Требования ACID на простом языке
Мне нравятся книги из серии Head First O`Reilly — они рассказывают просто о сложном. И я стараюсь делать также.
Когда речь идёт о базах данных, могут всплыть магические слова «Требования ACID». На собеседовании или в разговоре разработчиков — не суть. В этой статье я расскажу о том, что это такое, как расшифровывается ACID и что означает каждая буква.
Требования ACID — набор требований, которые обеспечивают сохранность ваших данных. Что особенно важно для финансовых операций. Мы же не хотим остаться без денег из-за разрыва соединения или ошибки в ПО, не так ли?
Давайте пройдемся по каждой букве ACID и посмотрим на примерах, чем архив лучше 10 разных файлов. И чем транзакция лучше 10 отдельных запросов.
Atomicity — Атомарность
Атомарность гарантирует, что каждая транзакция будет выполнена полностью или не будет выполнена совсем. Не допускаются промежуточные состояния.
Друг познается в беде, а база данных — в работе с ошибками. О, если бы всё всегда было хорошо и без ошибок! Тогда бы никакие ACID были бы не нужны. Но как только возникает ошибка, атомарность становится очень важна.
Допустим, вы решили отправить маме деньги. Когда вы делаете перевод внутри банка, что происходит:
У вас деньги списались

И допустим, что у нас 2 отдельных запроса. А теперь посмотрим, что будет при возникновении ошибок:
1. У вас на балансе нет нужной суммы — система вывела сообщение об ошибке, но катастрофы не произошло, атомарность тут не нужна.
2. У мамы заблокирована карточка, истек срок годности — деньги ей не поступили. Запрос отменен. Но минуточку. У вас то они уже списались!
Ошибка на первом этапе никаких проблем в себе не таит. А вот ошибка на втором. Приводит к потере денег, что явно недопустимо.
Если мы отправляем отдельные запросы, система не может связать их между собой. Запрос упал с ошибкой? Система его отменяет. Но только его, ведь она не знает о том, что запрос «у меня деньги спиши» связан с упавшим «сюда положи»!
Транзакция же позволяет сгруппировать запросы, то есть фактически показывает базе на взаимосвязи между ними. База сама о связях ничего не знает! Это знаете только вы =)
И если падает запрос внутри транзакции, база откатывает всю транзакцию. И приходит в состояние «как было до начала транзакции». Даже если там внутри было 10 запросов, вы можете спать спокойно — сломался один, откатятся все.
Consistency — Согласованность
Транзакция, достигающая своего нормального завершения (EOT — end of transaction, завершение транзакции) и, тем самым, фиксирующая свои результаты, сохраняет согласованность базы данных. Другими словами, каждая успешная транзакция по определению фиксирует только допустимые результаты wikipedia
Это свойство вытекает из предыдущего. Благодаря тому, что транзакция не допускает промежуточных результатов, база остается консистентной. Есть такое определение транзакции: «Упорядоченное множество операций, переводящих базу данных из одного согласованного состояния в другое». То есть до выполнения операции и после база остается консистентной (в переводе на русский — согласованной).
Например, пользователь в системе заполняет карточку:
Телефон — отдельно код страны, города и номер
Что такое согласованность данных
Как мы уже отмечали, одним из преимуществ Кассандры является возможность задания уровня согласованности для операций чтения и записи данных. В этой статье рассмотрим, какие бывают уровни согласованности для этих процессов в Apache Cassandra, и как они влияют на скорость работы распределенной NoSQL-СУБД при ее эксплуатации в реальных Big Data проектах.
Что такое согласованность и зачем она нужна
Вообще, разговор о согласованности данных в распределенных системах стоит начать с CAP-теоремы (согласованность, доступность, устойчивость) [1], однако это тема отдельной статьи. Apache Cassandra полностью реализует принципы доступности (Availability) и устойчивости к разделению (Partition tolerance), обеспечивая корректный отклик на любой запрос и простоту масштабирования. Однако, согласованность (Consistency), т.е. непротиворечивость данных считается слабым местом этой распределенной СУБД в связи с ее децентрализацией, когда на множестве узлов хранятся разные реплики одной и той же информации. Для устранения этой проблемы используется механизм настройки уровней согласованности.
