Знакомимся с Redis
Узнаём, для чего эта СУБД нужна и как ею пользоваться.


Redis ( REmote DIctionary Server, «удалённый серверный словарь») — это нереляционная резидентная СУБД, хранящая данные в виде пар «ключ-значение».
От реляционных баз Redis отличается:

Разрабатывает приложения на Java, воспитывает двух котов: Котлин и Монго.
Для чего используют Redis
Redis обычно применяют:
Как начать работать с Redis
Самый лёгкий способ — запустить Redis в docker-контейнере (если не знаете, что это, — добро пожаловать сюда).
Запускаем контейнер командой:
Убедимся, что контейнер запущен:

Затем открываем новую сессию и интерфейс командной строки ( CLI ):

Можно и сразу перейти в консоль Redis:

Вот мы и готовы работать с Redis.
Основные команды
Рассмотрим основные операции на примере хеш-таблиц.
HSET — сохраняет значение по ключу:
В примере выше мы создали объект person1 с двумя полями ( name и age) и соответствующими значениями.
HGET — получение значения по ключу (для определённого поля):
Выше мы получили значение поля name у ключа person1.
HGETALL — получение всех пар «ключ-значение»:
Получили значения всех полей по ключу person1.
HKEYS и HVALS — получение всех ключей и соответствующих им значений:
Как работать с оставшимися структурами данных — смотрите в официальном руководстве.
Транзакции
Важно понимать, что транзакции в Redis не сохраняют целостность данных (сбой одной операции при выполнении блока транзакции не мешает исполнить другие).
После запуска команды multi интерфейс redis-cli ответил на каждую последующую состоянием QUEUED («в очереди»). Когда мы запустили команду exec, то получили выходные данные каждой команды из очереди.
Отменить транзакцию можно командой discard. Она предотвратит запуск всех команд, ранее поставленных в очередь, — и Redis снова будет выполнять команды в обычном режиме. Чтобы сообщить серверу, что вы открываете новую транзакцию, нужно снова запустить multi.
Важно понимать, что когда команда уже встала в очередь (то есть синтаксически верна), то, даже если она и вызовет ошибку при выполнении, остальные команды выполнятся всё равно. А вот если не встала (невалидна, вызвала ошибку при постановке в очередь), то Redis блок транзакции отклонит, даже не дождавшись exec. И если вы попытаетесь после этого выполнить exec, вам скажут, что транзакция была отклонена из-за предыдущих ошибок.
Как Redis обрабатывает ошибки внутри транзакций, читайте тут.
Механизм подписок
Он позволяет одному клиенту создать канал событий и публиковать туда сообщения, а другому — подписываться и читать эти сообщения (так можно создать простой чат).
Механизм подписок не гарантирует, что сообщение будет доставлено. Мы отправляем сообщение в канал, а кто его примет (и примет ли) — обещать не можем, стоит помнить об этом и не использовать подписки там, где важно обратное.
Итак, клиент подписывается на канал командой:
ИТ База знаний
Полезно
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Redis – что это и для чего?
Еще немного про open source
Друг, начнем с цитаты:

Redis – это высокопроизводительная БД с открытым исходным кодом (лицензия BSD), которая хранит данные в памяти, доступ к которым осуществляется по ключу доступа. Так же Редис это кэш и брокер сообщений.
Надо признаться, определение не дает точного понимания, что же такое Redis. Если это так круто, то зачем вообще нужны другие БД? На самом деле, Redis правильнее всего использовать в определенных кейсах, само собой, зная про подводные камни – именно об этом и поговорим.
Про установку Redis в CentOS 8 мы рассказываем в этой статье.
