Озеро, хранилище и витрина данных
Рассмотрим три типа облачных хранилищ данных, их различия и области применения.

Озеро данных
Озеро данных (data lake) — это большой репозиторий необработанных исходных данных, как неструктурированных, так и частично структурированных. Данные собираются из различных источников и просто хранятся. Они не модифицируются под определенную цель и не преобразуются в какой-либо формат. Для анализа этих данных требуется длительная предварительная подготовка, очистка и форматирование для придания им однородности. Озера данных — отличные ресурсы для городских администраций и прочих организаций, которые хранят информацию, связанную с перебоями в работе инфраструктуры, дорожным движением, преступностью или демографией. Данные можно использовать в дальнейшем для внесения изменений в бюджет или пересмотра ресурсов, выделенных коммунальным или экстренным службам.
Хранилище данных
Хранилище данных (data warehouse) представляет собой данные, агрегированные из разных источников в единый центральный репозиторий, который унифицирует их по качеству и формату. Специалисты по работе с данными могут использовать данные из хранилища в таких сферах, как data mining, искусственный интеллект (ИИ), машинное обучение и, конечно, в бизнес-аналитике. Хранилища данных можно использовать в больших городах для сбора информации об электронных транзакциях, поступающей от различных департаментов, включая данные о штрафах за превышение скорости, уплате акцизов и т. д. Хранилища также могут использовать разработчики для сбора терабайтов данных, генерируемых автомобильными датчиками. Это поможет им принимать правильные решения при разработке технологий для автономного вождения.
Витрина данных
Витрина данных (data mart) — это хранилище данных, предназначенное для определенного круга пользователей в компании или ее подразделении. Витрина данных может использоваться отделом маркетинга производственной компании для определения целевой аудитории при разработке маркетинговых планов. Также производственный отдел может применять ее для анализа производительности и количества ошибок, чтобы создать условия для непрерывного совершенствования процессов. Наборы данных в витрине данных часто используются в режиме реального времени для аналитики и получения практических результатов.
Озеро, хранилище и витрина данных: ключевые различия
Все упомянутые репозитории используются для хранения данных, но между ними есть существенные различия. Например, хранилище и озеро данных — крупные репозитории, однако озеро обычно более рентабельно с точки зрения затрат на внедрение и обслуживание, поскольку в нем по большей части хранятся неструктурированные данные.
За последние несколько лет архитектура озер данных эволюционировала, и теперь способна поддерживать бо́льшие объемы данных и облачные вычисления. Большие объемы данных поступают от разных источников в централизованный репозиторий.
Хранилище данных можно организовать одним из трех способов:
Витрина данных содержит небольшой по сравнению с хранилищем и озером объем данных, которые разбиты на категории для применения конкретной группой людей или подразделением компании. Витрина данных может быть представлена в виде различных схем (звезды, снежинки или свода), которые определяются логической структурой данных. Формат свода данных (data vault) является самым гибким, универсальным и масштабируемым.
Существует три типа витрин данных:
IBM предлагает различные решения для облачного хранения и интеллектуального анализа данных.
Создание сводной таблицы для анализа данных листа
Сводная таблица — это эффективный инструмент для вычисления, сведения и анализа данных, который упрощает поиск сравнений, закономерностей и тенденций.
Работа с помощью стеблей немного отличается в зависимости от того, какую платформу вы используете для Excel.

Создание в Excel для Windows
Выделите ячейки, на основе которых вы хотите создать сводную таблицу.
Примечание: Ваши данные не должны содержать пустых строк или столбцов. Они должны иметь только однострочный заголовок.
На вкладке Вставка нажмите кнопку Сводная таблица.
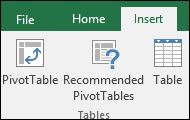
В разделе Выберите данные для анализа установите переключатель Выбрать таблицу или диапазон.
В поле Таблица или диапазон проверьте диапазон ячеек.
