Работа со строками в Python: литералы
Это первая часть о работе со строками, а именно о литералах строк.
Литералы строк
Работа со строками в Python очень удобна. Существует несколько литералов строк, которые мы сейчас и рассмотрим.
Строки в апострофах и в кавычках
Экранированные последовательности позволяют вставить символы, которые сложно ввести с клавиатуры.
| Экранированная последовательность | Назначение |
|---|---|
| \n | Перевод строки |
| \a | Звонок |
| \b | Забой |
| \f | Перевод страницы |
| \r | Возврат каретки |
| \t | Горизонтальная табуляция |
| \v | Вертикальная табуляция |
| \N | Идентификатор ID базы данных Юникода |
| \uhhhh | 16-битовый символ Юникода в 16-ричном представлении |
| \Uhhhh… | 32-битовый символ Юникода в 32-ричном представлении |
| \xhh | 16-ричное значение символа |
| \ooo | 8-ричное значение символа |
| \0 | Символ Null (не является признаком конца строки) |
Если перед открывающей кавычкой стоит символ ‘r’ (в любом регистре), то механизм экранирования отключается.
Но, несмотря на назначение, «сырая» строка не может заканчиваться символом обратного слэша. Пути решения:
Строки в тройных апострофах или кавычках
Главное достоинство строк в тройных кавычках в том, что их можно использовать для записи многострочных блоков текста. Внутри такой строки возможно присутствие кавычек и апострофов, главное, чтобы не было трех кавычек подряд.
Это все о литералах строк и работе с ними. О функциях и методах строк я расскажу в следующей статье.
Разметка кода Python, PEP 8
Разметка кода
Рекомендуется придерживаться следующих правил разметки кода
Отступы:
Используйте 4 пробела для добавления отступа.
Последующие строки обернутых элементов в скобки должны быть выравнены либо по вертикали, либо с помощью висящего отступа.
При использовании висячего отступа, следует учитывать следующее: в первой строке не должно быть аргументов, и следует использовать дополнительный отступ, чтобы четко отличить себя как строку продолжения.
Правильно:
Не правильно:
Правило 4 пробелов не является обязательным для строк продолжения.
По желанию:
Закрывающая скобка в многострочных конструкциях может располагаться либо под первым символом последней строки списка:
или может быть на уровне первого символа строки, которая начинает многострочную конструкцию:
TAB или пробелы?
Пробелы являются предпочтительным методом отступа.
Табуляция должна использоваться исключительно для соответствия с кодом, который уже имеет такие отступы.
Python 3 запрещает смешивать использование табуляции и пробелов для отступа. Код с отступом в виде комбинации символов табуляции и пробелов должен быть преобразован исключительно в пробелы.
Максимальная длина строки с кодом:
Ограничьте все строки максимум 79 символами.
Для строк документации или комментариев длина строки должна быть ограничена 72 символами.
Ограничение ширины окна редактора позволяет одновременно открывать несколько файлов и хорошо работает при использовании инструментов обзора, которые представляют две версии кода в соседних окнах.
Перенос по умолчанию в большинстве редакторов нарушает визуальную структуру кода, что делает его более трудным для понимания. Данные ограничения приняты для того, чтобы избежать автоматического переноса строк в редакторах с шириной окна, установленной на 80 символов, даже если он помещает маркер курсора в последний столбец. Некоторые IDE могут вообще не иметь авто-переноса строк.
Некоторые команды разработчиков предпочитают более длинные строки при написании кода. Исключительно для поддержания такого кода внутри команды, разрешается увеличить ограничение длины строки до 99 символов, при условии, что комментарии и документация должна быть ограничена 72 символами
Стандартная библиотека Python консервативна и требует ограничения строки до 79 символов (и строки документации/комментариев до 72).
Еще один такой случай возможен с assert утверждениями.
Удостоверьтесь, что сделали отступ в 4 пробела для продолжения строки кода.
Перенос строки до или после двоичного оператора?
