FoxTools v.2.0
Привет, Гость! Ваш IP: 188.124.37.220
Таблица символов Юникода
DEC: 
HEX:
Html:
Что такое Юникод?
В отличие от ASCII, один символ кодируется двумя байтами, что позволяет использовать 65 536 символов, против 256.
Символы Юникода разделены на секции. Первые 128 символов повторяют таблицу ASCII.
Как пользоваться таблицей?
Символы представлены по 16 штук на строке. Сверху вы можете видеть шестнадцатеричное число от 0 до 16. Слева аналогичные числа в шестнадцатеричном виде от 0 до FFF.
Соединив число слева с числом сверху, можно узнать код символа. Например: английская буква F расположена на строке 004, в столбике 6: 004 + 6 = код символа 0046.
Впрочем, вы можете просто навести курсор на конкретный символ в таблице, чтобы узнать код символа. Либо нажать на символ, чтобы скопировать его, или его код в одном из форматов.
В поисковое поле можно ввести ключевые слова поиска, например: стрелки, солнце, сердце. Либо можно указать код символа в любом формате, например: 1123, 04BC, چ. Или сам символ, если требуется узнать код символа.
Поиск по ключевым словам в данный момент находится на стадии разработки, поэтому может не выдавать результатов. Но многие популярные символы уже можно найти.
К сожалению, в данный момент таблица не работает на мобильных устройствах.
В Application Programming Interface этот сервис не реализован. В популярных языках программирования можно легко работать с символами Юникода. Если у вас возникнут какие-либо вопросы, обращайтесь на форум для программистов.
Сайт построен на HTML5
Для корректной работы данного сайта требуется HTML5.
Пожалуйста, воспользуйтесь браузером, который поддерживает HTML5. Многие современные браузеры поддерживают HTML5. Например:
Компью А рт
Символы, знаки и байты: введение в Юникод
Юникод (англ. Unicode) — стандарт кодирования, позволяющий представить знаки практически всех письменных языков. Он был предложен в 1991 году некоммерческой организацией Unicode Consortium, Unicode, Inc. Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становятся ненужными кодовые страницы.
Стандарт состоит из двух основных разделов: универсальный набор символов (universal character set, UCS) и семейство кодировок (Unicode transformation format, UTF). Универсальный набор символов задает однозначное соответствие символов кодам — элементам кодового пространства, представляющим неотрицательные целые числа. Семейство кодировок определяет машинное представление последовательности кодов UCS.
Коды в стандарте Юникод разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунк-туации и технические символы. Часть кодов зарезервирована для использования в будущем. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F (рис. 4 и 5), от U+2DE0 до U+2DFF (рис. 6), от U+A640 до U+A69F (рис. 7).

Рис. 4. Базовый русский, расширенная кириллица: украинский, македонский, сербский, старославянский, башкирский, татарский и др.
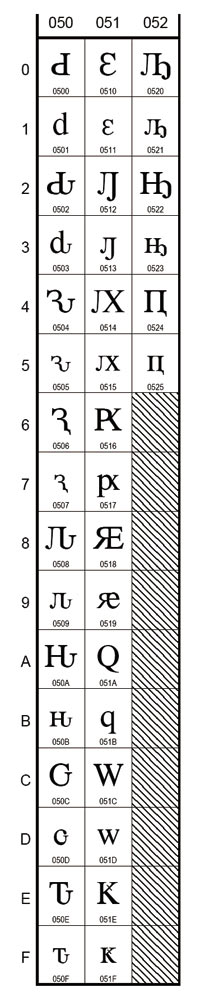
Рис. 5. Расширенная кириллица: современный абхазский, чувашский, алеутский, мордовский, коми, чукотский, ханты и др.

Рис. 6. Старославянские модифицирующие знаки

Рис. 7. Старославянский и староабхазский
Первая версия Unicode представляла собой кодировку с фиксированным размером символа в 16 бит, то есть общее число кодов было 216 (65 536). Отсюда происходит практика обозначения символов четырьмя шестнадцатеричными цифрами (например, U+0410). При этом в Юникоде планировалось кодировать не все существующие символы, а только те, которые необходимы в повседневном обиходе. Редко применяемые символы должны были размещаться в «области символов для частного использования» (Private Use Area), которая первоначально занимала коды от U+D800 до U+F8FF. Чтобы применять Юникод и в качестве промежуточного звена при преобразовании разных кодировок друг в друга, в него включили все символы, представленные во всех наиболее известных кодировках.
