Автоматизация тестирования ПО
Раздел: Автоматизация > Практикум > Конфигурация тестового стенда для нагрузочного тестирования
Конфигурация тестового стенда для нагрузочного тестирования
Введение
В предыдущей статье мы говорили о создании модели нагрузочного тестирования, теперь давайте разберем “по полочкам” конфигурацию тестового стенда. Постараемся понять, каким он должен быть, для чего он должен быть как можно больше приближен к реальной эксплуатируемой конфигурации, как производить анализ результатов в случае, если тестовый стенд отличается от реального.
Конфигурация vs Производительность
На результаты нагрузочного тестирования могут влиять разные факторы, такие как конфигурация тестового стенда, загруженность сети, заполненность базы данных и многие другие. Причем влияние их на производительность приложения может быть значительным и иметь нелинейную зависимость, поэтому выразить её формулой будет практически невозможно. Следовательно, чем меньше будут разниться параметры тестовой и реальной инфраструктуры, тем меньше будет погрешность в полученных результатах.
Конфигурация тестового стенда
Отметим те части конфигурации, которые требуют особого внимания:
В самом идеальном случае тестовый стенд один к одному дублирует конфигурацию реального сервера, на котором работает или же будет работать приложение. Однако, как мы с вами знаем, идеальных случаев практически не бывает (то памяти мало, то процессора такой частоты нет в наличии, то операционная система не той версии, то стоимость некоторого серверного ПО не укладывается в бюджете). Перечислим основные причины, по которым не всегда получается продублировать конфигурацию системы на тестовом стенде:
Целесообразность же воссоздания инфраструктуры необходимо оценить с учетом выделенных ресурсов, времени и усилий, так как не всегда результат будет оправдывать средства.
Приведем пример (придуманный из головы и вполне возможно нереальный) для того, чтобы показать сложность сравнения результатов на двух разных системах:
Требуется конфигурация: Proc Intel Clarkdale Core I5, 16 Gb памяти DDR3-800, OS SLES11
Конфигурация тестового стенда: Proc AMD Deneb Phenom II X4, 16 Gb DDR2-800, OS SLES10
Казалось бы отличия незначительны, однако есть нюансы:
| Название ядра | Intel Clarkdale Core I5 | AMD Deneb Phenom II X4 |
| Тактовые частоты, Мгц | 2800-3600 | 2800-3000 |
| Частоты системной шины, Мгц | 2500 | 2000-1800 |
| Пропускная способность шины процессор-чипсет | 2 ГБ/сек (1 ГБ/сек в одном направлении) | 14.4-16 ГБ/сек (7.2-8 ГБ/сек в одном направлении) |
| Размер кэша L1, Кб | 64 х2 | 128 х4 |
| Размер внутреннего кэша L2, Кб | 256 x2 | 512 х4 |
| Ширина шины L2 кеша, бит | 256 (двунаправленная) | 256 (по 128 в каждом направлении) |
| . | . | . |
Примечание: Не правда ли, непросто будет сравнивать без помощи специалистов? Тем более вывести коэффициент на сколько какой процессор быстрее и по каким параметрам.
Стандартная задержка (latency) типичная для DDR2 5-5-5-15, а для DDR3 памяти 7-7-7-15. Однако даже с большей задержкой DDR3 память (в отличие от старого стандарта DDR2) обладает большей пропускной способностью (bandwidth) из-за более высокой тактовой частоты (clock speed). Что становится причиной того, что DDR3 память работает немного медленнее, чем DDR2 с такой же частотой 800MHz.
Таким образом, память на тестовом стенде будет немного быстрее чем в требуемой конфигурации.
Cравним операционные системы
По мнению экспертов, какой-либо существенной разницы в производительности из-за версии ОС не будет, однако небольшой прирост может быть только из-за того, что в более свежих ядрах чуть оптимальнее код.
Таким образом предположим, что SLES 11 будет незначительно быстрее SLES 10.