Redis как база данных
Говорим про случай, когда Redis выступает в роли базы данных:
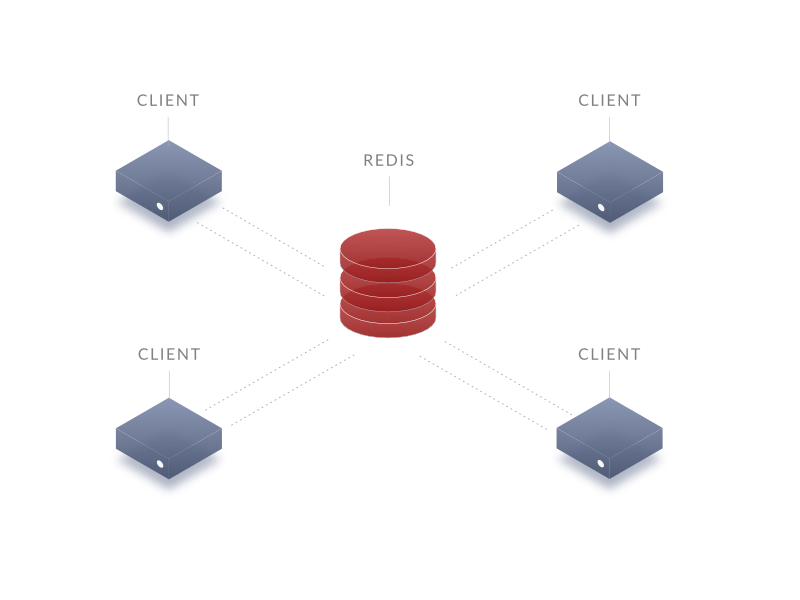
Пару слов про ограничения такой модели:
Теперь про преимущества модели:
Примеры использования
Представь, у нас есть приложение, где пользователям необходимо авторизоваться, чтобы выполнять какие – либо действия внутри приложения. Каждый раз, когда мы обновляем авторизационные данные клиента, мы хотим их получать для последующего контроля.
Мы могли бы отправлять лист авторизационных параметров (с некими номерами авторизаций, сроком действия с соответствующими подписями), чтобы каждое действие внутри приложения, сопровождалось авторизацонной транзакцией из листа, который мы прислали клиенту. С точки зрения безопасности, в этом подходе нет ничего плохого, если мы храним на своей стороне данные в безопасности и используем Javascript Object Signing and Encryption (JOSE), например. Но проблема появится в том случае, когда наш пользователь имеет более одной авторизации внутри приложения – такие схемы плохо поддаются масштабированию.
А что если вместо отправки листа авторизационных параметров, мы сохраним его у себя, а пользователю отправим некий токен, который они должны отправлять для авторизации? Далее, по этому токену, мы легко сможем найти авторизации юзера. Это делает систему гораздо масштабируемой. Redis, такой Redis.
Итого, для указанной выше схемы, мы хотим:
А вот, что на эти вызовы может ответить Redis:
В качестве бонуса от Redis, вы получите механизм экспайринга токенов (устаревания). Все будет работать.
Redis как кэш!
Redis почти заменил memcached в современных приложениях. Его фичи делают супер – удобным кэширование данных.
Еще один кейс
Предположим, перед нами такая задача: приложение, отображает пользователям данные с определенными значениями, которые можно сортировать по множеству признаков. Все наши данные хранятся в БД (например, MySQL) и показывать отсортированные данные нужно часто. Дергать БД каждый раз весьма тяжело и ресурсозатратно, а значит, нам нужно кэшировать данные в отсортированном порядке.
Окей, кейс понятен. Рэдис, что скажешь на такие требования?
Redis как брокер сообщений
Как и раньше, давайте обсудим плюсы и минусы, хотя их тут и не так много. Минусы:
Ну а плюсы, как обычно для Редиса – скорость и стабильность.
Кейс напоследок
Простой пример – коллаборация сотрудников одной компании. Предположим, у них есть приложение, где они работают над общими задачами. Каждый пользователь делает свой набор действий, о котором другие пользователи должны знать. А так же, юзеры могут иметь разные экземпляры приложений – десктоп, мобильный или что то еще.
Требования по этой задаче:
Выводы
Если данные нуждаются в усиленной защите, Редис подойдет в меньшей степени, лучше посмотрите в сторону MongoDB или Elasticsearch.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps
Redis на практических примерах

Redis — достаточно популярный инструмент, который из коробки поддерживает большое количество различных типов данных и методов работы с ними. Во многих проектах он используется в качестве кэшируещего слоя, но его возможности намного шире. Мы в ManyChat очень любим Redis и активно используем его в нашем продукте для решения огромного количества задач. Про некоторые интересные кейсы использования этой in-memory key-value базы данных я расскажу на примерах. Надеюсь, вам они будут полезны, и вы сможете применить что-то в своих проектах.