Напомним, в отличие от другой популярной NoSQL-базы данных для Big Data, Apache HBase, все узлы кластера Cassandra равноценны – клиенты могут соединятся с любым из них для записи и чтения. При этом выполнение запроса начинается с его координации, чтобы с помощью ключа и меток определить, на каких узлах кластера находятся нужные данные и отправить запрос именно туда. Узел, выполняющий координацию, называется координатором (coordinator), а узлы, которые выбраны для сохранения записи с данным ключом — узлами-реплик (replica nodes). Физически координатором может быть один из узлов-реплик [2].
Можно сказать, что доступность данных напрямую зависит от уровня согласованности операций чтения и записи, так как он определяет, сколько узлов-реплик может отказать при подтверждении успешного выполнения этих операций. Например, если уровень репликаций меньше, чем сумма узлов, с которых пришло подтверждения об успешной записи данных, и с которых происходит чтение, то есть гарантия строгой согласованности (strong consistency). Строгая согласованность гарантирует, что после записи новое значение всегда будет прочитано. Иначе возможна ситуация, когда в результате чтения СУБД возвратит устаревшие данные.
Для борьбы с этим в Apache Cassandra есть механизм итоговой согласованности (eventual consistency), который распространит данные по узлам-репликам после того, как закончится координационное ожидание. Если при этом будут доступны не все узлы-реплики, то придется задействовать другие средства восстановления данных, в частности, чтение с исправлением и запускаемое вручную анти-энтропийное восстановление узла (anti-entropy node repair) [2].
 Распределенная запись данных в кластере Apache Cassandra
Распределенная запись данных в кластере Apache Cassandra
Согласованная запись в NoSQL-СУБД Кассандра
При записи данных уровень согласованности определяет количество узлов-реплик, с которых будет ожидаться подтверждение удачного окончания операции – сигнала того, что данные успешно записаны. Для записи существуют такие уровни согласованности [2]:
Согласованное чтение Big Data в Apache Cassandra
В случае чтения уровень согласованности определяет количество узлов-реплик, с которых будет считана информация [2]:
Как уровни согласованности влияют на быстроту работы NoSQL СУБД
Подводя итог возможным уровням согласованности в Apache Cassandra, можно сделать следующие выводы [2]:
По умолчанию для всех операций в Apache Cassandra используется уровень согласованности ONE. Отметим, что в ранних версиях этой NoSQL-СУБД задать уровень согласованности можно было прямо в самом CQL-запросе, например, так [3]:
SELECT * FROM users WHERE state=’TX’ USING CONSISTENCY QUORUM;
Однако, начиная с версии 1.2 (2012 год) разработчики убрали эту возможность, аргументируя тем, что согласованность операции должна устанавливаться не в рамках запроса, а на уровне протокола ее выполнения [3]. Таким образом, сегодня установить consistency level в Кассандре можно двумя следующими способами:
from cassandra import ConsistencyLevel
from cassandra.query import SimpleStatement
“INSERT INTO users (name, age) VALUES (%s, %s)”,
session.execute(query, (‘John’, 42))
Напомним, cqlsh поддерживает ряд специальных команд, которые не являются частью CQL, используя драйвер собственного протокола Python при подключении к узлу, указанному в командной строке [5].
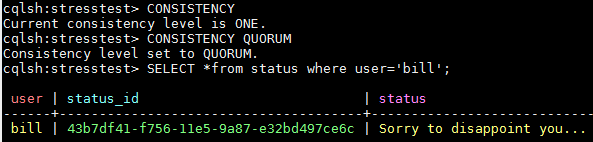 Пример установки уровня согласованности Кассандры в оболочке командной строки cqlsh
Пример установки уровня согласованности Кассандры в оболочке командной строки cqlsh
В следующей статье мы подробнее расскажем, как именно выполняются процессы записи и считывания больших данных (Big Data) в Apache Cassandra с учетом рассмотренных уровней согласованности.
Обмен данными. Консистентность vs Многопоточность
не должно быть такого валидного изменения системы А, которое приведет к тому, что обмен переведет систему Б в невалидное состояние
Какие же возможны варианты? Все богатство случаев с битыми ссылками, не хватающими остатками, разными ставками НДС и прочим и прочим можно свести к трем следующим вопросам:
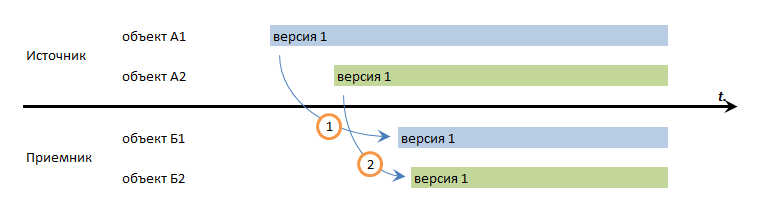
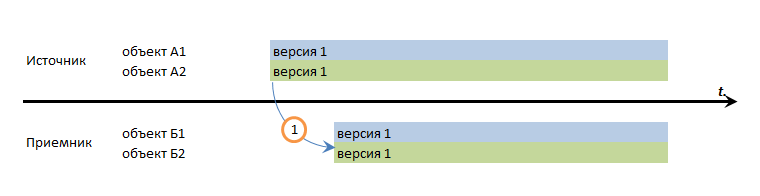
Транзакционная последовательность
Этот уровень последовательности похож на то как SQL сервер делает бэкапы: он просто хранит лог транзакций и в случае необходимости накатывает их последовательно на БД.
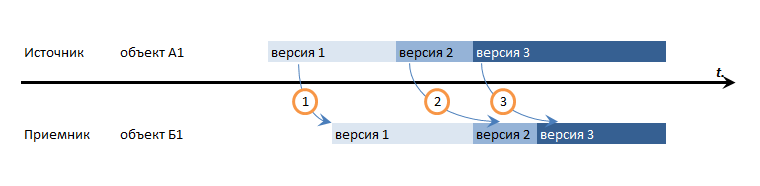
Это единственный вариант, который гарантированно разрулит вообще все возможные недоразумения, включая перекрестные ссылки. Но в 1С он не достижим: мы не можем контролировать начало и фиксацию транзакции в 1С с тем, чтобы повторить тоже самое в источнике. Можно конечно попробовать опуститься на уровень SQL, но этот путь полон граблей и мы тут в общем про 1С, а не про MS SQL.
Хронологическая последовательность
Нужно складывать все версии всех объектов в отдельное место, не допуская никаких пропусков, подобно тому, как это делает подсистема Версионирование объектов и на стороне приемника воспроизводить эту последовательность.
Этот обмен с высокой долей вероятности разрулит перекрестный ссылки (если они организованы пользователем, а не кодом в одной транзакции). Также он справится с жесткими последовательными переходами (это пояснено чуть ниже).
Что вообще может пойти не так
На самом деле, случаев когда ни один уровень гарантии последовательности (кроме транзакционной или хронологической) не может обеспечить согласованность данных больше чем кажется.
Партионно-последовательная
Основным плюсом этой истории являет значительно оптимизированная ресурсоемкость при частых изменениях и нечастых обменах: не нужно хранить безумное число копий одного и того же объекта, не нужно записать в приемнике по 100 раз то, что можно записать однажды. Также, если говорить о переходе от логики «НомерСообщения меньше или равно» к логике «НомерСообщения равно» есть некое ослабление эффекта снежного кома: во-первых объекты имеют тенденцию к «утеканию» из ранних партий, во-вторых, ограниченность каждой партии способствует продвижению вперед при проблемах: валится один конкретный кусочек, вместо большого снежного кома.
Последовательность основанная на данных
Этот алгоритм точно знает, что бизнес-логика такова, что одни объекты надо прогружать раньше чем другие (например, номенклатуру раньше поступлений, поступления раньше реализаций) и гарантирует эту последовательность. Вообще, в «чистой» реализации, этот принцип должен быть доведен до следующего абсолюта:
На практике же, обмены редко бывают онлайновыми и скорее всего, последовательность основанная на данных будет применяться внутри какой-то сессии обмена (а это собственно и есть уровень гарантий Конвертации данных)
Реализовать довольно просто: нужно иметь табличку приоритетов и табличку изменений и грузить изменения, отсортированные по приоритетам. Номера сообщений при этом можно выкинуть, не обращать на них никакого внимания.