Удивлены таким большим количеством различий? (Причем это только для трех элементов конфигурации: процессора, памяти и операционной системы. В реальности их намного больше) Легко ли будет сделать выводы о том, как будет работать приложение на требуемой конфигурации? (Я думаю, что практически невозможно) Однако далее мы попробуем все таки найти пути для решения этой проблемы, рассмотрев некоторые практические приемы.
Анализ результатов при разных конфигурациях
Как же быть с тем фактом, что приложение будет протестировано на одной платформе, а работать ему придется на другой? Как провести анализ результатов? Как сделать окончательные выводы и спрогнозировать работу приложения под нагрузкой в будущем?
Использование переходного коэффициента
В своей статье [1] Вячеслав Берзин, предложил при анализе результатов использовать “переходный коэффициент”, показывающий численно отличие производительности тестовой платформы от промышленной:
«Если существует отличие в конфигурациях тестового стенда и тестируемой системы, необходима оценка переходного коэффициента для производительности тестовой и промышленной систем. На основании этого коэффициента, проводится масштабирование полученных результатов. Для получения погрешности оценки, не превышающей 5-10%, рекомендуется проведение оценки переходного коэффициента несколькими независимыми способами, например, на основании анализа независимых данных о производительности используемых аппаратных платформ.»
Использование данного подхода, значительно облегчает создание и конфигурацию тестового стенда, но прибавляет работы на этапе анализа результатов. Так что вам придется решать самим: либо пытаться один к одному (100%) скопировать промышленную систему, либо сделать её максимально приближенной и с помощью переходного коэффициента анализировать и делать прогнозы на будущий рост производительности.
Однако, не всегда возможно точно получить значение переходного коэффициента из-за нелинейных зависимостей между компонентами системы, а примерный расчет может дать слишком большую погрешность. Поэтому использование данного подхода видится реальным, когда тестовая и реальная конфигурации системы практически идентичны.
Использование экспертной оценки
Рассмотрим мнение Андрея Широбокова [2] (сертифицированный специалист в области нагрузочного тестирования, имеющий более 15 лет рабочего опыта в IT):
«Идеально ключевые моменты должны совпадать, пишу по убыванию важности:
Естественно, что версия тестируемого приложения должна быть актуальна.
Если совпадает платформа (ОС и тип процессоров), то допускается «пропустить» конфигурацию, например, в случае если проведены эксперименты на конфигурациях 8х16 (8 прц х 16 Гб) и 32х64 (32 прц х 64 Гб), то можно «аппроксимировать» недостающую конфигурацию 24х48 (24 прц х 48 Гб). Обратим внимание, что памяти для такой методики должно пропорционально быть в 2 раза больше во всех случаях.
Если не совпадает платформа, ОС, типы процессоров, объемы памяти, то можно делать только очень общие выводы, наподобие: «В реальности будет не хуже». Но времена откликов и другие детали могут быть малозначимы.»
Как видим, как при использовании переходного коэффициента, так и при использовании экспертной оценки, анализ результатов и прогнозирование роста производительности при тестировании на разных конфигурациях стендов (тестового и реального) становится затруднительным, и либо требует дополнительных перерасчетов по сложным нелинейным формулам с большим количеством параметров, либо не обеспечивает должной точности результатов.
Выводы
В данной статье мы попытались описать основные моменты связанные с конфигурацией тестового стенда для нагрузочного тестирования. В результате мы имеем следующее:
Как мы автоматизировали развёртывание тестовых стендов с помощью Gitlab и VMmanager

Как в ISPsystem экономят 15 человеко-часов в неделю, рассказал специалист QA Антон Рязанцев.
Зачем автоматизировать создание тестовых стендов
В продуктовых командах мы стремимся автоматизировать рутинные задачи, которые отнимают много времени. Иногда для этого используем собственные продукты. Например, VMmanager помогает нам в развёртывании тестовых стендов. В процессе разработки и тестирования поднимать стенды требуется довольно часто, и хочется сделать этот процесс максимально простым. Код наших продуктов хранится в Gitlab, процессы CI/CD также организованы в нём. Поэтому удобно интегрировать Gitlab и VMmanager для создания стендов.