Рассмотрим следующие кейсы:
Кэширование данных
Давайте начнем с самого простого, один из самых популярных кейсов использования Redis — кэширование данных. Будет полезно для тех, кто не работал с Redis. Для тех, кто уже давно пользуется этим инструментом — можно смело переходить к следующему кейсу. Для того, чтобы снизить нагрузку на БД, иметь возможность запрашивать часто используемые данные максимально быстро, используется кэш. Redis — это in-memory хранилище, то есть данные хранятся в оперативной памяти. Ещё это key-value хранилище, где доступ к данным по их ключу имеет сложность O(1) — поэтому данные мы получаем очень быстро.
Получение данных из хранилища выглядит следующим образом:
Но для того, чтобы данные из кэша получить, их нужно сначала туда положить. Простой пример записи:
Таким образом, мы запишем данные в Redis и сможем их считать по тому же самому ключу в любой нужный нам момент. Но если мы будем все время писать в Redis, данные в нем будут занимать все больше и больше места в оперативной памяти. Нам нужно удалять нерелевантные данные, контролировать это вручную достаточно проблематично, поэтому пускай redis занимается этим самостоятельно. Добавим к нашему ключу TTL (время жизни ключа):
По истечении времени ttl (в секундах) данные по этому ключу будут автоматически удалены.
Как говорят, в программировании существует две самых сложных вещи: придумывание названий переменных и инвалидация кэша. Для того, чтобы принудительно удалить значение из Redis по ключу, достаточно выполнить следующую команду:
Также редис позволяет получить массив значений по списку ключей:
И соответственно массовое удаление данных по массиву ключей:
Очереди
Используя имеющиеся в Redis структуры данных, мы можем запросто реализовать стандартные очереди FIFO или LIFO. Для этого используем структуру List и методы по работе с ней. Работа с очередями состоит из двух основных действий: отправить задачу в очередь, и взять задачу из очереди. Отправлять задачи в очередь мы можем из любой части системы. Получением задачи из очереди и ее обработкой обычно занимается выделенный процесс, который называется консьюмером (consumer).
Итак, для того, чтобы отправить нашу задачу в очередь, нам достаточно использовать следующий метод:
Со стороны консьюмера нам необходимо обеспечить получение задач из очереди, это реализуется простой командой чтения из листа. Для реализации FIFO очереди мы используем чтение с обратной записи стороны (в нашем случае мы писали через RPUSH), то есть читать будем через LPOP:
Для реализации LIFO очереди, нам нужно будет читать лист с той же стороны, с которой мы в него пишем, то есть через RPOP.
Тем самым мы вычитываем по одному сообщению из очереди. В случае если листа не существует (он пустой), то мы получим NULL. Каркас консьюмера мог бы выглядеть так:
Для того, чтобы получить информацию о глубине очереди (сколько значений хранится в нашем листе), можем воспользоваться следующей командой:
Мы рассмотрели базовую реализацию простых очередей, но Redis позволяет строить более сложные очереди. Например, мы хотим знать о времени последней активности наших пользователей на сайте. Нам не важно знать это с точностью вплоть до секунды, приемлемая погрешность — 3 минуты. Мы можем обновлять поле last_visit пользователя при каждом запросе на наш бэкенд от этого пользователя. Но если этих пользователей большое количество в онлайне — 10,000 или 100,000? А если у нас еще и SPA, которое отправляет много асинхронных запросов? Если на каждый такой запрос обновлять поле в бд, мы получим большое количество тупых запросов к нашей БД. Эту задачу можно решать разными способами, один из вариантов — это сделать некую отложенную очередь, в рамках которой мы будем схлопывать одинаковые задачи в одну в определенном промежутке времени. Здесь на помощь нам придет такая структура, как Sorted SET. Это взвешенное множество, каждый элемент которого имеет свой вес (score). А что если в качестве score мы будем использовать timestamp добавления элемента в этот sorted set? Тогда мы сможем организовать очередь, в которой можно будет откладывать некоторые события на определенное время. Для этого используем следующую функцию:
Теперь возникает вопрос о том, как читать эту очередь. Если методы LPOP и RPOP для листа читают значение и удаляют его из листа атомарно (это значит, что одно и тоже значение не может быть взято несколькими консьюмерами), то sorted set такого метода из коробки не имеет. Мы можем сделать чтение и удаление элемента только двумя последовательными командами. Но мы можем выполнить эти команды атомарно, используя простой LUA скрипт!