В течение десятилетий рекомендуется переносить строки после двоичного оператора. Но это может усложнить читабельность. При таком переносе, операторы, как правило, разбросаны по разным столбцам, при этом каждый оператор отошел от своей переменной и перешел на предыдущую строку. Здесь глаз должен сделать дополнительную работу, чтобы увидеть, какие элементы добавляются, а какие вычитаются:
Чтобы решить проблему читаемости, математики следуют противоположному соглашению. Следуя традиции математики, обычно получается более читаемый код:
В коде Python допускается перенос до или после двоичного оператора, если есть такое соглашение. Для нового кода предлагается математический стиль.
Пустые строки:
Определения функций и классов верхнего уровня должны быть заключены в две пустые строки.
Определения методов внутри класса заключены в одну пустую строку.
Дополнительные пустые строки могут использоваться для разделения групп связанных функций. Пустые строки могут быть пропущены между связкой связанных строк (например, набором фиктивных реализаций).
Используйте пустые строки в функциях, чтобы указать логические разделы.
Кодировка файла с кодом:
Код в основном дистрибутиве Python всегда должен использовать UTF-8 (или ASCII в Python 2).
Файлы, использующие ASCII (в Python 2) или UTF-8 (в Python 3), не должны иметь декларации кодировки.
Для Python 3.0 и выше, для стандартной библиотеки предписана следующая политика. Все идентификаторы в стандартной библиотеке Python ДОЛЖНЫ использовать идентификаторы только ASCII и ДОЛЖНЫ использовать английские слова везде, где это возможно (сокращения и технические термины, которые не являются английскими). Кроме того, все строковые литералы и комментарии также должны быть в ASCII.
Единственными исключениями являются:
Проектам с открытым исходным кодом с глобальной аудиторией рекомендуется придерживаться аналогичной политики.
Импорт:
Импорт обычно должен быть в отдельных строках:
Это нормально, хотя:
Импорт всегда помещается вверху файла, сразу после любых комментариев и строк документации, а также перед глобальными переменными и константами модуля.
Импорт должен быть сгруппирован в следующем порядке:
Вы должны поставить пустую строку между каждой группой импорта.
Рекомендуется абсолютный импорт, так как он обычно более читабелен и, как правило, ведет себя лучше (или, по крайней мере, дает лучшие сообщения об ошибках), если система импорта настроена неправильно (например, когда каталог внутри пакета заканчивается в sys.path ):
Однако явный относительный импорт является приемлемой альтернативой абсолютному импорту, особенно когда речь идет о сложном макете в пакете, где использование абсолютного импорта было бы излишне многословным:
Код стандартной библиотеки должен избегать сложных макетов пакетов и всегда использовать абсолютный импорт.
Неявный относительный импорт никогда не должен использоваться и был удален в Python 3.
При импорте класса из модуля, обычно можно записать следующее:
Если это написание вызывает локальные конфликты имен, то запишите импорт через точку:
Следует избегать импорта подстановочных знаков ( from import * ), так как из-за этого неясно, какие имена присутствуют в пространстве имен, запутывает как читателей, так и многие автоматизированные инструменты. Существует один оправданный вариант использования для импорта с использованием подстановочного знака, который заключается в повторной публикации внутреннего интерфейса как части общедоступного API.
При повторной публикации имен, все же применяются приведенные ниже рекомендации, касающиеся открытых и внутренних интерфейсов.
Расположение имен «dunders» в коде:
Кавычки в строках:
В Python одинарные и двойные кавычки функционально одинаковы. PEP не дает рекомендации какие из них предпочтительнее. Выберите правило и придерживайтесь его. Если, например, строка содержит одинарные кавычки, чтобы избежать обратной косой черты в строке, используйте дополнительно двойные кавычки. Это улучшает читаемость.
Для строк с тройными кавычками всегда используйте символы двойной кавычки, чтобы соответствовать соглашению с документированной строкой в PEP 257.
Как работает табуляция в python?