Как запуск создания тестового стенда реализован в Gitlab
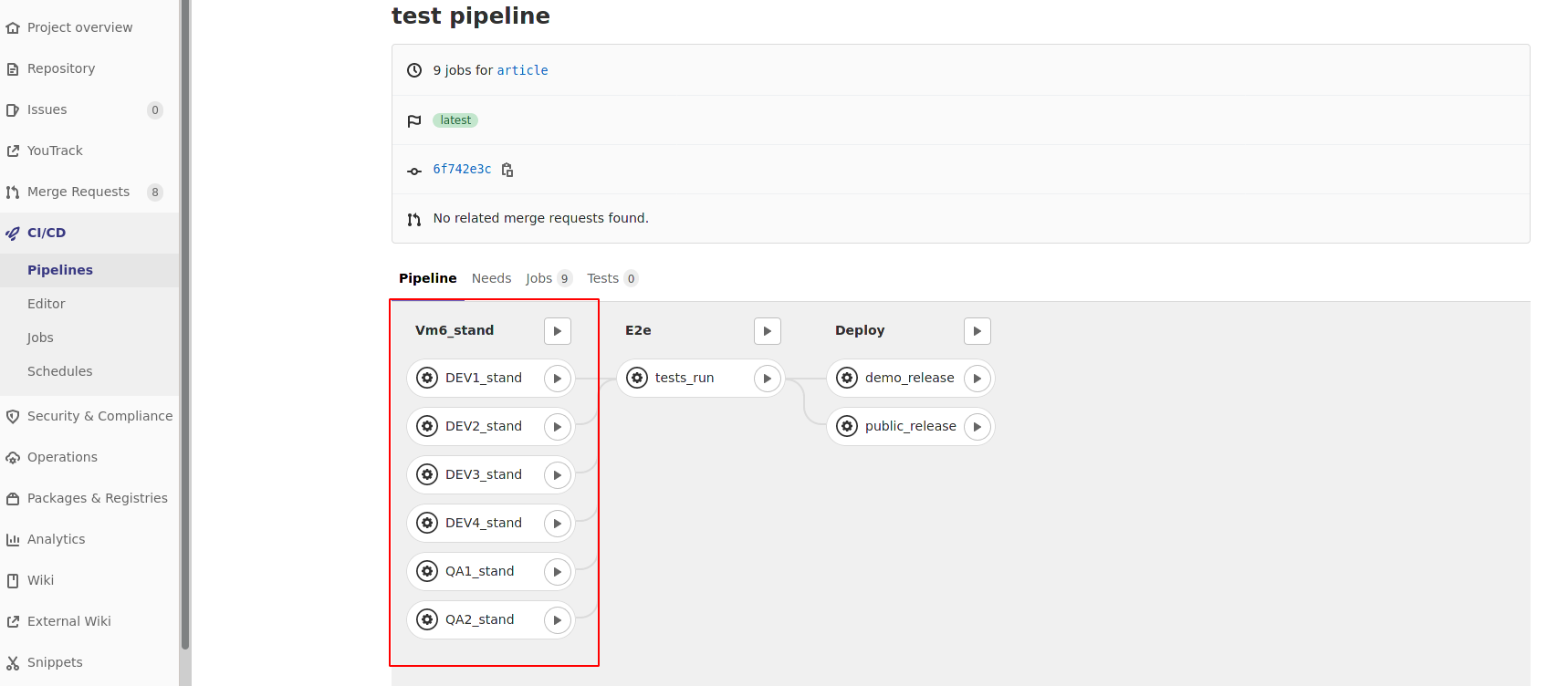
Когда это необходимо, пользователь (разработчик или тестировщик) запускает задачу.
Для задачи задан ID виртуальной машины, на которую она разворачивает стенд, а также ID скрипта в VMmanager и параметры для него.
Задача по API VMmanager выполняет необходимые действия над виртуальной машиной:
Пользователю остаётся дождаться завершения задачи, чтобы получить готовый стенд.
За взаимодействие с VMmanager 6 по API отвечает Python-скрипт reinstall_vm.py. Реализовать такой скрипт на Python или Bash не сложно. Для этого нам понадобится API VMmanager.