В дальнейшем, однако, было принято решение кодировать все символы и в связи с этим значительно расширить кодовую область. Одновременно с этим коды символов стали рассматриваться не как 16-битные значения, а как абстрактные числа, которые в компьютере могут представляться множеством разных способов.
Поскольку в ряде компьютерных систем (например, Windows NT) фиксированные 16-битные символы уже использовались в качестве кодировки по умолчанию, было решено все наиболее важные знаки кодировать только в пределах первых 65 536 позиций (так называемая basic multilingual plane, BMP). Остальное пространство применяется для «дополнительных символов» (англ. supplementary characters): систем письма вымерших языков или очень редко используемых китайских иероглифов, математических и музыкальных символов.
Для совместимости со старыми 16-битными системами была изобретена система UTF-16, где первые 65 536 позиций, за исключением позиций из интервала от U+D800 до U+DFFF, отображаются непосредственно как 16-битные числа, а остальные представляются в виде «суррогатных пар» (первый элемент пары из области U+D800…U+DBFF, второй элемент пары из области U+DC00…U+DFFF). Для суррогатных пар была использована часть кодового пространства (2048 позиций), ранее отведенного для Private Use Area.
Поскольку в UTF-16 можно отобразить только 2 20 +2 16 –2048 (1 112 064) символов, то это число и было выбрано в качестве окончательной величины кодового пространства Юникода.
Хотя кодовая область Юникода была расширена за пределы 2 16 уже в версии 2.0, первые символы в «верхней» области были размещены только в версии 3.1.
По мере изменения и пополнения таблицы символов системы Юникода и выхода новых версий этой системы (эта работа ведется постоянно, поскольку изначально система Юникод включала только Plane 0 — двухбайтные коды) выходят и новые документы ISO. Система Юникод существует в общей сложности в следующих версиях:
Хотя формы записи UTF-8 и UTF-32 позволяют кодировать до 231 (2 147 483 648) кодовых позиций, было принято решение использовать лишь 1 112 064 для совместимости с UTF-16. Впрочем, даже и этого более чем достаточно — сегодня (в версии 5.1) применяется немногим более 100 тыс. кодовых позиций.
Кодовое пространство разбито на 17 плоскостей (подмножеств) по 2 16 (65 536) символов. Нулевая плоскость называется базовой, в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется в основном для исторических письменностей, вторая — для редко применяемых иероглифов, третья зарезервирована для архаичных китайских иероглифов ККЯ. Плоскости 15 и 16 выделены для частного употребления (табл. 22).
Таблица 22
Базовая многоязыковая плоскость
Basic Multilingual Plane, BMP
Дополнительная многоязыковая плоскость
Supplementary Multilingual Plane, SMP
Дополнительная иероглифическая плоскость
Supplementary Ideographic Plane, SIP
Третичная иероглифическая плоскость
Tertiary Ideographic Plane, TIP
Дополнительная
плоскость особого
назначения
Supplementary Special-purpose Plane, SSP
Применяется как дополнительная область A для частного использования
Supplementary Private Use Area-A, SPUA-A
Применяется как дополнительная область B для частного использования
Supplementary Private Use Area-B, SPUA-B
Для обозначения символов Unicode используется запись вида «U+xxxx» (для кодов 0…FFFF), или «U+xxxxx» (для кодов 10000…FFFFF), или «U+xxxxxx» (для кодов 100000…10FFFF), где xxx — шестнадцатеричные цифры. Например, символ «я» (U+044F) имеет код 044F16 = 110310.
Универсальная система кодирования (Юникод) представляет собой набор графических символов и способ их кодирования для компьютерной обработки текстовых данных.
Графические символы — это символы, имеющие видимое изображение. Графическим символам противопоставляются управляющие символы и символы форматирования.
Графические символы включают следующие группы:
Юникод — это система для линейного представления текста. Символы, имеющие дополнительные над или подстрочные элементы, могут быть представлены в виде построенной по определенным правилам последовательности кодов (составной вариант, composite character) или в виде единого символа (монолитный вариант, precomposed character).