TabError: inconsistent use of tabs and spaces in indentation
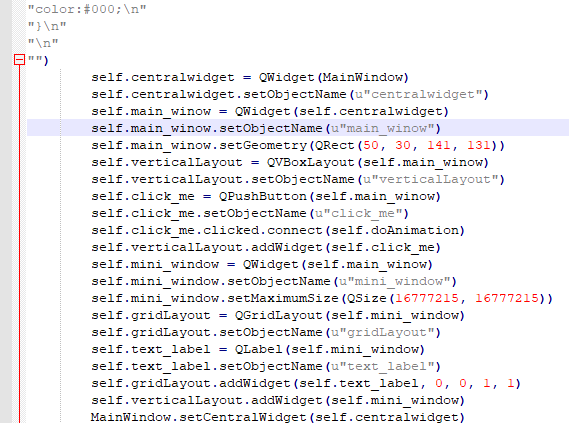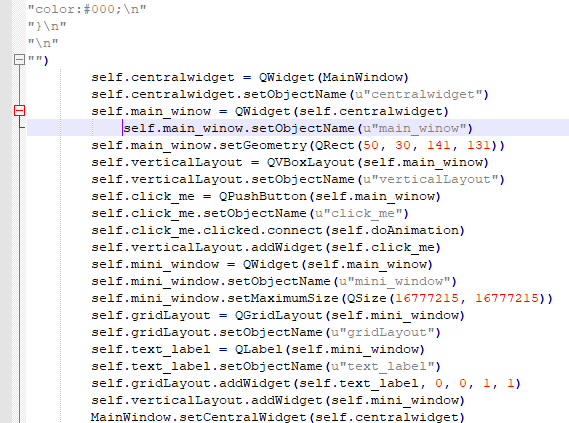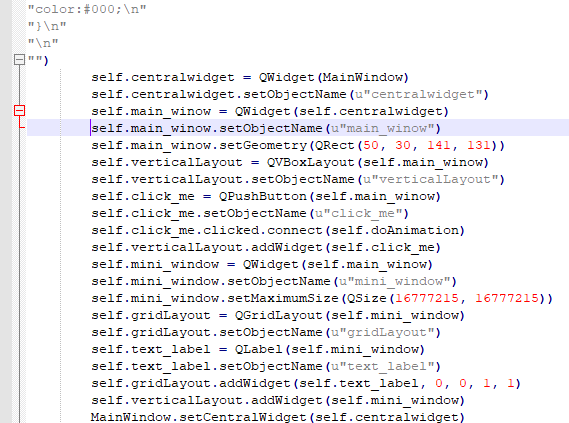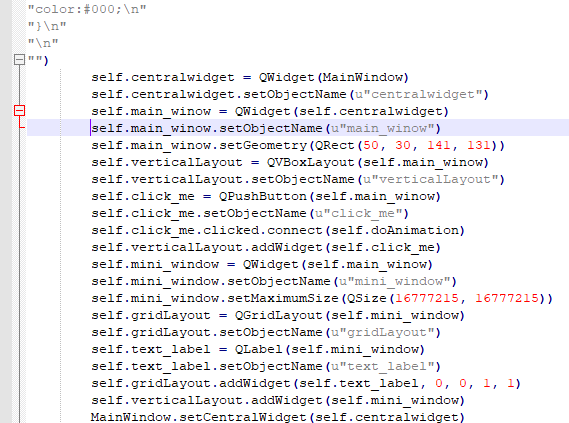
Но я удалил tab а код все равно мне пишет что он там есть
Я не понимаю почему так происходит.
Я буквально нажимаю только TAB и после Backspace и у меня получается такая чехарда
Простой 3 комментария



Описанная вами ошибка происходит из-за смешивания в отступах табов и пробелов.
Иногда редактор не очень понятно показывает вам где у вас табуляция, а где группа пробелов. Этим грешит, например, mcedit.
рецепт прост: никогда не пользуйтесь табами в питоне. Вопрос, конечно, холиварный, но если у вас с табами проблемы, то вам они точно нигде не нужны. Это значит, что вы не можете адекватно настроить редактор и увидеть где табы и где пробелы.
Для вас будет правильным объяснить редактору, что для питоновских файлов следует всегда заменять таб на 4 пробела.