В разделе Укажите, куда следует поместить отчет сводной таблицы установите переключатель На новый лист, чтобы поместить сводную таблицу на новый лист. Можно также выбрать вариант На существующий лист, а затем указать место для отображения сводной таблицы.
Настройка сводной таблицы
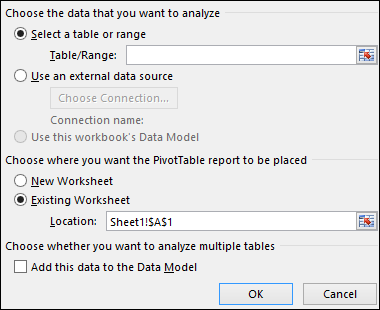
Чтобы добавить поле в сводную таблицу, установите флажок рядом с именем поля в области Поля сводной таблицы.
Примечание: Выбранные поля будут добавлены в области по умолчанию: нечисловые поля — в область строк, иерархии значений дат и времени — в область столбцов, а числовые поля — в область значений.
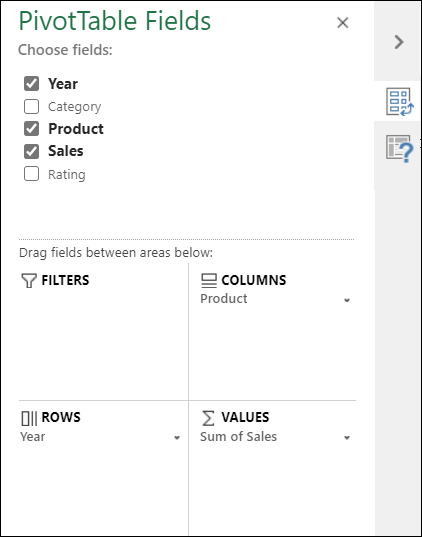
Чтобы переместить поле из одной области в другую, перетащите его в целевую область.
Данные должны быть представлены в виде таблицы, в которой нет пустых строк или столбцов. Рекомендуется использовать таблицу Excel, как в примере выше.
Таблицы — это отличный источник данных для сводных таблиц, так как строки, добавляемые в таблицу, автоматически включаются в сводную таблицу при обновлении данных, а все новые столбцы добавляются в список Поля сводной таблицы. В противном случае вам потребуется либо изменить исходные данные для pivotTable,либо использовать формулу динамического именоваемого диапазона.
Все данные в столбце должны иметь один и тот же тип. Например, не следует вводить даты и текст в одном столбце.
Сводные таблицы применяются к моментальному снимку данных, который называется кэшем, а фактические данные не изменяются.
Если у вас недостаточно опыта работы со сводными таблицами или вы не знаете, с чего начать, лучше воспользоваться рекомендуемой сводной таблицей. При этом Excel определяет подходящий макет, сопоставляя данные с наиболее подходящими областями в сводной таблице. Это позволяет получить отправную точку для дальнейших экспериментов. После создания рекомендуемой сводной таблицы вы можете изучить различные ориентации и изменить порядок полей для получения нужных результатов.
Вы также можете скачать интерактивный учебник Создание первой сводной таблицы.
1. Щелкните ячейку в диапазоне исходных данных или таблицы.
2. Перейдите на вкладку > рекомендуемая ст.
 «Рекомендуемые сводные таблицы» для автоматического создания сводной таблицы» loading=»lazy»>
«Рекомендуемые сводные таблицы» для автоматического создания сводной таблицы» loading=»lazy»>
3. Excel данные анализируются и представлены несколько вариантов, например в этом примере с использованием данных о расходах семьи.

4. Выберите наиболее подбираемую для вас сетовую и нажмите кнопку ОК. Excel создаст сводную таблицу на новом листе и выведет список Поля сводной таблицы.
1. Щелкните ячейку в диапазоне исходных данных или таблицы.
2. Перейдите в > Вставить.
Если вы используете Excel для Mac 2011 или более ранней версии, кнопка «Сводная таблица» находится на вкладке Данные в группе Анализ.

3. Excel отобразит диалоговое окно Создание таблицы с выбранным диапазоном или именем таблицы. В этом случае мы используем таблицу «таблица_СемейныеРасходы».
4. В разделе Выберите, куда следует поместить отчет таблицы выберите новый или существующий. При выборе варианта На существующий лист вам потребуется указать ячейку для вставки сводной таблицы.
5. Нажмитекнопку ОК, Excel создаст пустую стебли и отобразит список полей.
Список полей сводной таблицы
В области Имя поля в верхней части выберите любое поле, которое вы хотите добавить в свою сетную. По умолчанию не числовые поля добавляются в область строк, поля даты и времени — в область Столбец, а числовые — в область значений. Вы также можете вручную перетащить любой доступный элемент в любое поле или, если элемент в ней больше не нужен, просто перетащите его из списка поля или снимите. Возможность переустановить элементы полей — одна из функций, которые упрощают быстрое изменение внешнего вида.
Список полей сводной таблицы
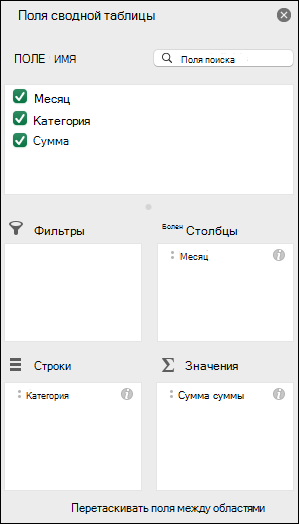
По умолчанию поля в области значений отображаются как СУММ. Если Excel данные интерпретируются как текст, они отображаются как счёт. Именно поэтому так важно не смешивать типы данных для полей значений. Вы можете изменить вычисление по умолчанию, щелкнув стрелку справа от имени поля и выбрав Параметры полей.
Совет: Так как при изменении способа вычисления в разделе Суммировать по обновляется имя поля сводной таблицы, не рекомендуется переименовывать поля сводной таблицы до завершения ее настройки. Вместо того чтобы вручную изменять имена, можно выбрать пункт Найти ( в меню «Изменить»), в поле Найти ввести Сумма по полю, а поле Заменить оставить пустым.
Значения также можно выводить в процентах от значения поля. В приведенном ниже примере мы изменили сумму расходов на % от общей суммы.
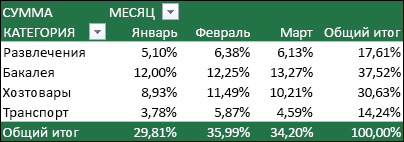
Вы можете настроить такие параметры в диалоговом окне Параметры поля на вкладке Дополнительные вычисления.
Отображение значения как результата вычисления и как процента
Просто перетащите элемент в раздел Значения дважды, щелкните значение правой кнопкой мыши и выберите команду Параметры поля, а затем настройте параметры Суммировать по и Дополнительные вычисления для каждой из копий.
При добавлении новых данных в источник необходимо обновить все основанные на нем сводные таблицы. Чтобы обновить одну сводную таблицу, можно щелкнуть правой кнопкой мыши в любом месте ее диапазона и выбрать команду Обновить. При наличии нескольких сводных таблиц сначала выберите любую ячейку в любой сводной таблице, а затем на ленте откройте вкладку Анализ сводной таблицы, щелкните стрелку под кнопкой Обновить и выберите команду Обновить все.
Если вы создали и решили, что вам больше не нужна, вы можете просто выбрать весь диапазон, а затем нажать кнопку УДАЛИТЬ. Она не влияет на другие данные, с ее стебли или диаграммы. Если сводная таблица находится на отдельном листе, где больше нет нужных данных, вы можете просто удалить этот лист. Так проще всего избавиться от сводной таблицы.
Примечание: Мы постоянно работаем над улучшением работы с Excel для Интернета. Новые изменения внося постепенно, поэтому если действия, которые вы в этой статье, возможно, не полностью соответствуют вашему опыту. Все обновления в конечном итоге будут обновлены.
Выберите таблицу или диапазон данных на листе, а затем выберите Вставить >, чтобы открыть область Вставка таблицы.
Вы можете вручную создать собственную или рекомендованную советку. Выполните одно из следующих действий:
Примечание: Рекомендуемые стеблицы доступны только Microsoft 365 подписчикам.
На карточке Создание собственной таблицы выберите Новый лист или Существующий лист, чтобы выбрать место назначения для этой таблицы.
В рекомендуемой pivottable выберите Новый лист или Существующий лист, чтобы выбрать место назначения для этой таблицы.
Метод моделирования «Свод данных»
Изучив материал настоящей лекции, вы будете знать:
Введение
Свод данных ( Data Vault) как метод моделирования данных для ХД был предложен в конце 2002 года Dan Linstedt [57]. Метод моделирования «Свод данных» — это методология проектирования, разработанная для глобальных ХД масштаба предприятия и имеющая в основе набор связанных нормализованных таблиц, ориентированных на поддержку функциональных областей бизнеса с возможностью отражения истории. Метод удачно сочетает требования нормализации и возможности схемы » звезда «.
Использование этого метода предполагает наличие у проектировщика ХД базового уровня знаний в области моделирования данных, т.е. понимание таких терминов, как таблица ( table ), взаимосвязь ( relationship ), родитель ( parent ), потомок ( child ), ключ (primary/foreign key), измерение ( dimension ) и факт ( fact ).
Такой разрыв между формой, функцией и выполнением снижает эффективность использования методов AI и DM. Поэтому задача разработки структур данных, которые математически позволяют использовать технологии AI непосредственно в базах данных, остается очень актуальной. С точки зрения моделирования структур данных метод Data Vault основан на математических принципах, которые позволяют эффективно управлять большими объемами информации. Особенно этот метод эффективен для создания структур данных для динамического управления изменениями во взаимосвязях между данными как единицами представления информации в компьютерных системах. Он позволяет динамически управлять изменением взаимосвязей между данными в системе в процессе эволюции сохраняемых в ней данных.
Метод моделирования «Свод данных» (Data Vault)
Определение метода проектирования «Свод данных» (Data Vault)
Свод данных (Data Vault), по определению, является ориентированным на детали набором нормализованных связанных таблиц, которые обеспечивают информационную поддержку одной или более предметных областей деятельности организации. Этот подход является комбинацией методики реляционного проектирования (до третьей нормальной формы — 3NF ) и методики многомерного проектирования. Метод моделирования «Свод данных» был разработан для создания моделей данных глобальных ХД масштаба предприятия. Он основан на математических принципах, которые поддерживают нормализованные модели данных. По существу модель «Свод данных» соответствует нормализованной до 3NF схеме «звезда», включая измерения, связи «многие ко многим» и таблицы стандартной структуры. Различие лежит в более детальном представлении взаимосвязей и элементов данных, структурированных и детализованных во временном изменении. Этот метод проектирования был разработан, чтобы объединить гибкость структур обработки данных OLTP-систем с мощностью аналитической обработки данных в OLAP-системах. Он является масштабируемым и легко адаптируемым методом разработки структур данных для решения задач анализа данных в масштабах предприятия.
Проблемы моделирования данных для хранилищ данных
Обычно применение известных методик проектирования к разработке модели ХД масштаба предприятия, например, таких как нормализация, сталкивается с рядом трудностей.
В частности, использование 3NF для структур данных приводит к следующему.

Одной из наиболее сложных проблем взаимосвязанных киосков данных является выбор правильного уровня гранулированности данных ( grain ) для таблиц фактов. Это означает, что агрегирование данных во всех таблицах будет согласованным по измерению времени, а структура каждой таблицы фактов не будет изменяться с точки зрения добавления новых измерений. Такой подход к проектированию ограничивает масштабируемость и гибкость модели данных. Другой проблемой могут быть вспомогательные таблицы в измерениях, которые обслуживают ссылки для взаимоотношений между измерениями. Гранулированность и стабильность измерений являются важными факторами успешного проектирования ХД.
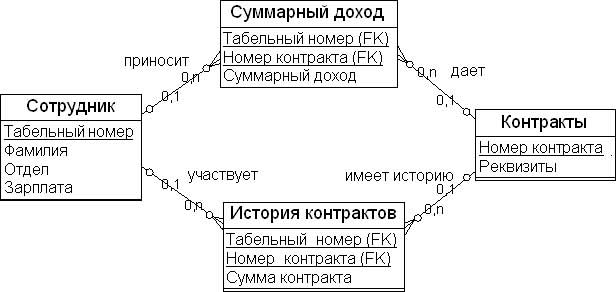
Элементы модели «Свод данных»

Рис. 18.3 показывает пример сущности «Концентратор для покупателей». В этой сущности атрибут «Номер покупателя в источнике данных» является первичным бизнес- ключом, а атрибут «Номер» является суррогатным ключом, назначенным для покупателей внутри системы. В табл. 18.1 приведен пример контекста для сущности «Концентратор для покупателей».
| Номер | Номер покупателя в источнике данных | Время загрузки из источника | Наименование источника данных |
|---|---|---|---|
| 1 | 1234 | 23.01.2009 | Продажи |
| 2 | 1235 | 24.01.2009 | Контракты |
| 3 | 2266 | 26.01.2009 | Финансы |
| 4 | 2344 | 28.01.2009 | Продажи |
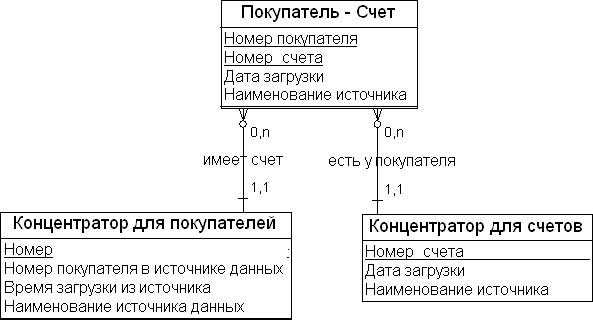
Этот компонент модели предназначен для разрешения проблемы отношения «многие ко многим» для ХД. Вместе с сущностями-концентраторами связывающие сущности описывают поток данных предметной области ХД. Табл. 18.2 иллюстрирует содержание соответствующих сущностям таблиц БД.
Метод моделирования «Свод данных»
Алгоритм построения модели «Свод данных» (Data Vault)
При создании модели «Свод данных» необходимо сначала создать сущности и описать их атрибуты, а затем установить связи между ними. Сущности должны создаваться в следующем порядке.
При создании связей в структуре модели «Свод данных» следует соблюдать правила поддержки ссылочной целостности ( referential integrity ).
Изменения в данных собираются в сателлитах. Если размер сателлитов растет очень быстро, то можно создать два новых сателлита, чтобы ограничить такой процесс роста. Данные в новых сателлитах могут разделяться по типу информации или по скорости изменения.
Теперь рассмотрим применение вышеизложенного алгоритма на учебном примере, т.е. построим модель «Свод данных» для схемы учебного примера.
Пример проектирования модели «Свод данных»
Учебная база данных
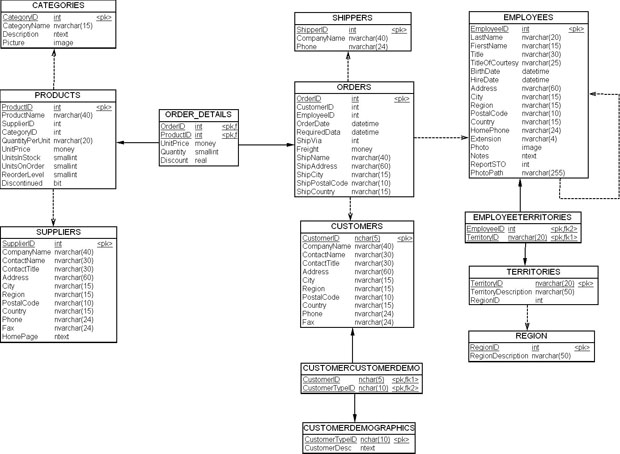
Рассмотрим БД Northwind, которая разработана Microsoft в учебных целях. Ее модель данных приведена на рис. 18.8.
Как видно из рисунка, для этой модели характерно использование нестандартных типов данных: bit, ntext, image, money. Использование нестандартных типов данных может привести к проблемам преобразования данных, если для создания ХД будет использована другая СУБД, чем в OLTP-системе. В нашем случае «Свод данных» будет построен на основе той же СУБД, что и OLTP, а именно для MS SQL Server 2008 компании MicroSoft.
Процесс моделирования «Свода данных»
Рассмотрим процесс преобразования нормализованной модели примера ( рис. 18.7) в модель «Свод данных». Процесс преобразования, как было рассмотрено в предыдущих разделах, включает следующие этапы.
Отметим сразу же, что для модели учебного примера добавление сущностей-мостов и сущностей «Момент времени» не требуется.
В случае работы более чем с одной моделью данных (интеграция нескольких источников данных) преобразование следует начитать с модели главной с точки зрения направлений деятельности организации системы, а затем поэтапно рассматривать модели других подсистем с целью получения унифицированной точки зрения на представление данных в модели системы в целом.
Теперь перейдем к реализации пунктов 1-3 процесса формирования модели «Свод данных» для учебного примера.
Формирование сущностей-концентраторов
Будем следовать рассмотренному нами процессу построения модели «Свод данных». Сначала идентифицируем бизнес-ключи и поместим их в сущности-концентраторы стандартной структуры. Так как концентраторы являются по определению списком бизнес-ключей, важно разместить их вместе с суррогатными ключами, если такие существуют в модели.
Проведя исследование модели на рис. 18.8 (уникальные индексы, запросы к данным и т.д.), мы сможем построить следующие группы бизнес-ключей/суррогатных ключей и определим сущности, претендующие на роль концентраторов в модели «Свод данных».
Таблица «Категории» ( Categories ) имеет бизнес-ключ «Имя категории» ( CategoryName ) и суррогатный ключ «Идентификатор категории» ( CategoryID ). Они будут составными элементами сущности-концентратора «Концентратор_Категория» ( HUB_Category ).
Таблица «Товары» ( Products ) имеет бизнес-ключ «Наименование товара» ( ProductName ) и суррогатный ключ «Идентификатор товара» ( ProductID ). Они будут составными элементами сущности-концентратора «Концентратор_Товар» ( HUB_Product ).
Таблица «Поставщики» ( Suppliers ) имеет бизнес-ключ «Наименование поставщика» ( SupplierName ) и суррогатный ключ «Идентификатор поставщика» ( SupplierID ). Они будут составными элементами сущности-концентратора «Концентратор_Поставщик» ( HUB_Supplier ).
Таблица «Позиции заказа» ( Order Details ) не имеет бизнес-ключа, она не представляет бизнес-процесс и, следовательно, не может иметь свой концентратор.
Таблица «Грузоперевозчики» ( Shippers ) имеет бизнес-ключ «Наименование компании» ( CompanyName ) и суррогатный ключ «Идентификатор грузоперевозчика» ( ShipperID ). Они будут составными элементами сущности-концентратора «Концентратор_Перевозчик» ( HUB_Shippers ). Заметим, что если бизнес-требования требуют интеграции компаний-грузоперевозчиков, то поле «Наименование компании» ( CompanyName ) может быть использовано как бизнес-ключ. Однако если бизнес-требования требуют, чтобы грузоперевозчики поддерживались в системе отдельно друг от друга, то указанное поле не является достаточно описательным для бизнес-процесса и должно быть заменено полем «Наименование грузоперевозчика» ( ShipperName ).
Таблица «Покупатели» ( Customers ) имеет бизнес-ключ «Наименование компании» ( CompanyName ) и суррогатный ключ «Идентификатор покупателя» ( CustomerID ). Они будут составными элементами сущности-концентратора «Концентратор_Покупатели» ( HUB_Customers ). Обратим внимание на то, что если нужна интеграция покупателей и грузоперевозчиков, то концентратор может быть назван «Концентратор_Компания» ( HUB_Company ), чтобы интегрировать грузоперевозчиков и покупателей.
Таблица «Демография покупателей» ( CustomerDemographics ), на первый взгляд, имеет бизнес-ключ CustomerDesc и суррогатный ключ CustomerTypeID, и для нее может быть создан концентратор «Концентратор_Демография_покупателей» ( HUB_CustomerDemographics ). Однако отметим, что эта таблица может рассматриваться и как сущность-сателлит для покупателей.
Таблица «Служащие» ( Employees ) имеет бизнес-ключ «Имя служащего» ( EmployeeName ) и суррогатный ключ «Идентификатор служащего» ( EmployeeID ). Они будут составными элементами сущности-концентратора «Концентратор_Служащий» ( HUB_Employee ).
Таблица «Территория» ( Territories ) имеет бизнес-ключ «Описание территории» ( TerritoryDescription ) и суррогатный ключ «Идентификатор территории» ( TerritoryID ). Они будут составными элементами сущности-концентратора «Концентратор_Территория» ( HUB_Territories ).
Таблица «Регион» ( Region ) имеет бизнес-ключ «Описание региона» ( RegionDescription ) и суррогатный ключ «Идентификатор региона» ( RegionID ). Они будут составными элементами сущности-концентратора «Концентратор_Регион» ( HUB_Region ).
Сейчас мы можем сформировать список сущностей-концентраторов модели, которые должны быть построены ( рис. 18.9).
| «Концентратор_Категория» | Hub_Categories |
| «Концентратор_Товар» | Hub_Producst |
| «Концентратор_Поставщик» | Hub_Suppliers |
| «Концентратор_Перевозчик» | Hub_Shippers |
| «Концентратов_Компания» | Hub_Customers |
| «Концентратор_Демография_покупателей» | Hub_CustomerDemographics |
| «Концентратор_Служащий» | Hub_Employees |
| «Концентратор_Территория» | Hub_Territories |
| «Концентратор_Регион» | Hub_Region |
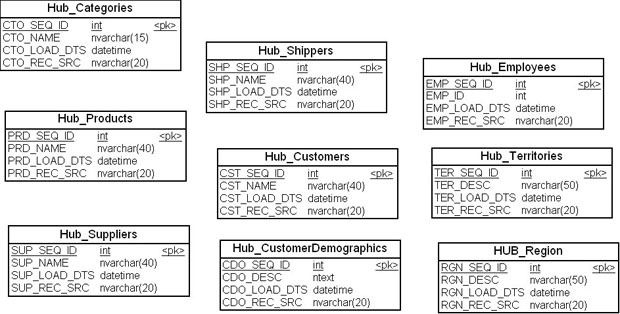
Для обозначения бизнес-ключей будем использовать иные наименования, чем на схеме рис. 18.8.
На рис. 18.10 приведен окончательный список сущностей-концентраторов для модели учебного примера.
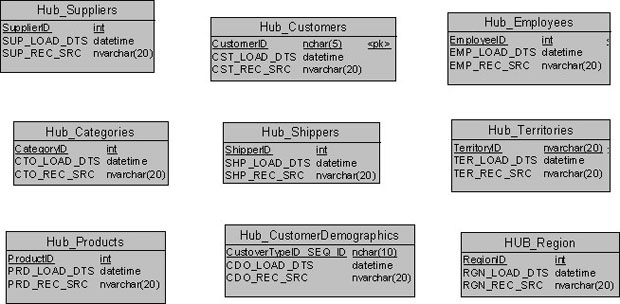
Теперь мы можем перейти к формированию сущностей-связей для модели «Свод данных» учебного примера.