Скрипт принимает в качестве аргументов:
Часть из этих данных мы храним в Gitlab CI/CD Variables в защищённом виде.
Как создание тестового стенда реализовано с помощью VMmanager
Скрипт в VMmanager 6 содержит последовательность команд, которая устанавливает и настраивает стенд на виртуальную машину.
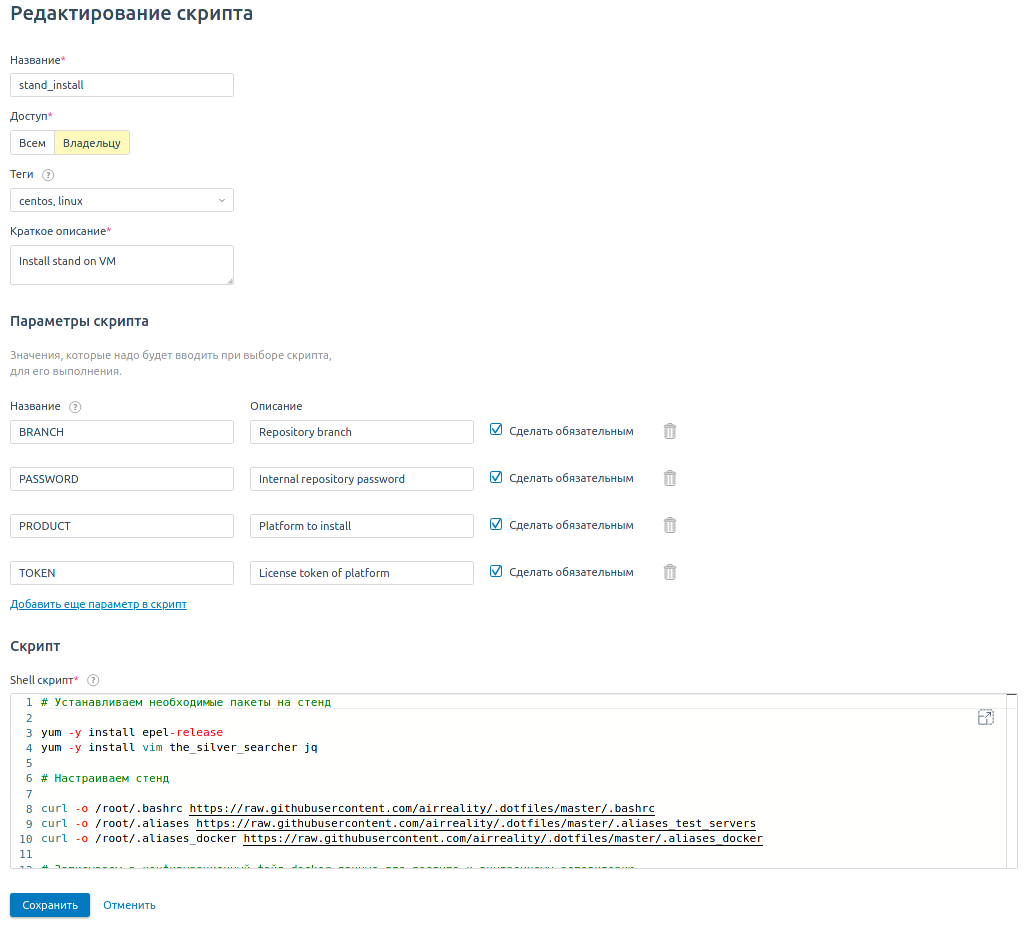
Скрипт содержит параметры:
Удобно и безопасно, что эти данные нигде не фигурируют. Нам не приходится их записывать в тело скрипта, перед тем как его запустить. Вместо этого мы один раз передаём их при запуске скрипта по API.
Также используется глобальная переменная LOGIN — логин для доступа к внутреннему репозиторию. Логин всегда одинаковый, поэтому мы храним его в глобальных переменных.
Такая автоматизация позволяет нам сэкономить на каждом поднятии тестового стенда около 15-20 минут разработчика или тестировщика. В среднем новый стенд приходится поднимать примерно раз в рабочий день. Так за неделю мы экономим около полутора часов на каждого человека. В средней команде из 10 разработчиков и тестировщиков это даёт около 15 часов, которые можно потратить на другие задачи.