Графические символы в Юникоде подразделяются на протяженные и непротяженные (бесширинные). Непротяженные символы при отображении не занимают места в строке. К ним относятся, в частности, знаки ударения и прочие диакритические знаки. Как протяженные, так и непротяженные символы имеют собственные коды. Протяженные символы иначе называются базовыми (англ. base characters), а непротяженные — модифицирующими (англ. combining characters), причем последние не могут встречаться самостоятельно. Например, символ «á» может быть представлен как последовательность базового символа «a» (U+0061) и модифицирующего символа «’» (U+0301) или как монолитный символ «á» (U+00C1).
Особый тип модифицирующих символов — селекторы варианта начертания (англ. variation selectors). Они действуют только на те символы, для которых такие варианты определены. В версии 5.0 варианты начертания определены для ряда математических символов, для символов традиционного монгольского алфавита и для символов монгольского квадратного письма.
Поскольку одни и те же символы можно представить различными кодами, что иногда затрудняет обработку, существуют процессы нормализации, предназначенные для приведения текста к определенному стандартному виду.
В стандарте Юникода определены четыре формы нормализации текста:
— символ S является начальным, если он имеет нулевой класс модификации в базе символов Юникода,
— в любой последовательности символов, стартующей с начального символа S, символ C блокируется от S, если и только если между S и C есть какойлибо символ B, который или является начальным, или имеет одинаковый либо больший класс модификации, чем C. Это правило распространяется только на строки, прошедшие каноническую декомпозицию,
— первичным композитом считается символ, у которого есть каноническая декомпозиция в базе символов Юникода (или каноническая декомпозиция для хангыля и он не входит в список исключений);
— если очередной символ C не блокируется последним встреченным начальным базовым символом L и может быть успешно первично совмещен с ним, то L заменяется на композит L-C, а C удаляется;
Под терминами «композиция» и «декомпозиция» понимают соответственно соединение или разложение символов на составные части.
Стандарт Юникод поддерживает письменности языков с направлением написания как слева направо (left-to-right, LTR), так и справа налево (right-to-left, RTL) — например арабское и еврейское письмо. В обоих случаях символы хранятся в «естественном» порядке; их отображение с учетом нужного направления письма обеспечивается приложением.
Кроме того, Юникод поддерживает комбинированные тексты, сочетающие фрагменты с разным направлением письма. Данная возможность называется двунаправленностью (bidirectional text, BiDi). Некоторые упрощенные обработчики текста (например, в сотовых телефонах) могут поддерживать Юникод, но не иметь поддержки двунаправленности. Все символы Юникода поделены на несколько категорий: пишущиеся слева направо, пишущиеся справа налево и пишущиеся в любом направлении. Символы последней категории (в основном это знаки пунк-туации) при отображении принимают направление окружающего их текста.
Юникод включает практически все современные письменности, в том числе арабскую, армянскую, бенгальскую, бирманскую, глаголицу, греческую, грузинскую, деванагари, еврейскую, кириллицу, китайскую (китайские иероглифы активно используются в японском языке, а также, довольно редко, в корейском), коптскую, кхмерскую, латинскую, тамильскую, корейскую (хангыль), чероки, эфиопскую, японскую (которая, кроме китайских иероглифов, включает еще и слоговую азбуку) и др.
С академическими целями добавлены многие исторические письменности, в том числе руны, древнегреческая, египетские иероглифы, клинопись, письменность майя, этрусский алфавит.
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм.
Однако в Юникод принципиально не включаются логотипы компаний и продуктов, хотя они и встречаются в шрифтах (например, логотип Apple в кодировке MacRoman (0xF0) или логотип Windows в шрифте Wingdings (0xFF)). В юникодовских шрифтах логотипы должны размещаться только в Private Use Area.
Консорциум Юникода работает в тесной связи с рабочей группой ISO/IEC/JTC1/SC2/WG2, которая занимается разработкой международного стандарта 10646 (ISO/IEC 10646). Между стандартом Юникода и ISO/IEC 10646 установлена синхронизация, хотя каждый стандарт использует свою терминологию и систему документации.
Сотрудничество консорциума Юникода с Международной организацией по стандартизации (англ. International Organization for Standardization, ISO) началось в 1991 году. В 1993-м ISO выпустила стандарт DIS 10646.1. Для синхронизации с ним консорциум утвердил стандарт Юникода версии 1.1, в который были внесены дополнительные символы из DIS 10646.1. В результате значения закодированных символов в Unicode 1.1 и DIS 10646.1 полностью совпали.
В дальнейшем сотрудничество двух организаций продолжилось. В 2000 году стандарт Unicode 3.0 был синхронизирован с ISO/IEC 10646-1:2000. Предстоящая третья версия, ISO/IEC 10646, будет синхронизирована с Unicode 4.0. Возможно, эти спецификации даже будут опубликованы как единый стандарт.