В этом LUA скрипте мы пытаемся получить первое значение с весом в диапазоне от 0 до текущего timestamp в переменную val с помощью команды ZRANGEBYSCORE, если нам удалось получить это значение, то удаляем его из sorted set командой ZREM и возвращаем само значение val. Все эти операции выполняются атомарно. Таким образом мы можем вычитывать нашу очередь в консьюмере, аналогично с примером очереди построенной на структуре LIST.
Я рассказал про несколько базовых паттернов очередей, реализованных в нашей системе. На текущий момент у нас в продакшене существуют более сложные механизмы построения очередей — линейных, составных, шардированных. При этом Redis позволяет все это делать при помощи смекалки и готовых круто работающих структур из коробки, без сложного программирования.
Блокировки (Mutex)
Mutex (блокировка) — это механизм синхронизации доступа к shared ресурсу нескольких процессов, тем самым гарантируя, что только один процесс будет взаимодействовать с этим ресурсом в единицу времени. Этот механизм часто применяется в биллинге и других системах, где важно соблюдать потоковую безопасность (thread safety).
Для реализации mutex на базе Redis прекрасно подойдет стандартный метод SET с дополнительными параметрами:
где параметрами для установки mutex являются:
Чаще всего, когда мы пишем код, который пытается работать с shared ресурсом, который заблокирован, мы хотим дождаться его разблокировки и продолжить работу с этим ресурсом. Для этого можем реализовать простой метод для ожидания освободившегося ресурса:
Мы разобрались как ставить блокировку, теперь нам нужно научиться ее снимать. Для того, чтобы гарантировать снятие блокировки тем процессом, который ее установил, нам понадобится перед удалением значения из хранилища Redis, сверить хранимый хэш по этому ключу. Для того, чтобы сделать это атомарно, воспользуемся LUA скриптом:
Rate limiter
Достаточно частая задача, когда мы хотим ограничить количество запросов к нашему апи. Например на один API endpoint от одного аккаунта мы хотим принимать не более 100 запросов в минуту. Эта задача легко решается с помощью нашего любимого Redis:
Таким простым методом мы можем лимитировать количество запросов к нашему API, базовый каркас нашего контроллера мог бы выглядеть следующим образом:
Pub/sub
Pub/sub — интересный механизм, который позволяет, с одной стороны, подписаться на канал и получать сообщения из него, с другой стороны — отправлять в этот канал сообщение, которое будет получено всеми подписчиками. Наверное у многих, кто работал с вебсокетами, возникла аналогия с этим механизмом, они действительно очень похожи. Механизм pub/sub не гарантирует доставки сообщений, он не гарантирует консистентности, поэтому не стоит его использовать в системах, для которых важны эти критерии. Однако рассмотрим этот механизм на практическом примере. Предположим, что у нас есть большое количество демонизированных команд, которыми мы хотим централизованно управлять. При инициализации нашей команды мы подписываемся на канал, через который будем получать сообщения с инструкциями. С другой стороны у нас есть управляющий скрипт, который отправляет сообщения с инструкциям в указанный канал. К сожалению, стандартный PHP работает в одном блокирующем потоке; для того, чтобы реализовать задуманное, используем ReactPHP и реализованный под него клиент Redis.
Отправка сообщения в канал — более простое действие, мы можем сделать это абсолютно из любого места системы одной командой:
В результате такой отправки сообщения в канал, все клиенты, которые подписаны на данный канал, получат это сообщение.
Redis — высокопроизводительное хранилище данных
Бодрый день, хаброчеловеки!
Что такое Redis?
Redis — это высокопроизводительное нереляционное распределённое хранилище данных. В отличие от Memcached, который может в любой момент удалить ваши данные, вытесняя старые записи новыми, Redis хранит информацию постоянно, таким образом он похож на MemcacheDB.
Чем Redis отличается от существующих решений?
API для работы с Memcached (MemcacheDB) позволяет хранить массивы, но эти массивы будут сериализованы и сохранены как строки, таким образом атомарные операции над такими массивами не возможны.
Redis позволяет хранить как строки, так и массивы, к которым можно применять атомарные операции pop / push, делать выборки из таких массивов, выполнять сортировку элементов, получать объединения и пересечения массивов.
Производительность
110000 запросов SET в секунду, 81000 запросов GET в секунду на Linux-сервере начального уровня (тесты).
Высокая скорость работы Redis обеспечивается тем, что данные хранятся в оперативной памяти и сохраняются на диск либо через равные промежутки времени, либо при превышении определённого количества не сохранённых запросов. Из этого вытекает, что используя Redis, вы можете потерять результаты нескольких последних запросов, что вполне приемлимо для большинства веб-приложений, учитывая, что обращение к Redis по скорости сравнимо с обращением к оперативной памяти. Тем не менее, потерь можно избежать через избыточность — Redis поддерживает неблокирующую master-slave репликацию.
Sharding
Redis, как и Memcached, может работать как распределённое хранилище на многих физических серверах. Такой функционал реализуется в клиентских библиотеках, и к сожалению, «из коробки» этот функционал реализован пока только в Ruby API, однако это не мешает вам хешировать ключ самостоятельно и получать ID сервера, к которому с этим ключом обращаться.
API для PHP доступно как в виде модуля, написанного на C, так и в виде PHP5 класса, который общается с Redis-сервером через сокеты, таким образом не требуется устанавливать модуль.
Кроме того существует PHP5 класс от отечественного разрабочика (с именем, заслуживающим доверия. Я серьёзно.) — IMemcacheClient. (Спасибо DYPA за на водку)
Перспективы развития
Разработка ведётся очень активно, комиты происходят почти каждый день, сейчас доступна версия Redis 0.900 (1.0 release candidate 1), которая очень скоро станет версией 1.0
В ближайшем будущем авторы обещают внедрить разные интересные фичи, в том числе и сжатие данных.
Лицензия и поддерживаемые платформы
Redis — написан на ANSI C и работает на большинстве POSIX-систем (Linux, MacOS X). Это бесплатное открытое ПО под BSD лицензией =)
Что такое Redis: как работает и где используется?

Redis ( RE сучок DI ctionary S ервере) является передовым NoSQL ключ-значением хранилища данных используются в качестве базы данных, кэша, и брокера сообщений. Redis известен своими быстрыми операциями чтения и записи, богатыми типами данных и расширенной структурой памяти. Он идеально подходит для разработки высокопроизводительных масштабируемых веб-приложений.
Redis — одна из самых популярных баз данных типа «ключ-значение», занимающая 4-е место по удовлетворенности пользователей базами данных NoSQL. Популярность Redis продолжает расти, и многие компании ищут разработчиков Redis на такие должности, как администратор базы данных и другие.
Что такое Redis?
Redis — это хранилище структур данных в памяти с открытым исходным кодом, используемое в качестве базы данных, кеша и брокера сообщений. Redis был создан Сальваторе Санфилиппо в 2006 году и написан на C.
Это расширенное хранилище данных типа «ключ-значение» в NoSQL, которое часто называют сервером структуры данных, поскольку его ключи содержат строки, хэши, списки, наборы, отсортированные наборы, точечные рисунки и гиперлоги. Операции чтения и записи Redis выполняются очень быстро, потому что данные хранятся в памяти. Данные также могут быть сохранены на диске или записаны обратно в память.
Поскольку Redis хранит свои данные в памяти, он чаще всего используется в качестве кеша. Некоторые крупные организации, использующие Redis, — это Twitter, GitHub, Instagram, Pinterest и Snapchat.
Преимущества Redis
Как установить Redis
Согласно официальной документации, рекомендуемый способ установки Redis — скомпилировать его из исходников. Сначала загрузите его с официального сайта, а затем скомпилируйте, выполнив следующие действия:
Затем вы можете протестировать свою сборку, набрав make test. srcКаталог будет заполнен исполняемым Redis.
Рекомендуется скопировать сервер Redis и интерфейс командной строки в нужные места, используя одну из двух стратегий.
Оттуда запустите сервер Redis, выполнив redis-serverдвоичный файл (без аргументов). Поскольку нет явных файлов конфигурации, все параметры используют внутреннее значение по умолчанию. Это лучший способ начать, если вы новичок в Redis и хотите изучить среду.