Попробуйте VMmanager для автоматической продажи SaaS и хостинга на VPS
VMmanager — платформа для виртуализации и автоматической выдачи виртуальных машин.
Стенд для нагрузочного тестирования: от DEV до PROD

Содержание
Меня зовут Василий Кудрявцев, и вот уже 10 лет я занимаюсь нагрузочным тестированием, а из них последние 1,5 года – в компании РТЛабс.
И сегодня мы поговорим не об инструментах или общих подходах (для этого есть курсы – один из крупных веду я, а еще у многих есть коллеги-эксперты и тот самый чатик в телеге на 3400+ участников), а об области, которую обычно обходят стороной или собирают на коленке — тестовые стенды для нагрузочного тестирования.
Здесь, на Госуслугах, мы пока только конструируем мечту каждого нагрузочника — свой отдельный, выделенный, рабочий (!) тестовый стенд. Особенно это мечта актуальна для небольших продуктовых команд.
Тем не менее, за последний год мы увеличили количество проводимых тестов почти в 10 раз и команду раза в два. Где же мы проводим более 1000 нагрузочных тестов в год без отдельного стенда, спросите вы? Ответ: мы использовали все стенды по максимуму, под шум (крики) продуктовых команд! 🙂
Я попробовал обобщить личный опыт последних лет, успехи прорыва в результативности тестов и, соответственно, в повышении производительности, которого мы смогли достичь в компании за последнее время.
Договоримся о терминологии
НТ — нагрузочное тестирование, для меня это синоним тестирования производительности. В НТ входят всевозможные подвиды тестов, направленные на проверку показателей производительности системы: время отклика, пропускная способность, % успешных операций или доступность, утилизация ресурсов.
Максимальная производительность — уровень пропускной способности системы, после которого система перестаёт удовлетворять предъявленным к ней требованиям — по времени отклика, доступности, утилизации ресурсов.
Тест определения максимальной производительности — ступенчатое повышение нагрузки на систему до достижения этого самого уровня.
Как у нас организована нагрузка
Инструменты:
Протоколы – наиболее часто это REST-ы и web по http, бывают и скрипты нагрузки на БД / очереди
Запуск тестов в Jenkins
Мониторинг в Grafana + Clickhouse
Для мониторинга генераторов нагрузки — Prometheus
Redis и Postgres для хранения тестовых данных, FTP для больших файлов
В общем, всё как у взрослых людей. В следующих статьях расскажем об этом подробнее, если интересно. А сейчас едем дальше.
3+ регулярно нагружаемые крупные системы:
Единый портал государственных услуг (ЕПГУ)
Единая система идентификации и аутентификации (ЕСИА)
Система межведомственного электронного взаимодействия (СМЭВ, шина данных)
…и еще с десяток периодически нагружаемых прикладных систем и сервисов
Основные типы тестов:
Проверка стабильной нагрузки — короткий тест с заданным tps
Стресс-тесты — проверка работы под большой нагрузкой в течение короткого времени
Классическая максимальная производительность
Команда инженеров:
1 лид и 4 нагрузочника разного опыта и происхождения, со средним опытом в НТ =
Вернемся к нагрузочным стендам
Разделим типы стендов на несколько категорий и поймём, что же можно на них тестировать и какие риски / ограничения нужно держать в уме:
DEV — стенд разработки
UAT — стенд регрессионного функционального тестирования
LT — отдельный стенд нагрузочного тестирования
PROD — стенд на базе инфраструктуры Продуктивного контура
Каждый опишем с нескольких сторон по такой схеме:
Summary — короткое резюме от меня
Жиза — как мы используем этот стенд
Что можно — какие тесты можно проводить
Команда — кто здесь понадобится нагрузочнику, насколько самостоятельно выполнение тестов
Advice — совет напоследок обзора стенда
Summary: Отличное место для нагрузки пилотных решений или новых микросервисов, но задержаться на нём для исследований бывает сложно. Особенно, если архитектура монолитная.
Жиза: Не самый активный стенд именно для нагрузки, но супер-массовые новые сервисы сначала тестим здесь — социальные выплаты, сервисы для выборов, онлайн-запись в школы. Конечно же, в микросервисах, особенно часто в кубере. Здесь не проверить какой-нибудь scaling, но 50-70% проблем на данном стенде мы закрывали, хоть пользовались им не так часто, как стоило бы.
Отступление в рамках темы
Отдельного внимания здесь в описании DEV заслуживает наше детище для Системы межведомственного электронного взаимодействия (СМЭВ). Изначально мы планировали собрать стенд LT, но заказчики-разработчики пожелали проверять новые решения и тюнинг/рефакторинг старых здесь и сейчас. У нас вышел эдакий Монстр, которого мы прозвали DEV-LT! По необходимости могли и мощностей накинуть для достижения нужных цифр, но и не ждали отлаженных новых релизов и прочих pipeline-ов для проверки разных гипотез.
В итоге за пару месяцев мы протестили отказоустойчивость при отключении разных сервисов системы, протюнили с десяток компонент и повысили общую производительность системы раза в три (с учётом пост-тестов на других стендах, конечно же). Это был суровый марафон, но глаза горели у всех!
Что можно: стресс-тесты и общая максимальная производительность всего комплекса здесь бессмысленны. Только точечный тюнинг и проверка отдельных компонентов тестами со стабильными потоками (количество открытых соединений / thread-ов) или подачей стабильной нагрузки.
Команда: Если времени мало, то практически в онлайне с разработчиком. Если побольше — в режиме чатика. Очень удобно поработать devops-ом: сделать «кнопку» для разработчика и дать ему «пофрустрировать» самому до желаемого результата. Не забудьте про мониторинг, чтобы он получал удовольствие! Главное вовремя остановить, не доводить до уровня «хочу 100к tps выжать, 12 ночи всего, запускаю ещё тест!»
Pros and cons:
+ экономит время тюнинга на поздних этапах, что особенно актуально для багов по производительности (все мы знаем, они бывают ОЧЕНЬ дорогими)
+ можно запускать «на коленке» и получать реальный value
– не подходит для основательных выводов по максималке / не применить к PROD — нужны дополнительные тесты на других контурах
– стенд обычно шаток и разработчики любят его ломать, а иногда его потом сложно восстановить
– сложно с тестированием интеграций, DEV, как правило, изолирован
Advice: Совет подойдёт и для других стендов — «одно изменение за раз!». Разработчики любят побежать азартно вперёд, и применить много «оптимизаций» между тестами за один раз. Потом приходится часто искать, что именно улучшило или ухудшило производительность. Поэтому лучше стараться делать одно улучшение/изменение за раз и оценивать тестом, хотя бы коротким.
UAT (стенд регрессионного функционального тестирования) — относительно стабильный контур по сборкам, но слабый по железу
Жиза: С этого стенда мы начинали в РТЛабс проводить регулярное НТ — в данном случае проверка релизов на не-ухудшение производительности. В частности, на небольшом железе мы сравниваем «выдерживание» ступени стабильной нагрузки по основным показателям производительности. Дефектов обычно находится не так много, как хотелось бы, потому что у этого стенда всегда много «но» по сравнению с PROD. И это несмотря на то, что по конфигурации компонентов он к нему ближе, чем любой другой.
Что можно: Лучше проводить тесты стабильной нагрузки 10-60 минут. Длительность зависит от вашей ступени стабильной нагрузки, за которую вы сможете адекватно оценить показатели производительности. Если у вас быстрая система с 100-500+ tps и временем отклика в пределах секунды (шина данных, например), то хватит и коротких тестов. Если что-то пользовательское с множеством сценариев — лучше погонять подольше и заодно оценить надежность.
Команда: Как правило, лучший друг нагрузочника — это функциональщик. В данном случае вдвойне, так как это его стенд! Он подскажет, когда и сборка более-менее стабильна и когда можно поломать стенд тестами. С дефектами тут сложнее, чем на DEV — у нас по крайней мере были наводки и на инфраструктурные сбои, а разбор может быть не таким быстрым, как хотелось бы.
Pros and cons:
+ хороший стенд для старта нагрузочного тестирования в плане стабильности и отладки (в том числе на новых готовящихся версиях системы). И для того, чтобы потом куда-то переезжать с тестами на другие стенды
+ обычно неплохая поддержка со стороны ФТ и сопровождения, так как релизы должны ехать в PROD без простоев. А вы, в том числе, занимаете время подготовки релиза 🙂
– придётся выбирать время для тестов, чтобы не мешать ФТ
– сильную нагрузку целиком на систему не подать ввиду слабости стенда по железу, то есть сложно оценить максимальную производительность в целом
Advice: Не убивайте стенд, пожалейте функциональщиков! Не только проведением нагрузки днём, но и забиванием БД тестовыми или созданными в тестах данными. Проработайте процедуры очистки.
LT (отдельный стенд нагрузочного тестирования)
На какой хватит средств какой построите, такой и будет! Но в любом случае он лучше остальных стендов, потому что СВОЙ.
Summary: Здесь всё понятно — идеальный стенд практически для любых целей НТ. Не надо сидеть по ночам / ждать пока он освободится (в пределах одной тестируемой системы, конечно). В некоторых банках даже построили интеграционные стенды НТ. Правда пока я не видел стенд, выдерживающий 100% нагрузку по профилю с Прода, со всех каналов-систем.
Жиза: Выше я рассказывал о том, как мы применяем стенд DEV-LT. Пока мы видим неплохую пользу в совмещении целей для этого контура с учетом имеющейся инфраструктуры PROD для больших тестов (об этом ниже).
Из опыта других компаний могу сказать, что отдельный контур это действительно долго, дорого и замечательно. Причём для стабильного стенда крупной системы «долго» — это скорее всего минимум год, а «дорого» — не только закупка оборудования, но ещё и отдельная команда админов разного профиля. Ведь у вас небольшой PROD, а значит нужны инженеры СПО, ППО, DBA и т.д.
При этом на других стендах можно и нужно ловить 80-90% проблем. Это значит, что в микросервисной архитектуре огромные стенды становятся всё менее полезными.
Что можно: ВСЁ. Ну, правда. Интеграционные нагрузочные тесты можно проводить с эмуляторами, хорошо идут регрессионные тесты, стресс-тест/максималка/надежность/отказоустойчивость и любые другие, которые вы ещё себе придумаете между релизами.
Команда: Если хотите работать эффективно, а не чинить стенд неделями, когда ребята с PROD / тестовых контуров смогут уделить вам время, то только отдельная команда. Если стенд небольшой, можно не выделять отдельно системных администраторов / DBA на задачи одного этого стенда. Но инженеры ППО точно нужны — системы нужно и поднимать с нуля и поддерживать (поднимать) после регулярных тестов и релизов, которые будут их ломать.
Pros and cons:
+ подходит для всех нужных нагрузочных тестов (с интеграционным НТ может быть сложно, но возможно!)
+ не нужно ждать очередь на стенд, есть время для улучшений / экспериментов
+ можно готовить нужные наборы тестовых данных, тестировать объемы
– дорого и долго — и по подготовке железа, и в поддержке
– команде сопровождения нужно долго набираться опыта
– бывает сложно отслеживать все изменения на PROD / тестовых контурах, чтобы тестовый стенд НТ был актуален
Advice: Не надейтесь, что стенд НТ взлетит быстро, особенно если команда собирается с нуля. Исключения — небольшие и простые системы, по ним и PROD просто и быстро собрать.
И раз уж у вас отдельный стенд — пробивайте получение копии БД с PROD (урезанной, обезличенной), это повысит качество тестирования.
Ещё совет— не делайте прогнозирование / домножение результатов, полученных на стенде НТ, для PROD, если у вас LT сильно меньше по ресурсам. Горизонтальное масштабирование — непростая штука. Да простят меня мастера-архитекторы – иногда позволяю себе «умножить на 2» производительность, полученную на стенде НТ, который в 2 раза слабее Прода по ресурсам, при микросервисной архитектуре и не загруженности всех узлов по метрикам серверов. Можно предположить, что на Прод будет не хуже.