Аналогично форматам UTF-16 и UTF-32 в стандарте Юникода, стандарт ISO/IEC 10646 также имеет две основные формы кодирования символов: UCS-2 (2 байта на символ, аналогично UTF-16) и UCS-4 (4 байта на символ, аналогично UTF-32). UCS — значит универсальный многооктетный (многобайтовый) кодированный набор символов (universal multiple-octet coded character set). UCS-2 можно считать подмножеством UTF-16 (UTF-16 без суррогатных пар), а UCS-4 является синонимом для UTF-32.
Юникод имеет несколько форм представления (Unicode transformation format, UTF): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовмес-тимости с ASCII она не получила распространения и не включена в стандарт. 1 апреля 2005 года были предложены две шуточные формы представления: UTF-9 и UTF-18 (RFC 4042).
В Microsoft Windows NT и основанных на ней системах Windows 2000 и Windows XP в основном используется форма UTF-16LE. В UNIX-подобных операционных системах GNU/Linux, BSD и Mac OS X принята форма UTF-8 для файлов и UTF-32 или UTF-8 для обработки символов в оперативной памяти.
Формат UTF-8 был изобретен 2 сентября 1992 года Кеном Томпсоном и Робом Пайком и реализован в Plan 9. Сейчас стандарт UTF-8 официально закреплен в документах RFC 3629 и ISO/IEC 10646 Annex D.
UTF-8 (Unicode Transformation Format — формат преобразования Юникода) — в настоящее время распространенная кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и вебпространстве.
Текст, состоящий только из символов Юникода с номером меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. И наоборот, в тексте UTF-8 любой байт со значением меньше 128 изображает символ ASCII с тем же кодом. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт (реально только до 4 байт, поскольку использование кодов больше 221 не планируется), в которых первый байт всегда имеет вид 11xxxxxx, а остальные — 10xxxxxx.
Проще говоря, в формате UTF-8 символы латинского алфавита, знаки препинания и управляющие символы ASCII записываются кодами US-ASCII, а все остальные символы кодируются при помощи нескольких октетов со старшим битом 1. Это приводит к двум эффектам.
Даже если программа не распознает Юникод, то латинские буквы, арабские цифры и знаки препинания будут отображаться правильно.
В случае если латинские буквы и простейшие знаки препинания (включая пробел) занимают существенный объем текста, UTF-8 дает выигрыш по объему по сравнению с UTF-16.
На первый взгляд может показаться, что UTF-16 удобнее, так как в ней большинство символов кодируется ровно двумя байтами. Однако это сводится на нет необходимостью поддержки суррогатных пар, о которых часто забывают при использовании UTF-16, реализуя лишь поддержку символов UCS-2.
Символы UTF-8 получаются из Unicode следующим образом (табл. 23).
Юникод
Юнико́д [1] или Унико́д [2] (англ. Unicode ) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. [3]
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc. ). [4] [5] Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным переключение кодовых страниц. [6]
Стандарт состоит из двух основных разделов: универсальный набор символов (англ. UCS, universal character set ) и семейство кодировок (англ. UTF, Unicode transformation format ). Универсальный набор символов задаёт однозначное соответствие символов кодам — элементам кодового пространства, представляющим неотрицательные целые числа. Семейство кодировок определяет машинное представление последовательности кодов UCS.
Коды в стандарте Юникод разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем. [7] Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F (см. Кириллица в Юникоде). [8]
Содержание
Предпосылки создания и развитие Юникода
К концу 1980-х годов стандартом стали 8-битные символы, при этом существовало множество разных 8-битных кодировок, и постоянно появлялись всё новые. Это объяснялось как постоянным расширением круга поддерживаемых языков, так и стремлением создать кодировку, частично совместимую с какой-нибудь другой (характерный пример — появление альтернативной кодировки для русского языка, обусловленное эксплуатацией западных программ, созданных для кодировки CP437). В результате появилось несколько проблем:
Было признано необходимым создание единой «широкой» кодировки. Кодировки с переменной длиной символа, широко использующиеся в Восточной Азии, были признаны слишком сложными в использовании, поэтому было решено использовать символы фиксированной ширины. Использование 32-битных символов казалось слишком расточительным, поэтому было решено использовать 16-битные.