Просто когда я добовляю tab и после удаляю его то код мне выдает ошибку
TabError: inconsistent use of tabs and spaces in indentation
Строки и функция print в Python
Строка представляет собой простую последовательность символов. С ней можно работать разными способами. Любая последовательность символов, заключенная в кавычки, в Python считается строкой. Кавычки могут быть одинарные и двойные.
«Строка Python.»
‘Строка Python.’
Это позволяет использовать внутренние кавычки в строках. «Язык программирования ‘Python’ «. Рассмотрим операции со строками.
| Содержание страницы: |
|---|
| 1. Функция print() |
| 2. Табуляция и разрыв строк |
| 3. Изменение регистра символов в строках |
| 4. F-строки. Форматирование строк |
| 5. Удаление пропусков |
| 6. Комментарии |
Встроенная функция print() выводит свой аргумент в строке текста.
>>> print( ‘Hello world!’ )
Hello world!
>>> print( «Hello world!» )
Hello world
>>> print( «Hello», ‘world!’ )
Hello world
2. Табуляция и разрыв строк в Python.
В программировании термином пропуск ( whitespace ) называются такие непечатаемые символы, как пробелы, табуляции и символы конца строки. Пропуски структурируют текст, чтобы пользователю было удобнее читать его.
В таблице приведены наиболее часто встречаемые комбинации символов.
| Описание | |
|---|---|
| \t | Вставляет символ горизонтальной табуляции |
| \n | Вставляет в строку символ новой строки |
| \\ | Вставляет символ обратного слеша |
| \» | Вставляет символ двойной кавычки |
| \’ | Вставляет символ одиночной кавычки |
>>> print(«Python»)
Python
>>> print(» \t Python»)
Python
>>> print(«Языки программирования: \n Python \n Java \n C»)
Языки программирования:
Python
Java
C
Табуляция и разрыв строк могут сочетаться в тексте. В следующем примере происходит вывод одного сообщения с разбиением на строки с отступами.
>>> print(«Языки программирования: \n\t Python \n\t Java \n\t C»)
Языки программирования:
Python
Java
C
3. Изменение регистра символов в строках в Python.
>>> name = «Hello world!»
>>> print(name. title() )
Hello World!
>>> print(name. upper() )
HELLO WORLD!
>>> print(name. lower() )
hello world!
Метод lower() очень часто используется для хранения данных. Редко при вводе данных все пользователи вводят данные с точным соблюдением регистра. После ввода все данные преобразуются к нижнему регистру и уже затем выводится информация с использованием регистра, наиболее подходящего.
4. F-строки. Форматирование строк в Python.
Часто требуется использовать значения переменных внутри строки. Предположим, что у вас имя и фамилия хранятся в разных переменных и вы хотите их объединить для вывода полного имени.
Python заменить каждую переменную на ее значение при выводе строки.
>>> name = «Александр»
>>> surname = «Пушкин»
>>> full_name = f»
>>> print(full_name)
Александр Пушкин
Буква f происходит от слова format, потому что Python форматирует строку, заменяя имена переменных в фигурных скобках на их значения. В итоге выводится строка имя и фамилия.
>>> name = «александр»
>>> surname = «пушкин»
>>> full_name = f»
>>> print( f» Русский поэт
Русский поэт Александр Пушкин!
>>> message = f» Мой любимый поэт
>>> print(message)
Мой любимый поэт Александр Пушкин
Важно: F-строки впервые появились в Python3.6. Если вы используете более раннею версию, используйте метод format. Что бы использовать метод format(), перечислите переменные в круглых скобках после format.
full_name = «<> <>«.format(name, surname)
5. Удаление пропусков в Python.
| метод | описание |
|---|---|
| rstrip() | удаляет пропуск у правого края |
| lstrip() | удаляет пропуск у правого края |
| strip() | удаляет пропуски с обоих концов |
Python может искать лишние пропуски у правого и левого края строки, так же может удалить с обоих концов строки.
>>> language. rstrip ()
‘ python’
>>> language. lstrip ()
‘python ‘
>>> language. strip ()
‘python’
>>> language
‘ python ‘
Важно: Python не удаляет навсегда эти пропуски в переменной. Чтобы исключить пропуск из строки, следует ее перезаписать.