Сравнение производительности простой web-ки на node.js при увеличении ресурсов машины в 2 раза.
Как-то студенты курса по НТ проводили простой эксперимент по оценке влияния повышения ресурсов сервера, на котором крутилась простая веб-страничка c node.js под капотом, практически ничего не делающая. Результат налицо. Теперь храню эту картинку и показываю всем, кто любит «умножать на 10».
PROD (стенд на базе инфраструктуры Продуктивного контура) – опасно, но крайне эффективно
Жиза: Чтобы быть уверенными в высокой доступности новых, серьёзных по нагрузке сервисов, финальные тесты мы проводим здесь. Особенно это актуально, когда у нас мало времени, например, при запуске срочных выплат населению страны последних пары лет.
Пользователи Госуслуг засыпают, а мы собираемся на ночной zoom и аккуратно тестируем на PROD-инфраструктуре. Тюним на месте, записываем изменения конфигов «на лету» себе в тикеты «на утро». Отдельно заказываем новые VM туда, где понимаем, что не успеем дотюниться до запуска сервиса.
Конечно, для этого нужна аккуратная и дотошная подготовка скриптов для очистки мусора после тестов и выверенный чёткий план тестирования с автоматизацией запуска тестов.
Что можно: Конечно, не всё. В первую очередь это стресс-тесты — короткие, точные, до первых узких мест, чтобы затем произвести тюнинг. Можно сразу в онлайне, чтобы не уходить потом на ещё одни работы. Не получится использовать инфраструктуру PROD, если у вас интенсивная пользовательская нагрузка 24/7 и нет микросервисов, которые вы можете изолировать от влияния на пользователей на 99%+.
Для тех, кто по каким-то причинам не хочет в этом участвовать, есть отличный аргумент — или мы сейчас проконтролируем что будет, или будем смотреть на это в онлайне, на живых пользователях и чинить, теряя SLA.
Pros and cons:
+ не только НТ, но и тренировка для команды
+ в нехватке времени можно тюнить на лету (конечно, сохраняя улучшения в репозиториях)
– требуется хорошая подготовка плана и скриптов очистки
– не для каждого сервиса возможно НТ на инфраструктуре PROD
Advice: Все же помнят хорошую практику: всё что выкатывается на PROD должно тестироваться? Это же касается и ваших скриптов НТ, тестовых данных, скриптов очистки от мусора после НТ. Всё должно быть протестировано на младших контурах, считайте, что это такой же релиз.
Ну и конечно, так как НТ на PROD — это часто ночные работы, не замучайте команду в ночь перед запуском важных сервисов. Если не успеваете, лучше ребятам поспать ночь и с утра уже готовиться к проблемам на PROD, быстрее будут реагировать.
Во всём нужна мера, потому что, как говорил один мой знакомый менеджер: «Работа отнимает всё отведенное на неё время».
Вместо заключения
Как видите, у каждого стенда НТ найдутся свои нюансы, а главное – своя польза. Уже давно прошли те времена, когда подрядчик требовал нагрузочный стенд, а заказчик закупал его месяцами, тратя огромные деньги. С новыми средствами НТ и микросервисной архитектурой тесты можно проводить на разных этапах и на разных стендах достаточно быстро.
Я бы описал рекомендованный путь становления процессов НТ в компании по части стендов так:
UAT – отсюда можно стартовать регрессионное НТ
DEV – для новых сервисов, которые будут нагружены
PROD – когда отдельного стенда НТ нет, а ожидается новая большая нагрузка
LT – когда уже научитесь тестировать, поймете систему и действительно сможете использовать дорогое удовольствие с пользой
Конечно, эти стенды у вас могут называться по-другому, типы тестов тоже. Я старался использовать плюс-минус общепринятые понятия. На закрепление терминологии не претендую.
Пишите в комментариях про ваш опыт использования тестовых стендов для НТ. Буду рад почерпнуть что-то новое, в том числе по поводу плюсов и минусов каждого.