колбасу из 4х байт. Если “A” всегда кодируется в 00000000 00000000 00000000 01000001, а “B” – в 00000000 00000000 00000000 01000010, то документ, использующий такую кодировку, распухнет в 4 раза.
Существует несколько способов решения этой проблемы. UTF-32 – это кодировка, которая переводит все символы в наборы из 32 бит. Это простой алгоритм, но изводящий много места впустую. UTF-16 и UTF-8 являются кодировками с переменной длиной кодирования. Если символ может быть закодирован одним байтом(потому что номер пункта символа очень маленький), UTF-8 закодирует его одним байтом. Если нужно 2 байта, то используется 2 байта. Кодировка сообщает старшими битами, сколькими битами кодируется текущий символ. Такой способ экономит место, но так же и тратит его в случае, если эти сигнальные биты часто используются. UTF-16 является компромиссом: все символы как минимум двухбайтные, но их размер может увеличиваться до 4 байт, если нужно.
character encoding bits
A UTF-8 01000001
A UTF-16 00000000 01000001
A UTF-32 00000000 00000000 00000000 01000001
あ UTF-8 11100011 10000001 10000010
あ UTF-16 00110000 01000010
あ UTF-32 00000000 00000000 00110000 01000010
И все. Unicode – это огромная таблица соответствия символов и чисел, а различные UTF кодировки определяют, как эти числа переводятся в биты. В-общем, Unicode – это просто еще одна схема. Ничего особенного, она просто пытается покрыть все, что можно, оставаясь эффективной. И это хорошо.
Пункты
Символы определяются по их Unicode-пунктам. Эти пункты записаны в шестнадцатеричной системе и предварены “ U+” (просто для удобство, не значит ничего, кроме “Это пункт Unicode”). Символ Ḁ имеет пункт U+1E00. Иными(десятичными) словами, это 7680й символ таблицы Unicode. Он официально называется “ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА А С КОЛЬЦОМ СНИЗУ”.
Ниасилил
Суть вышесказанного: любой символ может быть закодирован множеством разных последовательностей бит, и любая последовательность бит может представлять разные символы, в зависимости от используемой кодировки. Причина в том, что разные кодировки используют разное число бит на символ и разные значения для кодирования разных символов.
11000100 01000010 Windows Latin 1 ÄB
11000100 01000010 Mac Roman ƒB
11000100 01000010 GB18030 腂
characters encoding bits
Føö Windows Latin 1 01000110 11111000 11110110
Føö Mac Roman 01000110 10111111 10011010
Føö UTF-8 01000110 11000011 10111000 11000011 10110110
Заблуждения, смущения и проблемы
Имея все вышесказанное, мы приходим к насущным проблемам, которые испытывают множество пользователей и разработчиков каждый день, как они соотносятся с указанным выше, и каковы пути решения. Сама большая проблема – это
Какого черта мой текст нечитаем?
Если вы откроете документ, и он выглядит так, как текст выше, то причина у этого одна: ваша программа ошиблась с кодировкой. И все. Документ не испорчен(по крайней мере, пока), и не нужно никакое волшебство. Вместо него надо просто выбрать правильную кодировку для отображения текста. Предполагаемый документ выше содержит биты:
10000011 01000111 10000011 10010011 10000011 01010010 10000001 01011011
10000011 01100110 10000011 01000010 10000011 10010011 10000011 01001111
10000010 11001101 10010011 11101111 10000010 10110101 10000010 10101101
10000010 11001000 10000010 10100010
Так, быстренько угадали кодировку? Если вы пожали плечами, то вы правы. Да кто знает?
Попробуем с ASCII. Большая часть этих байтов начинается с 1. Если вы правильно помните, ASCII вообще-то не использует этот бит. Так что ASCII не вариант. Как насчет UTF-8? Большая часть байт не является валидными значениями в этой кодировке. Как насчет Mac Roman(еще одна европейская кодировка)? Хм, для нее эти байты являются правильными значениями. 10000011 декодируетися в ”É”, в “G” и так далее. Так что в Mac Roman текст будет выглядеть так: ÉGÉìÉRÅ[ÉfÉBÉìÉOÇÕìÔǵÇ≠ǻǢ. Правильно? Нет? Может быть? А компьютер-то откуда знает? Может кто-то хотел написать именно это. Насколько я знаю, это может быть последовательностью ДНК! Так и порешим: это Mac Roman, и это ДНК.
Конечно, это полный бред. Правильный ответ таков: текст закодирован в Japanes Shift-JIS и должен выглядеть как エンコーディングは難しくない. Кто бы мог подумать?
Первая причина нечитаемости текста в том, что кто-то пытается прочитать последовательность байт в неверной кодировке. Компьютеру всегда нужно подсказывать. Сам он не догадается. Некоторые типы документов определяют кодировку своего содержимого, но последовательность байт всегда остается черным ящиком.
Большинство браузеров предоставляют возможность указать кодировку страницы с помощью специального пункта меню. Иные программы тоже имеют аналогичные пункты.
У автора нет разбиения на части, но статья и так длинна. Продолжение будет через пару дней.