В дальнейшем, однако, было принято решение кодировать все символы и в связи с этим значительно расширить кодовую область. Одновременно с этим, коды символов стали рассматриваться не как 16-битные значения, а как абстрактные числа, которые в компьютере могут представляться множеством разных способов (см. Способы представления).
Поскольку в ряде компьютерных систем (например, Windows NT [10] ) фиксированные 16-битные символы уже использовались в качестве кодировки по умолчанию, было решено все наиболее важные знаки кодировать только в пределах первых 65 536 позиций (так называемая англ. basic multilingual plane, BMP ). Остальное пространство используется для «дополнительных символов» (англ. supplementary characters ): систем письма вымерших языков или очень редко используемых китайских иероглифов, математических и музыкальных символов.
Для совместимости со старыми 16-битными системами была изобретена система UTF-16, где первые 65 536 позиций, за исключением позиций из интервала U+D800…U+DFFF, отображаются непосредственно как 16-битные числа, а остальные представляются в виде «суррогатных пар» (первый элемент пары из области U+D800…U+DBFF, второй элемент пары из области U+DC00…U+DFFF). Для суррогатных пар была использована часть кодового пространства (2048 позиций), ранее отведённого для «символов для частного использования».
Поскольку в UTF-16 можно отобразить только 2 20 +2 16 −2048 (1 112 064) символов, то это число и было выбрано в качестве окончательной величины кодового пространства Юникода.
Хотя кодовая область Юникода была расширена за пределы 2 16 уже в версии 2.0, первые символы в «верхней» области были размещены только в версии 3.1.
Роль этой кодировки в веб-секторе постоянно растёт, на начало 2010 доля веб-сайтов, использующих Юникод, составила около 50 %. [11]
Версии Юникода
По мере изменения и пополнения таблицы символов системы Юникода и выхода новых версий этой системы, — а эта работа ведётся постоянно, поскольку изначально система Юникод включала только Plane 0 — двухбайтные коды, — выходят и новые документы ISO. Система Юникод существует в общей сложности в следующих версиях:
Кодовое пространство
Хотя формы записи UTF-8 и UTF-32 позволяют кодировать до 2 31 (2 147 483 648) кодовых позиций, было принято решение использовать лишь 1 112 064 для совместимости с UTF-16. Впрочем, даже и этого более чем достаточно — сегодня (в версии 6.0) используется чуть менее 110 000 кодовых позиций (109 242 графических и 273 прочих символов).
Для обозначения символов Unicode используется запись вида «U+xxxx» (для кодов 0…FFFF), или «U+xxxxx» (для кодов 10000…FFFFF), или «U+xxxxxx» (для кодов 100000…10FFFF), где xxx — шестнадцатеричные цифры. Например, символ «я» (U+044F) имеет код 044F16 = 110310.
Система кодирования
Универсальная система кодирования (Юникод) представляет собой набор графических символов и способ их кодирования для компьютерной обработки текстовых данных.
Графические символы — это символы, имеющие видимое изображение. Графическим символам противопоставляются управляющие символы и символы форматирования.
Графические символы включают в себя следующие группы:
Юникод — это система для линейного представления текста. Символы, имеющие дополнительные над- или подстрочные элементы, могут быть представлены в виде построенной по определённым правилам последовательности кодов (составной вариант, composite character) или в виде единого символа (монолитный вариант, precomposed character).
Модифицирующие символы


Графические символы в Юникоде подразделяются на протяжённые и непротяжённые (бесширинные). Непротяжённые символы при отображении не занимают места в строке. К ним относятся, в частности, знаки ударения и прочие диакритические знаки. Как протяжённые, так и непротяжённые символы имеют собственные коды. Протяжённые символы иначе называются базовыми (англ. base characters ), а непротяжённые — модифицирующими (англ. combining characters ); причём последние не могут встречаться самостоятельно. Например, символ «á» может быть представлен как последовательность базового символа «a» (U+0061) и модифицирующего символа « ́» (U+0301) или как монолитный символ «á» (U+00C1).
Особый тип модифицирующих символов — селекторы варианта начертания (англ. variation selectors ). Они действуют только на те символы, для которых такие варианты определены. В версии 5.0 варианты начертания определены для ряда математических символов, для символов традиционного монгольского алфавита и для символов монгольского квадратного письма.
Формы нормализации
Поскольку одни и те же символы можно представить различными кодами, что иногда затрудняет обработку, существуют процессы нормализации, предназначенные для приведения текста к определённому стандартному виду.
В стандарте Юникода определены 4 формы нормализации текста:
Термины «композиция» и «декомпозиция» понимают под собой соответственно соединение или разложение символов на составные части.
Примеры
| Исходный текст | NFD | NFC | NFKD | NFKC |
|---|---|---|---|---|
| Français | Franc\u0327ais | Fran\xe7ais | Franc\u0327ais | Fran\xe7ais |
| А, Ё, Й | \u0410, \u0415\u0308, \u0418\u0306 | \u0410, \u0401, \u0419 | \u0410, \u0415\u0308, \u0418\u0306 | \u0410, \u0401, \u0419 |
| が | \u304b\u3099 | \u304c | \u304b\u3099 | \u304c |
| Henry IV | Henry IV | Henry IV | Henry IV | Henry IV |
| Henry Ⅳ | Henry \u2163 | Henry \u2163 | Henry IV | Henry IV |
Двунаправленное письмо
Стандарт Юникод поддерживает письменности языков как с направлением написания слева направо (англ. left-to-right, LTR ), так и с написанием справа налево (англ. right-to-left, RTL ) — например, арабское и еврейское письмо. В обоих случаях символы хранятся в «естественном» порядке; их отображение с учётом нужного направления письма обеспечивается приложением.
Кроме того, Юникод поддерживает комбинированные тексты, сочетающие фрагменты с разным направлением письма. Данная возможность называется двунаправленность (англ. bidirectional text, BiDi ). Некоторые упрощённые обработчики текста (например, в сотовых телефонах) могут поддерживать Юникод, но не иметь поддержки двунаправленности. Все символы Юникода поделены на несколько категорий: пишущиеся слева направо, пишущиеся справа налево, и пишущиеся в любом направлении. Символы последней категории (в основном это знаки пунктуации) при отображении принимают направление окружающего их текста.
Представленные символы

Юникод включает практически все современные письменности, в том числе:
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм.
Однако в Юникод принципиально не включаются логотипы компаний и продуктов, хотя они и встречаются в шрифтах (например, логотип Apple в кодировке MacRoman (0xF0) или логотип Windows в шрифте Wingdings (0xFF)). В юникодовских шрифтах логотипы должны размещаться только в области пользовательских символов.
ISO/IEC 10646
Консорциум Юникода работает в тесной связи с рабочей группой ISO/IEC/JTC1/SC2/WG2, которая занимается разработкой международного стандарта 10646 (ISO/IEC 10646). Между стандартом Юникода и ISO/IEC 10646 установлена синхронизация, хотя каждый стандарт использует свою терминологию и систему документации.
Сотрудничество Консорциума Юникода с Международной организацией по стандартизации (англ. International Organization for Standardization, ISO ) началось в 1991 году. В 1993 году ISO выпустила стандарт DIS 10646.1. Для синхронизации с ним Консорциум утвердил стандарт Юникода версии 1.1, в который были внесены дополнительные символы из DIS 10646.1. В результате значения закодированных символов в Unicode 1.1 и DIS 10646.1 полностью совпали.
В дальнейшем сотрудничество двух организаций продолжилось. В 2000 году стандарт Unicode 3.0 был синхронизирован с ISO/IEC 10646-1:2000. Предстоящая третья версия ISO/IEC 10646 будет синхронизирована с Unicode 4.0. Возможно, эти спецификации даже будут опубликованы как единый стандарт.
Аналогично форматам UTF-16 и UTF-32 в стандарте Юникода, стандарт ISO/IEC 10646 также имеет две основные формы кодирования символов: UCS-2 (2 байта на символ, аналогично UTF-16) и UCS-4 (4 байта на символ, аналогично UTF-32). UCS значит универсальный многооктетный (многобайтовый) кодированный набор символов (англ. universal multiple-octet coded character set ). UCS-2 можно считать подмножеством UTF-16 (UTF-16 без суррогатных пар), а UCS-4 является синонимом для UTF-32.
Способы представления
Юникод имеет несколько форм представления (англ. Unicode transformation format, UTF ): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт. 1 апреля 2005 года были предложены две шуточные формы представления: UTF-9 и UTF-18 (RFC 4042).
В Microsoft Windows NT и основанных на ней системах Windows 2000 и Windows XP в основном используется форма UTF-16LE. В UNIX-подобных операционных системах GNU/Linux, BSD и Mac OS X принята форма UTF-8 для файлов и UTF-32 или UTF-8 для обработки символов в оперативной памяти.
Punycode — другая форма кодирования последовательностей Unicode-символов в так называемые ACE-последовательности, которые состоят только из алфавитно-цифровых символов, как это разрешено в доменных именах.
Символы UTF-8 получаются из Unicode следующим образом:
Теоретически возможны, но не включены в стандарт также:
Несмотря на то, что UTF-8 позволяет указать один и тот же символ несколькими способами, только наиболее короткий из них правильный. Остальные формы должны отвергаться по соображениям безопасности.
Порядок байтов
В потоке данных UTF-16 старший байт может записываться либо перед младшим (англ. UTF-16 big-endian ), либо после младшего (англ. UTF-16 little-endian ). Аналогично существует два варианта четырёхбайтной кодировки — UTF-32BE и UTF-32LE.
Для определения формата представления Юникода в начало текстового файла записывается сигнатура — символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемый меткой порядка байтов (англ. byte order mark, BOM ). Это позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует. Также этот способ иногда применяется для обозначения формата UTF-8, хотя к этому формату и неприменимо понятие порядка байтов. Файлы, следующие этому соглашению, начинаются с таких последовательностей байтов:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
К сожалению, этот способ не позволяет надёжно различать UTF-16LE и UTF-32LE, поскольку символ U+0000 допускается Юникодом (хотя реальные тексты редко начинаются с него).
Файлы в кодировках UTF-16 и UTF-32, не содержащие BOM, должны иметь порядок байтов big-endian (unicode.org).
Юникод и традиционные кодировки
Внедрение Юникода привело к изменению подхода к традиционным 8-битным кодировкам. Если раньше кодировка задавалась шрифтом, то теперь она задаётся таблицей соответствия между данной кодировкой и Юникодом. Фактически 8-битные кодировки превратились в форму представления некоторого подмножества Юникода. Это намного упростило создание программ, которые должны работать с множеством разных кодировок: теперь, чтобы добавить поддержку ещё одной кодировки, надо всего лишь добавить ещё одну таблицу перекодировки в Юникод.
Кроме того, многие форматы данных позволяют вставлять любые символы Юникода, даже если документ записан в старой 8-битной кодировке. Например, в HTML можно использовать коды с амперсандом.
Реализации
Большинство современных операционных систем в той или иной степени обеспечивают поддержку Юникода.
В операционных системах семейства Windows NT для внутреннего представления имён файлов и других системных строк используется двухбайтовая кодировка UTF-16LE. Системные вызовы, принимающие строковые параметры, существуют в однобайтном и двухбайтном вариантах. Подробнее см. в статье Юникод в операционных системах Microsoft.
UNIX-подобные операционные системы, в том числе GNU/Linux, BSD, Mac OS X, используют для представления Юникода кодировку UTF-8. Большинство программ могут работать с UTF-8 как с традиционными однобайтными кодировками, не обращая внимания на то, что символ представляется как несколько последовательных байт. Для работы с отдельными символами строки обычно перекодируются в UCS-4, так что каждому символу соответствует машинное слово.
Одной из первых успешных коммерческих реализаций Юникода стала среда программирования Java. В ней принципиально отказались от 8-битного представления символов в пользу 16-битного. Сейчас большинство языков программирования поддерживают строки Юникода, хотя их представление может различаться в зависимости от реализации.
Методы ввода
Поскольку ни одна раскладка клавиатуры не может позволить вводить все символы Юникода одновременно, от операционных систем и прикладных программ требуется поддержка альтернативных методов ввода произвольных символов Юникода.
Microsoft Windows
Начиная с Windows 2000, служебная программа «Таблица символов» (charmap.exe) показывает все символы в ОС и позволяет копировать их в буфер обмена. Похожая таблица есть, например, в Microsoft Word.
Иногда можно набрать шестнадцатеричный код, нажать Alt+X, и код будет заменён на соответствующий символ, например, в WordPad, Microsoft Word. В редакторах Alt+X выполняет и обратное преобразование.
Во многих программах MS Windows, чтобы получить символ Unicode, нужно при нажатой клавише Alt набрать десятичное значение кода символа на цифровой клавиатуре. Например, полезными при наборе кириллических текстов будут комбинации Alt+0171 («) и Alt+0187 (»). Интересны также комбинации Alt+0133 (…) и Alt+0151 (—).