Последовательность Шредингера или согласованность в конечном счете
О транспортном уровне
Вообще, транспортный уровень не такая интересная тема, но скажем пару слом и о нем. Лучшие результаты достигаются при отделении друг от друга процессов транспорта и распаковки от процессов применения изменений т.е. в результате работы транспортного слоя мы уже должны видеть что нам предстоит сделать в части записи и иметь возможность манипулировать этими задачами не на уровне одной большой черной коробки. Фактически, если использовать складскую аналогию, принятая в 1С тактика такова:
Сами понимаете, на складах это так не работает. Работает так:
В этом смысле, алгоритм принимающий решение о том что грузить, в какой последовательности и что делать при фэйлах должен иметь перед собой картину того что предстоит сделать. Это может быть таблица (регистр сведений) вида: тип объекта, идентификатор объекта, данные объекта и всякая мета-информация вроде того откуда и когда этот объект пришел и сколько раз и с каким результатом его пытались записать.
Графовая согласованность
Так же как согласованность в конечном счете, с дополнительной проверкой ссылочной целостности
Высокая производительность (оценить выше/ниже согласованности в конечном счете не так просто, поскольку дополнительные затраты на проверку графа в одном случае могут нивелироваться отсутствием некоторого количества неудачных попыток в другом), учет связей между объектами при независимости реализации от условий конкретной конфигурации.
Это нереализуемо на 1С: реляционная БД не позволит выстраивать граф с приемлемой производительностью. Для этого потребуются noSQL решения вроде ElasticSearch.
Заключение
Согласованность данных в высоконагруженных системах
Проблематика
Практически любая информационная система требует хранения данных на постоянной основе. В большинстве систем с малой и средней нагрузкой эту функцию выполняют реляционные СУБД, неоспоримым преимуществом которых является гарантия согласованности данных.
Классический пример, объясняющий, что такое согласованность данных – операция перевода денежных средств с одного счёта на другой. В момент, когда операция изменения баланса одного счёта уже выполнилась, а другого – ещё не успела, может произойти сбой. Тогда с одного счёта средства будут списаны, а на другой не поступят. Такое состояние данных системы называется рассогласованным, и, пожалуй, нет необходимости объяснять, к каким последствиям это может привести. Реляционные СУБД предоставляют механизм транзакций, гарантирующий согласованность данных в любой момент времени. Транзакция – это конечный набор операций, который переводит одно согласованное состояние в другое согласованное состояние. В случае ошибки на любом шаге СУБД отменяет все выполненные ранее операции и возвращает данные к первоначальному согласованному состоянию. Иными словами – либо выполнятся все операции, либо ни одной.
Что касается крупномасштабных систем, то в них далеко не всегда возможно использовать единую базу данных из-за слишком большой нагрузки. В таких случаях каждому модулю системы (сервису) предоставляется своя отдельная база данных. В этом случает встаёт вопрос как для такой кластерной архитектуры обеспечить согласованность данных.
Решение проблемы согласованности данных
Один из вариантов решения – распределённые транзакции. Сначала все узлы кластера должны согласиться, что выполнение операции возможно, затем выполняется фиксация изменений на всех узлах. Поскольку никакого общего устройства хранения у узлов нет, то единственный способ прийти к общему мнению — договориться, используя какой-либо протокол распределенного консенсуса.
Простой протокол для фиксации глобальных транзакций — двухфазный коммит (2PC). Узел, выполняющий транзакцию, считается координатором. На подготовительной фазе (prepare) координатор сообщает остальным узлам о фиксации транзакции и дожидается от них подтверждения, что они готовы выполнить фиксацию. Если хотя бы один узел не готов — транзакция обрывается. На фазе фиксации (commit) координатор сообщает всем узлам о решении зафиксировать транзакцию. При получении от всех подтверждения, что все ок, координатор тоже фиксирует транзакцию.
Рисунок 1 – Общая схема двухфазного коммита
Этот протокол позволяет обойтись минимумом сообщений, но не устойчив к сбоям. Например, при отказе координатора после фазы prepare, остальные узлы не имеют информации о том, должна ли транзакция быть зафиксирована или отменена (им придется ждать устранения сбоя). Ещё один серьёзный недостаток 2PC (и других протоколов распределённых транзакций, например 3PC) – при росте количества узлов кластера производительность двухфазных коммитов падает.