>>> language = ‘ python ‘
>>> language
‘ python ‘
>>> language = language. strip ()
>>> language
‘python’
Сначала пропуски удаляются методом strip() и потом записываются в исходную переменную.
6. Комментарии в Python.
В Python признаком комментария является символ «решетка» ( # ). Интерпретатор Python игнорирует все символы, следующие в коде после # до конца строки.
>>> print(‘Hello Python’)
Hello Python
>>> # print(‘Hello Python’)
Экранированные последовательности
Для полноценного представления структуры текста или его специфики нам нужны какие-то особые символы. Некоторые символы должны управлять курсором (еще называют «кареткой» – отголосок из прошлого от печатных машинок). Еще нужны какие-то символы с помощью которы можно выполнять какие-нибудь служебные задачи, например, обозначать шестнадцатеричные или восьмеричные коды символов. Для таких целей и существуют экранированные последовательности.
Экранированные последовательности — это последовательности, которые начинаются с символа » \ » за которым следует один или более символов.
Давайте сразу приведем пример:
Обратите внимание на то как функция print() осуществила вывод – в тех местах, где были последовательности ‘ \n ‘ она выполнила переносы строк. Вы, конечно же, догадались, что ‘ \n ‘ – это экранированная последовательность. Единственное, что стоит добавить так это то, что такие последовательности воспринимаются интерпретатором как единственный символ, т.е. несмотря на то что последовательность может состоять из нескольких символов ей соответствует всего один-единственный код. Например:
Таблица последовательностей
Экранированных последовательностей не так уж много, так что давайте сначала перечислим их все в таблице, а потом подробно рассмотрим назначение каждой из них.
| Последовательность | Назначение |
|---|---|
| \newline | Если после символа » \ » сразу нажать клавишу Enter то это позволит продолжать запись с новой строки. |
| \\ | Позволяет записать символ обратного слеша. |
| \’ | Позволяет записать один символ апострофа. |
| \» | Позволяет записать один символ кавычки. |
| \a | Гудок встроенного в систему динамика. |
| \b | Backspace, он же возврат, он же «пробел назад» – удаляет один символ перед курсором. |
| \f | Разрыв страницы. |
| \n | Перенос строки (новая строка). |
| \r | Возврат курсора в начало строки. |
| \t | Горизонтальный отступ слева от начала строки (горизонтальная табуляция). |
| \v | Вертикальный отступ сверху (вертикальная табуляция). |
| \xhh | Шестнадцатеричный код символа (две шестнадцатеричные цифры hh). |
| \ooo | Восьмеричный код символа (три восьмеричные цифры ooo). |
| \0 | Символ Null. |
| \N | ID (идентификатор) символа в базе данных Юникода, или, проще говоря, его название в таблице Юникода. |
| \uhhhh | Шестнадцатеричный код 16-битного символа Юникода (символ кодируемый двумя байтами). |
| \Uhhhhhhhh | Шестнадцатеричный код 32-битного символа Юникода (символ кодируемый четырьмя байтами). |
| \other | Под other понимается любая другая последовательность символов. Не является экранированной последовательностью (остается без изменений с сохранением в строке символа » \ «). |
Примеры
\newline — новая строка
Данный символ позволяет записывать очень длинные «короткие» строки (строки в одинарных кавычках или апострофах) в несколько строк. Как это работает? Просто начните вводить строку, в необходимом месте введите символ » \ » а потом сразу нажмите клавишу Enter и продолжайте ввод строки. Например:
Обратите внимание, что в результирующей строке вообще нет символа » \ «. И не забывайте что пробел тоже является символом, а последовательность \newline не является разделителем:
\\ — обратный слеш
Позволяет указывать в строке необходимое количество обратных слешей, что может пригодиться при работе с файловой системой в Windows или работой с LATEX:
Новичков это немного сбивает с толку, так как они думают, что строка с путем D:\\\\мои документы\\книги\\ является неверной записью пути к директории, хотя это не так, потому что последовательность \\ интерпретируется как одино символ, которому ставится в соответствие один код, в чем легко убедиться:
\’ — апостроф
Последовательность \’ позволяет помещать внутрь строки необходимое количество апострофов:
\» — кавычка
Так же как и \’ позволяет помещать в строку необходимое количество кавычек:
\a — гудок динамика
Последовательность \a заставляет систему издать короткий звуковой гудок, который очень часто используется для предупреждения о чем-либо. Однако, услышите вы этот гудок или нет, как-то зависит от компьютера и операционной системы. Например я сейчас работаю на ноуте под Ubuntu и ничего не слышу, но на стационарном компьютере с Windows 7 все исправно работает. Использовать его или нет решайте сами, но в любом случае, этот символ никогда не выводится на экран:
\b — backspace (пробел назад)
Если вы хоть раз нажимали клавишу Backspace на клавиатуре, то вы уже знаете предназначение этой последовательности – удалять один символ перед курсором:
Если \b находится в конце строки, то удаления не происходит:
Однако, в общем случае все зависит от того сколько символов \b следует подряд друг за другом и что следует за ними:
Последовательность \b – это эхо из эры механических печатных машинок, у которых не было курсора, а была каретка, которую курсор и имитирует. Сейчас клавиша Backspace ассоциируется с удалением символа, но на самом деле, раньше выполнялось перемещение каретки на один символ влево, т.е. на одном и том же месте бумаги можно было напечатать несколько разных символов.
\f — разрыв страницы
Последовательность \f – указывает в каком месте заканчивается одна страница и начинается другая. Раньше он использовался для управления подачей бумаги в принтерах. Когда принтер встречал этот символ, это означало что ему надо было извлеч страницу и загрузить на печать следующий лист бумаги. Сейчас, он может встретиться (и то не факт, что встретится) разве что в исходных кодах некоторых языков программирования, в которых принято соглашение разбивать код на разделы с помощью этого символа. Например, интерпретатор Python способен учитывать \f при расчете отступов при анализе кода.
Данная последовательность переводит курсор на следующую строку и выполняет отступ, длина которого равна длине предшествоваишей \f части строки:
\n — перенос строки
Последовательность \n до банального проста – это просто перенос следующих за ним символов на следующую строку:
\r — возврат каретки
Последовательность \r возвращает курсор в начало строки, т.е. позволяет печатать одни символы «поверх» других. Например:
Параметр end определяет каким символом должна заканчиваться строка, т.е. мы можем сами задать такой символ (или символы):
\t — горизонтальная табуляция
Так же как и \n последовательность \t крайне проста – она просто делает один отступ (равносильно нажатию клавиши Tab):
\v — вертикальная табуляция
\xhh — шестнадцатеричный код символа
Последовательность \xhh позволяет делать запись строк, используя шестнадцатеричный код символов:
\ooo — восьмеричный код символа
Последовательность \ooo позволяет делать запись строк, используя восьмеричный код символов:
\0 — Null
Данная последовательность ведет себя так, словно ее нет. В старые-добрые времена механических принтеров, эта последовательность обозначала простой, т.е. ничего не делать. Сейчас ее можно до сих пор встретить в языке C, в конце символьных строк, причем далее за » \0 » другие цифры следовать не должны, иначе они будут восприниматься как другая экранированная восьмеричная последовательность. Ну а Python этот символ вообще никак не выводит:
Тем не менее этот символ в строке сохраняется и влияет на ее длину.
\N — идентификатор символа Юникода
Позволяет вводить символы в строку используя их название:
\uhhhh — 16-битный символ Юникода
Позволяет вводить символы в строку используя их двухбайтовый шестнадцатеричный код, причем данный способ позволяет вводить только двухбайтовые символы юникода (UTF-16BE):
\Uhhhhhhhh — 32-битный символ Юникода
Позволяет вводить символы в строку используя их четырехбайтовый шестнадцатеричный код, причем данный способ позволяет вводить только четырехбайтовые символы юникода (UTF-32BE):
\other — не экранированная последовательность
Если за символом » \ » следует что-то другое, не перечисленное в данном списке, то это не считается экранированной последовательностью, а обычной строкой в которой на ряду с остальными символами присутствует и символ » \ «:
Но внимательность все же не помешает: