Синтетические наборы данных
| Определение: |
| Синтетические данные — это программно сгенерированные данные, используемые в бизнес-приложениях (в том числе в машинном обучении). |
Нередко возникают ситуации, когда получение реальных бизнес-процессов сложно или дорого, но при этом известны требования к таким бизнес-процессам, правила создания и законы распределения. Как правило, это происходит, когда речь идёт о чувствительных персональных данных — например, информации о банковских счетах или медицинской информации. В таких случаях необходимые наборы данных можно программно сгенерировать.
Содержание
Виды генерации [ править ]
Существует два основных подхода к генерации синтетических наборов данных.
В случае, когда реальные данные отсутствуют или их сбор невозможен (из-за большой длительности или дороговизны процесса), наборы генерируются полностью случайным образом на основе некой статистической модели, которая учитывает законы распределения реальных данных. Однако, такой подход не всегда оправдывает себя из-за того, что синтетические данные могут не учитывать весь спектр возможных случаев, и полученная с помощью такого набора модель может давать непредсказуемые результаты в крайних случаях.
Также применяется аугментация (англ. augmentation) — генерация наборов на основе имеющихся бизнес-процессов. К имеющимся данным применяются различные способы искажения: например, для изображений могут использоваться различные геометрические преобразования, искажения цвета, кадрирование, поворот, добавление шума и иные. Для числовых данных могут использоваться такие искажения, как добавление объектов с усреднёнными значениями, смешивание с объектами из другого распределения, добавление случайных выбросов.
Преимущества использования синтетических данных:
В то же время, у синтетических данных есть и недостатки:
Применение [ править ]
Сгенерированные объекты можно использовать в задаче обучения с учителем для расширения обучающего множества, сведя её к задачам частичного обучения и самообучения. Довольно распространённым подходом является обучение сначала на большом наборе синтетических данных, а затем дообучение на небольшом наборе имеющихся реальных данных. Иногда при обучении реальные данные не используются вовсе. При этом в тестовых множествах использовать синтетические наборы данных нельзя: в них должны быть только реальные объекты.
Синтетические данные активно используются при обучении алгоритмов управления автономным транспортом. Эти алгоритмы решают две задачи: сначала выявляют окружающие объекты — машины, дорожные знаки, пешеходов, а затем принимают решение о направлении и скорости дальнейшего движения. При реализации таких алгоритмов наиболее важно поведение транспортного средства в критических ситуациях, таких как помехи на дороге или некорректные показания сенсоров — от этого могут зависеть жизни людей. В реальных данных же, наоборот, в основном присутствуют штатные ситуации.
Одно из самых наглядных применений аугментации данных — алгоритмы восстановления изображений. Для работы таких алгоритмов исходный набор изображений расширяется их копиями, к которым применяются некие преобразования из фиксированного набора. На основе полученных изображений генерируется набор, в котором входными данными считаются полученные изображения, а целевыми — исходные. В самом деле, получить реальные данные для такой задачи — фотографию и её же искажённую копию — довольно затруднительно, а применение таких преобразований довольно легко автоматизируется. Таким образом, если исходные изображения достаточно хорошо описывали источник данных, то полученный набор данных можно применять для обучения алгоритма восстановления изображений, устраняющего применённые преобразования.
Также с помощью синтетических наборов данных можно упростить обучение алгоритмов компьютерного зрения, решающих задачи семантической сегментации, поиска и локализации объектов. В данном случае подходят наборы, в которых искомые объекты определённым образом наносятся на фоновое изображение. В частности, таким объектом может быть текст — тогда с помощью полученного набора может быть решена задача распознавания текста на изображении.
Синтетические данные используются и для создания алгоритмов реидентификации [на 25.01.21 не создан] — определения, действительно ли на двух изображениях один и тот же человек. Эти алгоритмы могут использоваться для нахождения людей на записях с камер, на пограничных пунктах и так далее. В этом случае реальные данные собрать довольно сложно, потому что требуется найти много фотографий одних и тех же людей в разных позах, с разных ракурсов и в разной одежде.