Рисунок 2 – Зависимость скорости выполнения двухвазного коммита от количества серверов в кластере СУБД
Кроме того, подход распределённых транзакций накладывает ограничение: все модули системы должны использовать одну и туже СУБД, что не всегда удобно.
Другой вариант – обеспечить некий механизм, позволяющий работать с различными базами данных (для сервисов) как с единой базой данных (решить проблему с целостностью данных в распределённой базе). При этом требуется некий аналог транзакции для распределённой системы («бизнес-транзакция»).
В обычных транзакциях, а также в двухфазных коммитах, все операции контролируются механизмом транзакций (с использованием блокировок), и это делается с целью обеспечить возможность откатить любую операцию (пессимистический подход – любую операцию считаем потенциально вызывающей сбой). Это является узким местом системы. Альтернативный вариант – так называемый оптимистический подход: считаем, что большинство операций завершаются успешно. Дополнительные же действия производим уже по факту произошедшего сбоя. Т.е. уменьшаем издержки для большинства операций, что приводит к повышению производительности.
Что такое Saga (Сага) и как она работает
Альтернативой транзакциям для микросервисной архитектуры является Saga. Saga (сага) представляет собой набор шагов, выполняемых различными модулями системы (сервисами); так же требуется сервис саги, отвечающий за операцию (бизнес-транзакцию) в целом. Шаги связаны через граф событий. После выполнения саги система должна перейти из одного согласованного состояния в другое (в случае успешного выполнения), или вернутся к предыдущему согласованному состоянию (в случае отмены).
Как реализовать такой возврат или откат бизнес-транзакции? Для этого в сагах используется механизм отменяемости шагов (компенсирующие действия). Например, один из шагов был выполнен успешно (допустим в таблицу базы данных пользователей была добавлена запись), но на одном из следующих шагов произошёл сбой, и всю сагу следует отменить. Тогда этому же сервису поступает команда – отменить действие. Но в СУБД сервиса локальная транзакция уже завершена, запись пользователя добавлена. Тогда для возврата к предыдущему состоянию сервис должен выполнить компенсирующее действие (в нашем примере – удалить запись). Отменяемость шагов позволяет реализовать в рамках саги атомарность (Atomicity) – «всё или ничего» — все шаги выполняются или компенсируются.
Рисунок 3 – Механизм работы Saga и природа компенсирующего действия
На рисунке 3 шаги саги обозначены как T1. T4, компенсирующие действия: C1. C4.
Саги поддерживают идемпотентность шагов (действие, многократное повторение которого эквивалентно однократному). Подход саг обеспечивает возможность повторить любой шаг (например, если не получили отклик об успешном завершении). Так же идемпотентность позволяет восстановить состояние при потере данных на каком-либо узле (сбой и восстановление). При выполнении шага каждый сервис должен определять (по ключу идемпотентности) выполнял он уже этот шаг, или нет (если нет – выполнить, иначе — пропустить). Для компенсирующих действий тоже возможно добавление ключей идемпотентности и повторы операций (обеспечение персистентности/устойчивости).
Резюме
Из четырёх требований к транзакционной системе ACID (атомарность, согласованность, изолированность, устойчивость) механизм саг позволяет реализовать три – все, кроме изолированности. Отсутствие изолированности может приводить к аномалиям («грязные чтения», «неповторяющиеся чтения», перезапись изменений между различными бизнес-транзакциями и т.д.). Для преодоления подобных ситуаций требуется использовать дополнительные механизмы, например версионность изменяемых объектов.
Саги позволяют решить следующие задачи:
Область применения и примеры применения
Саги часто используют в системах с большим количеством запросов. Например, популярные почтовые сервисы, социальные сети. Однако подход может найти применение и в проектах меньшего масштаба.
Наша компания имеет опыт разработки системы учёта для крупного предприятия, которая была рассчитана на несколько десятков пользователей и все данные хранились в одной реляционной СУБД. Проблема возникла при реализации автоматического расчёта запланированных работ: в некоторых случаях расчёты были очень большими и требовали вставки миллионов записей в таблицы СУБД, что значительно нагружало СУБД и замедляло работу всей системы.