Macintosh
В Mac OS 8.5 и более поздних версиях поддерживается метод ввода, называемый «Unicode Hex Input». При зажатой клавише Option требуется набрать четырёхзначный шестнадцатеричный код требуемого символа. Этот метод позволяет вводить символы с кодами, большими U+FFFF, используя пары суррогатов; такие пары операционной системой будут автоматически заменены на одиночные символы. Этот метод ввода перед использованием нужно активизировать в соответствующем разделе системных настроек и затем выбрать как текущий метод ввода в меню клавиатуры.
Начиная с Mac OS X 10.2, существует также приложение «Character Palette», позволяющее выбирать символы из таблицы, в которой можно выделять символы определённого блока или символы, поддерживаемые конкретным шрифтом.
GNU/Linux
В GNOME также есть утилита «Таблица символов», позволяющая отображать символы определённого блока или системы письма и предоставляющая возможность поиска по названию или описанию символа. Когда код нужного символа известен, его можно ввести в соответствии со стандартом ISO 14755: при зажатых клавишах Ctrl и Shift ввести шестнадцатеричный код (начиная с некоторой версии GTK+ ввод кода нужно предварить нажатием клавиши «U»). Вводимый шестнадцатеричный код может иметь до 32 бит в длину, позволяя вводить любые символы Юникода без использования суррогатных пар.
Все приложения X Window, включая GNOME и KDE, поддерживают ввод при помощи клавиши Compose. Для клавиатур, на которых нет отдельной клавиши Compose, для этой цели можно назначить любую клавишу — например, Caps Lock.
Консоль GNU/Linux также допускает ввод символа Юникода по его коду — для этого десятичный код символа нужно ввести цифрами расширенного блока клавиатуры при зажатой клавише Alt. Можно вводить символы и по их шестнадцатеричному коду: для этого нужно зажать клавишу AltGr, и для ввода цифр A—F использовать клавиши расширенного блока клавиатуры от NumLock до Enter (по часовой стрелке). Поддерживается также и ввод в соответствии с ISO 14755. Для того чтобы перечисленные способы могли работать, нужно включить в консоли режим Юникода вызовом unicode_start(1) и выбрать подходящий шрифт вызовом setfont(8).
Mozilla Firefox для Linux поддерживает ввод символов по ISO 14755.
Проблемы Юникода
В Юникоде английское «a» и польское «a» — один и тот же символ. Точно так же одним символом (но отличающимся от «a» латинского) считаются русское «а» и сербское «а». Такой принцип кодирования не универсален; по-видимому, решения «на все случаи жизни» вообще не может существовать.
Некоторые недостатки связаны не с самим Юникодом, а с возможностями обработчиков текста.
Первоначальная версия Юникода предполагала наличие большого количества готовых символов, в последующем было отдано предпочтение сочетанию букв с диакритическими модифицирующими знаками (англ. combining diacritics ). Например, русские буквы Ё (U+0401) и Й (U+0419) существуют в виде монолитных символов, хотя могут быть представлены и набором базового символа с последующим диакритическим знаком, то есть в составной форме (англ. decomposed ): Е+ ̈ (U+0415 U+0308), И+ ̆ (U+0418 U+0306). В то же время множество символов из языков с алфавитами на основе кириллицы не имеют монолитных форм.
Наконец, некоторые редкие системы письма всё ещё не представлены должным образом в Юникоде. Изображение «длинных» надстрочных символов, простирающихся над несколькими буквами, как, например, в церковнославянском языке, пока не реализовано.
«Юникод» или «Уникод»?
«Unicode» — одновременно и имя собственное (или часть имени, например, Unicode Consortium), и имя нарицательное, происходящее из английского языка.
На первый взгляд предпочтительнее использовать написание «Уникод». В русском языке уже есть морфемы «уни-» (слова с латинским элементом «uni-» традиционно переводились и писались через «уни-»: универсальный, униполярный, унификация, униформа) и «код». Напротив, торговые марки, заимствованные из английского языка, обычно передаются посредством практической транскрипции, в которой деэтимологизированное сочетание букв «uni-» записывается в виде «юни-» («Юнилевер», «Юникс» и т. п.), то есть точно так же, как в случае с побуквенными сокращениями, вроде UNICEF «United Nations International Children’s Emergency Fund» — ЮНИСЕФ.
Формы, принятые иностранными организациями для русской передачи слова «Unicode», являются рекомендательными.