При генерации синтетических наборов данных необходимо учитывать специфику каждого конкретного случая, общего алгоритма, подходящего для всех случаев не существует. Как правило, общие алгоритмы наподобие добавления средних значений оказываются нерепрезентативными.
Примеры [ править ]

TextSharpener [ править ]

OmniSCV [ править ]
Нередко различные устройства оснащаются широкоугольными и панорамными камерами с углом обзора до 360°. Изображения, получаемые с таких камер, обладают довольно сильными искажениями (см. рисунок 2). Генератор изображений комнат OmniSCV [6] используется при разработке роботов для обучения алгоритмов компьютерного зрения для устранения искажений широкоугольных объективов и неидеальных условий освещённости.
Генератор умеет симулировать различные варианты бизнес-процессов — равноугольные и цилиндрические панорамы, «рыбьи глаза» и катадиоптрические системы, а также сопровождать сгенерированные изображения комнат вспомогательной информацией об окружающем пространстве и параметрах используемой камеры (см. рисунок 3).
Обычно данные, полученные с помощью компьютерного моделирования, можно рассматривать как синтетические данные. Это включает в себя большинство приложений физического моделирования, таких как музыкальные синтезаторы или имитаторы полета. Выходные данные таких систем приблизительно соответствуют реальным, но генерируются полностью алгоритмически.
СОДЕРЖАНИЕ
Полезность
История
Приложения
Синтетические данные также используются для защиты конфиденциальности и конфиденциальности набора данных. Настоящие данные содержат личную / частную / конфиденциальную информацию, которую программист, создатель программного обеспечения или исследовательский проект, возможно, не захотят разглашать. Синтетические данные не содержат личной информации и не могут быть прослежены до какого-либо лица; Таким образом, использование синтетических данных снижает конфиденциальность и конфиденциальность.
Расчеты
Исследователи тестируют структуру на синтетических данных, которые являются «единственным источником достоверной информации, на основе которого они могут объективно оценить производительность своих алгоритмов ».
Синтетические данные могут быть сгенерированы с помощью случайных линий, имеющих разную ориентацию и начальные позиции. Наборы данных могут быть довольно сложными. Более сложный набор данных можно создать с помощью сборки синтезатора. Чтобы создать сборку синтезатора, сначала используйте исходные данные, чтобы создать модель или уравнение, которое наилучшим образом соответствует данным. Эта модель или уравнение будет называться сборкой синтезатора. Эту сборку можно использовать для генерации дополнительных данных.
Поскольку значения атрибутов одного объекта могут зависеть от значений атрибутов связанных объектов, процесс создания атрибутов присваивает значения коллективно.
Синтетические данные в машинном обучении
В настоящее время синтетические данные используются на практике в эмулируемых средах для обучения беспилотных автомобилей (в частности, с использованием реалистичных компьютерных игр для синтетических сред), отслеживания точек и розничных приложений с такими методами, как рандомизация предметной области для обучения передачи.
Смотрите также
Рекомендации
дальнейшее чтение
Эта статья основана на материалах, взятых из Free On-line Dictionary of Computing до 1 ноября 2008 г. и включенных в соответствии с условиями «перелицензирования» GFDL версии 1.3 или новее.
Генерация синтетических данных с помощью Numpy и Scikit-Learn

В этом руководстве мы обсудим детали создания различных синтетических наборов данных с использованием библиотек Numpy и Scikit-learn. Мы увидим, как можно сгенерировать разные образцы из разных распределений с известными параметрами.
Мы также обсудим создание наборов данных для различных целей, таких как регрессия, классификация и кластеризация. В конце мы увидим, как мы можем создать набор данных, имитирующий распределение существующего набора данных.
Потребность в синтетических данных
В науке о данных синтетические данные играют очень важную роль. Это позволяет нам протестировать новый алгоритм в контролируемых условиях. Другими словами, мы можем генерировать данные, которые проверяют очень конкретное свойство или поведение нашего алгоритма.
Например, мы можем протестировать его производительность на сбалансированных и несбалансированных наборах данных, или мы можем оценить его производительность при разных уровнях шума. Делая это, мы можем установить базовый уровень производительности нашего алгоритма в различных сценариях.
Настройка
Прежде чем писать код для генерации синтетических данных, давайте импортируем необходимые библиотеки:
Затем вначале у нас будет несколько полезных переменных:
Создание одномерных выборок из известных распределений
Теперь мы поговорим о создании точек выборки из известных распределений в 1D.
Теперь мы упакуем их в подзаголовки Figure для визуализации и сгенерируем синтетические данные на основе этих распределений, параметров и назначим им соответствующие цвета.
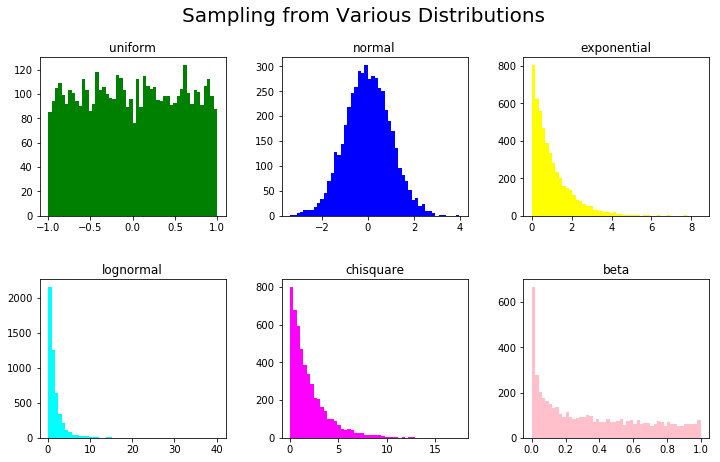
Синтетические данные для регрессии
В пакете sklearn.datasets есть функции для создания синтетических наборов данных для регрессии. Здесь мы обсуждаем линейные и нелинейные данные для регрессии.
Функция make_regression() возвращает набор точек ввода данных (регрессоров) вместе с их выходом (целью). Эту функцию можно настроить с помощью следующих параметров:
Переменная ответа представляет собой линейную комбинацию сгенерированного входного набора.
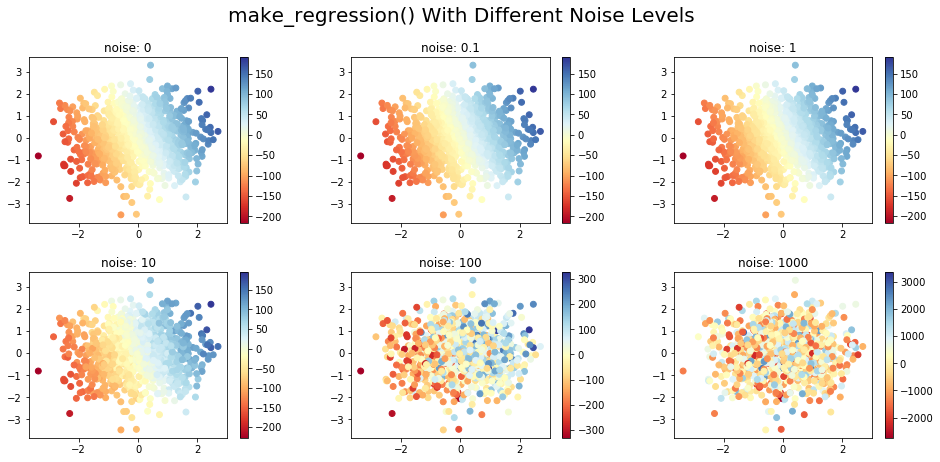
В приведенном ниже коде синтетические данные были сгенерированы для разных уровней шума и состоят из двух входных функций и одной целевой переменной. Изменение цвета входных точек показывает изменение целевого значения, соответствующего точке данных. Данные создаются в 2D для лучшей визуализации, но данные большого размера могут быть созданы с помощью параметра n_features :
Здесь мы создали пул из 1000 образцов с двумя функциями (классами). В зависимости от уровня шума ( 0..1000 ) мы можем увидеть, насколько сгенерированные данные существенно различаются на диаграмме рассеяния:
Семейство функций make_friedman
Эти функции генерируют целевую переменную, используя нелинейную комбинацию входных переменных, как подробно описано ниже:
make_friedman1() : Аргумент n_features этой функции должен быть не менее 5, следовательно, минимальное количество входных измерений 5. Здесь цель задается:
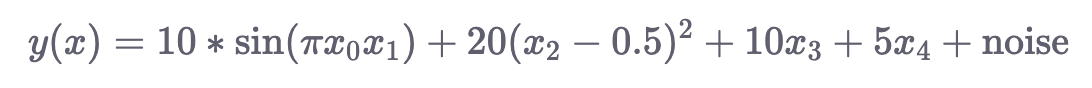
make_friedman2() : Сгенерированные данные имеют 4 входных измерения. Переменная response задается следующим образом:
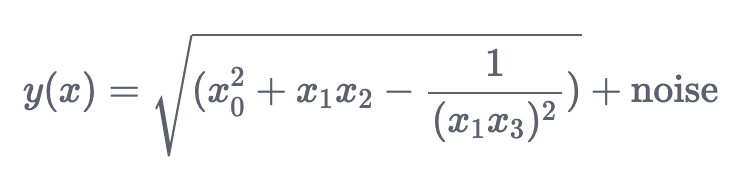
make_friedman3() : Сгенерированные данные в этом случае также имеют 4 измерения. Выходная переменная определяется следующим образом:
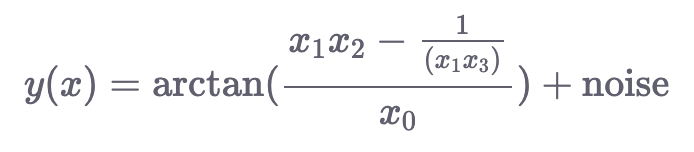
Приведенный ниже код генерирует наборы данных с использованием этих функций и отображает первые три функции в 3D, причем цвета меняются в зависимости от целевой переменной:
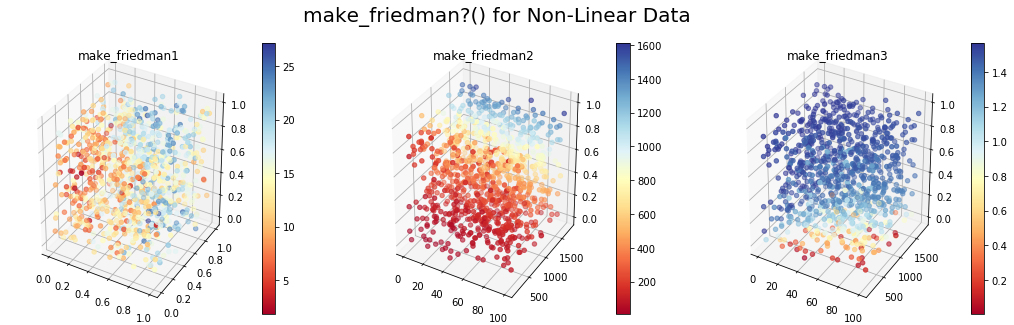
Синтетические данные для классификации
make_classification() для задач классификации n-класса
Для задач классификации n-класса функция make_classification() имеет несколько вариантов:
Создадим набор данных классификации для двумерных входных данных. У нас будут разные значения class_sep для задачи двоичной классификации. Точки одного цвета относятся к одному классу. Стоит отметить, что эта функция также может генерировать несбалансированные классы:
make_multilabel_classification() для задач классификации Multi-Label
Давайте рассмотрим 4-х классную задачу с несколькими метками, при которой целевой вектор меток преобразуется в одно значение для визуализации. Точки раскрашены в соответствии с десятичным представлением двоичного вектора меток. Код поможет вам увидеть, как использование другого значения для n_label меняет классификацию сгенерированной точки данных:
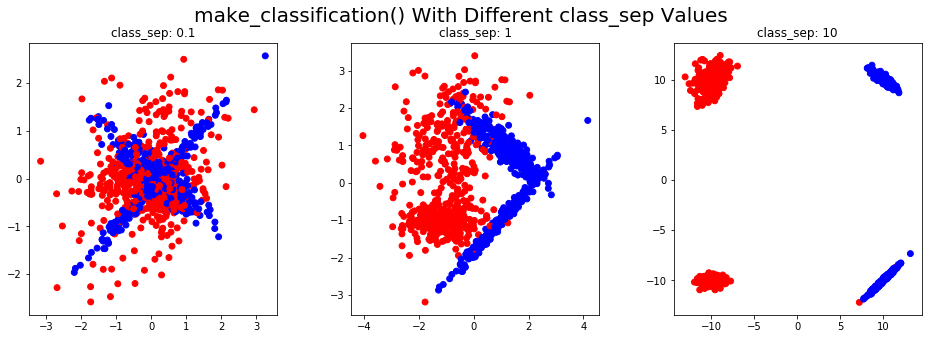
Синтетические данные для кластеризации
make_blobs()
Функция make_blobs() генерирует данные из изотропных гауссовских распределений. В качестве аргумента можно указать количество функций, количество центров и стандартное отклонение каждого кластера.
Здесь мы проиллюстрируем эту функцию в 2D и покажем, как точки данных меняются с разными значениями параметра cluster_std :
make_circles()
Функция make_circles() генерирует две концентрических окружности с тем же центром, один внутри другого.
Используя параметр шума, к сгенерированным данным можно добавить искажения. Этот тип данных полезен для оценки алгоритмов кластеризации на основе сходства. В приведенном ниже коде показаны синтетические данные, сгенерированные при разных уровнях шума:
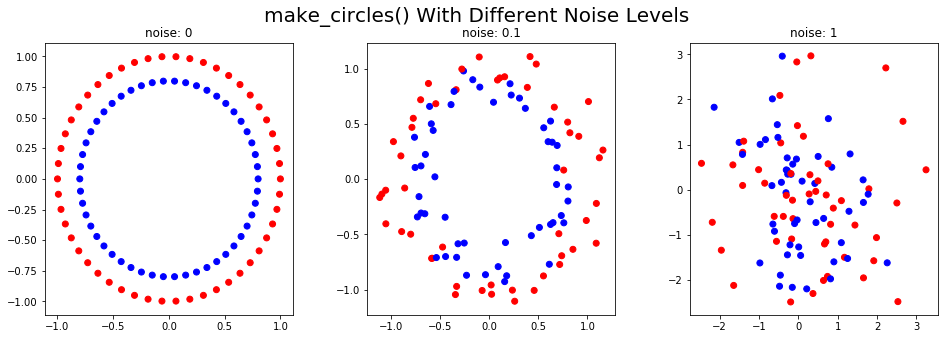
Генерация выборок, полученных из входного набора данных
Есть много способов создания дополнительных выборок данных из существующего набора данных. Здесь мы проиллюстрируем очень простой метод, который сначала оценивает плотность данных ядра с использованием гауссова ядра, а затем генерирует дополнительные выборки из этого распределения.
Вот что мы будем делать:

В этом примере было создано 8 новых образцов. Обратите внимание, что синтетические лица, показанные здесь, не обязательно соответствуют лицу человека, показанного над ним.
Выводы
В этой статье мы познакомились с несколькими методами генерации синтетических наборов данных для различных задач. Синтетические наборы данных помогают нам оценивать наши алгоритмы в контролируемых условиях и устанавливать базовый уровень для показателей производительности.
Python имеет широкий спектр функций, которые можно использовать для создания искусственных данных. Важно понимать, какие функции и API можно использовать для ваших конкретных требований.
Данные — новая нефть. Как на них заработать?

Алексей Шабанов, исследователь Neuromation, рассказывает, какие данные представляют ценность для компаний, и раскрывает пять способов заработка на них.
Сегодня многие технологические компании активно используют методы машинного обучения, чтобы встраивать в свои продукты и бизнес-процессы умные алгоритмы. Так, с каждым днем рекламная выдача становится прицельнее, автоматический перевод точнее, а голосовые ассистенты понятливее. Необходимый ингредиент для создания таких систем — данные, много данных.
Тест: узнай, сможешь ли ты грамотно выйти на рынок в другой стране
Следовательно, первый ответ на вопрос из заголовка будет таким: нужно найти релевантные к деятельности компании данные и использовать их, чтобы сделать выпускаемые продукты «умнее». Но подобный ответ лежит на поверхности и едва ли может считаться полным. Мы поможем открыть читателю менее очевидные способы заработка на данных, но для этого придется совершить небольшой экскурс в предметную область.
Какие данные представляют ценность?
Задачи машинного обучения подразумевают, что необходимо научить некоторый алгоритм извлекать закономерности из обучающего набора «вопросов» и «ответов», чтобы обобщить полученный опыт для ответов на новые вопросы. В качестве алгоритма могут использоваться классические статистические модели, а могут и искусственные нейронные сети — для нашего повествования это не играет роли. Например, мы желаем научить какую-то модель определять тональности рецензий на фильмы, тогда вопрос — это текст рецензии, а ответ — один из двух вариантов: положительной была рецензия или отрицательной. Еще несколько примеров:
Процесс получения ответов на заданные вопросы (в приведенном узком смысле) называется разметкой или аннотированием данных, а совокупность полученных данных называется датасетом. Итак, с точки зрения машинного обучения ценность представляют не любые данные, а размеченные. Стоимость аннотирования зависит от многих факторов: требуемой компетенции разметчиков, сложности технической организации процесса, конфиденциальности данных и других.
Так, отсортировать рецензии к фильмам может любой человек, используя примитивный текстовый редактор. Чтобы выделить контуры автомобилей на изображении перекрестка, особых знаний тоже не нужно, но потребуется специализированное ПО.
Наконец, чтобы разметить серию рентген-снимков, потребуется и ПО, и специалисты с медицинским образованием — такие данные представляют особую ценность.
Растущий спрос на все большие объемы аннотированных данных привел к созданию таких площадок как Amazon Mechanical Turk и его отечественного аналога Яндекс.Толоки. Эти сервисы позволяют свести заказчиков датасетов и специалистов по разметке данных. Часто последними являются малообеспеченные граждане азиатских стран, таких как Индия, Пакистан и Бангладеш. В большинстве случаев они за целый день работы получают всего несколько долларов, в то время как владельцы площадок получают большую часть стоимости заказа. Обладатели уже размеченных данных тоже могут извлечь выгоду: либо косвенно, выкладывая их в открытый доступ для продвижения своего бренда, либо напрямую, перепродавая датасеты другим заинтересованным лицам.
Кроме стоимости, у ручного аннотирования есть еще один существенный недостаток: для некоторых задач невозможно предложить приемлемый способ ручной разметки. Скажем, в случае с перекрестком мы можем захотеть дополнительно определять скорости автомобилей на каждом кадре: точно проставить такие метки вручную крайне проблематично. Избежать названных проблем помогает использование синтетических данных.
Что такое синтетические данные?
Под словосочетанием «синтетические данные» обычно подразумеваются объекты реального мира, смоделированные с помощью компьютера. Главное преимущество такого подхода в том, что разметка к ним прилагается автоматически. Вновь обратимся к примеру с перекрестком: если смоделировать его средствами для создания компьютерных игр, мы сразу получим полную информацию о любом объекте в кадре: его скорость, цвет, массу, положение и что угодно еще! Другой пример: использование синтезатора для озвучивания текста позволяет с точностью до миллисекунд сопоставлять буквы и их фонемы, что недостижимо при использовании ручного труда.
Кроме того, синтетические датасеты отлично масштабируются: например, получив в распоряжение синтезатор речи, можно озвучить миллионы страниц текста!
Вдумчивый читатель мог догадаться, что самое сложное при работе с синтетическими данными — сделать их достаточно реалистичными. Действительно, взаимосвязи между объектами в синтетическом датасете должны иметь место в реальном мире. К счастью, сейчас активно развиваются архитектуры нейронных сетей, предназначенные для генерации контента (Generative Adversarial Networks, GAN), которые позволяют адаптировать синтетические данные под задачи реального мира. Кроме того, GAN’ы могут использоваться и для генерации контента «с нуля», получаемые таким способом сущности тоже можно назвать синтетическими. Однако, практика показывает, что качество такой генерации уступает адаптированной синтетике.
Кто работает с синтетическими данными?
Приведем пример компаний, использующих синтетические данные для создания своих продуктов:

Синтетические глаза сверху, снизу их более реалистичные версии, полученные с помощью GAN’ов.
Сгенерированные формы для зубных коронок.

Синтетическая полка с товарами.
Итак, как же заработать на данных?
Напоследок, вооружившись знаниями о предметной области, вновь ответим на вопрос, поставленный в заголовке. Условно способы заработка можно разбить на пять групп:
Обычно данные, полученные с помощью компьютерного моделирования, можно рассматривать как синтетические данные. Это включает в себя большинство приложений физического моделирования, таких как музыкальные синтезаторы или имитаторы полета. Выходные данные таких систем приблизительно соответствуют реальным, но генерируются полностью алгоритмически.
СОДЕРЖАНИЕ
Полезность
История
Приложения
Синтетические данные также используются для защиты конфиденциальности и конфиденциальности набора данных. Настоящие данные содержат личную / частную / конфиденциальную информацию, которую программист, создатель программного обеспечения или исследовательский проект, возможно, не захотят разглашать. Синтетические данные не содержат личной информации и не могут быть прослежены до какого-либо лица; Таким образом, использование синтетических данных снижает конфиденциальность и конфиденциальность.
Расчеты
Исследователи тестируют структуру на синтетических данных, которые являются «единственным источником достоверной информации, на основе которого они могут объективно оценить производительность своих алгоритмов ».
Синтетические данные могут быть сгенерированы с помощью случайных линий, имеющих разную ориентацию и начальные позиции. Наборы данных могут быть довольно сложными. Более сложный набор данных можно создать с помощью сборки синтезатора. Чтобы создать сборку синтезатора, сначала используйте исходные данные, чтобы создать модель или уравнение, которое наилучшим образом соответствует данным. Эта модель или уравнение будет называться сборкой синтезатора. Эту сборку можно использовать для генерации дополнительных данных.
Поскольку значения атрибутов одного объекта могут зависеть от значений атрибутов связанных объектов, процесс создания атрибутов присваивает значения коллективно.
Синтетические данные в машинном обучении
В настоящее время синтетические данные используются на практике в эмулируемых средах для обучения беспилотных автомобилей (в частности, с использованием реалистичных компьютерных игр для синтетических сред), отслеживания точек и розничных приложений с такими методами, как рандомизация предметной области для обучения передачи.
Смотрите также
Рекомендации
дальнейшее чтение
Эта статья основана на материалах, взятых из Free On-line Dictionary of Computing до 1 ноября 2008 г. и включенных в соответствии с условиями «перелицензирования» GFDL версии 1.3 или новее.