Было найдено решение — вынести логику расчёта работ в отдельный сервис со своей отдельной СУБД для хранения самих работ и сопутствующих объектов. Согласованность данных обеспечивалась при помощи саги. Если при расчёте происходил сбой, то в основной модуль приложения поступала команда отменить логическую операцию расчёта.
Что такое ACID в базах данных?
В частности, ACID имеет отношение к тому, как БД может восстанавливаться после ошибок, возникающих в процессе выполнения транзакции.
В базах данных, следующих принципу ACID, данные остаются целостными и консистентными, несмотря на любые ошибки.
Определение ACID
Atomicity (атомарность)
Атомарность гарантирует, что каждый запрос в транзакции будет выполнен успешно, либо вообще никакой, в случае ошибки одного. Не получится так, что часть запросов выполнятся успешно, а часть с ошибкой. Если хоть одна часть транзакции выполнится с ошибкой, вся транзакция не выполнится. Другими словами под атомарностью можно понимать «всё или ничего».
Consistency (консистентность, согласованность)
Это свойство даёт гарантию того, что все данные будут целостны. Данные будут корректны в соотвествии со всеми предопределёнными правилами, ограничениями, каскадами и триггерами, применёнными к БД.
Isolation (изолированность)
Гарантирует, что все транзакции будут выполняться изолированно. Ни одна транзакция не зааффектит на другую транзакцию. Другими словами, одна транзакция не сможет прочитать данные второй транзакции, которая ещё не выполнилась.
Durability (стойкость)
Durability означает, что когда транзакция будет применена, она останется в системе, даже если БД упала сразу после выполнения этой транзакции. Любые изменения, внесённые транзакцией, должны оставаться навсегда. Если БД сообщила об успешном выполнении транзакции, то она должна быть действительно применена.
Когда пригодится ACID?
Свойства ACID спроектированы для transaction-ориентированные баз данных.
ACID предлагает принципы, которым должны придерживаться базы данных, чтобы быть уверенным в том, что данные не будут повреждены в результате какой нибудь ошибки.
Транзакция это единая логическая операция, которая может состоять из одного или нескольких шагов. Например, транзакцией может быть перевод денежных средств между банковскими аккаунтами (снятие денег из одного и пополнение другого). Если в середине такой транзакции возникнет ошибка, может возникнуть большая неконсистентность в данных. Деньги будут вычтены с одного счёта, но не зачислены в другой.
Вот тут и должны быть применены принципы ACID.
Следуя принципу ACID, база данных будет целостна тогда и только тогда, когда она будет содержать все результаты успешно выполненных запросов, выполненных в транзакции. Любая ACID совместимая БД гарантирует, что будут применены изменения только успешных транзакций. В случае ошибки в транзакции, данные не будут изменены.
Таким образом, СУБД, совместимые с ACID, дают организациям уверенность в том, что данные в их базе данных будут целостны, даже если произойдёт какой-либо сбой в середине выполнения транзакции.
Типы сбоев
Ошибка транзакции
Эта ошибка может произойти из-за некорректных входных данных или любых других нарушений целостности. Она так же возникает в результате тайм-аута, либо в результате deadlock.
Системный сбой
Системный сбой может быть из-за ошибки в коде СУБД, либо аппаратного сбоя.
Медийные сбои
Эти сбои случаются, когда запись или чтение из хранилища невозможны (например сбой в работе жёсткого диска, либо ошибки в работе операционной системе). Эти ошибки возникают намного реже, чем первые 2 типа.
Следование ACID принципам
Все популярные реляционные базы данных следуют принципам ACID. Все они имеют инструменты, обеспечивающие целостность данных при сбоях программного и аппаратного обеспечения, а также при любых неудачных транзакциях.
Но с NoSQL базами данных ситуация обстоит немного по-другому. Эти базы данных часто предназначены для обеспечения высокой доступности в кластере, а обычно это означает, что в некоторой степени жертвуют консистентностью и/или стойкостью. Однако большинство NoSQL баз данных в некоторой степени могут обеспечить атомарность.
Но всё же, большинстве NoSQL баз данных заложены основы целостности данных, что означает, что данные могут быть не синхронизированы какое-то время, но в конечном итоге они всё таки будут синхронизированы.
Вдобавок, некоторые разработчики, такие как MarkLogic, OrientDB и Neo4j, предлагают ACID-совместимые системы управления базами данных NoSQL.