Чтобы использовать Redis из вашего приложения, загрузите и установите клиентскую библиотеку Redis на основе языка программирования, который вы хотите использовать.
Типы данных Redis
Redis — это хранилище ключей и значений, но оно поддерживает многие типы структур данных в виде значений, отличных от строк. Ключ в Redis — это безопасная для двоичного кода строка с максимальным размером 512 МБ.
Давайте обсудим типы данных, которые поддерживаются в значениях.
String
Строка в Redis — это последовательность байтов. Они безопасны для двоичного кода, поэтому имеют известную длину, которая не определяется какими-либо завершающими символами. Вы можете хранить до 512 мегабайт в строке Redis. Он может хранить данные любого типа, такие как текст, целые числа, числа с плавающей запятой, видео, изображения или аудиофайлы.
В этом примере SETи GETпредставлены команды Redis, о которых мы поговорим позже. name- это ключ, а educativeэто строковое значение, которое мы храним.
В Redis списки — это списки строк, которые отсортированы по порядку вставки, поэтому элементы хранятся в связном списке. Вы можете добавлять элементы как на голове, так и на хвосте. Если нам нужно вставить элемент в список из 500 записей, это займет столько же времени, сколько и добавление элемента в список из 50 000 записей.
Вот несколько примеров операций для составления списка результирующих списков:
Наборы в Redis — это неупорядоченные коллекции строк. Этот тип значения аналогичен списку, но наборы не допускают дублирования, и элементы не сортируются ни в каком порядке. Вы можете добавлять или удалять участников вО (1)О ( 1 ) временная сложность.
Наборы полезны, когда мы хотим хранить данные, где важна уникальность. Например, сохранение количества уникальных посетителей веб-сайта.
Сортированные наборы
Мы можем сортировать элементы с типом значения Sorted Set. Каждый элемент будет связан с числом, которое мы называем счетом. Это определяет порядок.
Например, если у нас есть вызванный ключ vegetables, и мы хотим сохранить carrotи celeryв качестве значения. Оценка от carrot10 celeryдо 15. Первым будет морковь, затем сельдерей.
Если оценка двух разных элементов одинакова, мы проверяем, какая строка лексикографически больше.
В Redis тип хеш-значения — это пара значений поля. Они используются для представления объектов, но могут хранить множество элементов и полезны также для других задач. Хеш занимает очень мало места, поэтому вы можете хранить миллионы объектов в небольшом экземпляре хеша.
Фактически, хеш может хранить до <2>^ <32>2Взаимодействие с другими людьми3 2Взаимодействие с другими людьмиВзаимодействие с другими людьми- 1- 1 пары поле-значение, что составляет более 4 миллиардов.
Допустим, мы хотим хранить информацию об оценках студентов. Тема может быть ключевым. Значение может быть парой «поле-значение», где поле представляет собой имя учащегося, а значение — оценку каждого учащегося.
Вот еще один пример, чтобы познакомить вас с хешем Redis.
Команды Redis
Команды Redis используются для выполнения операций. Есть разные команды, которые мы можем применять к нашим различным типам данных. Ниже мы рассмотрим по одной команде для каждого типа данных, о котором говорилось выше, но имейте в виду, что в Redis существует множество команд.
Хранение строк в Redis
Самая простая форма данных, которая может храниться в базе данных Redis, — это строка. Мы рассмотрим две команды, используемые для хранения и выборки записей из базы данных Redis при использовании строк.
SET команда
Мы можем сохранить запись в Redis с помощью SETкоманды. Это установит ключ для хранения строкового значения. Если ключ уже содержит значение, оно будет перезаписано. Он имеет следующий синтаксис:
GET команда
Команда GETдает нам значение ключа. Если ключ не существует, он вернется nil. GETобрабатывает только строковые значения. Синтаксис:
Хранение списков в Redis
Мы также можем хранить списки, и база данных Redis хранит их в виде связанного списка. Когда мы вставляем новый элемент, мы можем вставить его либо в голову (крайний левый элемент), либо в хвост (крайний правый элемент). Мы рассмотрим две команды, используемые для добавления и удаления записей из головы при использовании списков.
LPUSH команда
Команда LPUSHиспользуется для вставки значения в начало списка. Мы можем использовать одно или несколько значений, а синтаксис следующий:
Примечание. Элементы вставляются в обратном порядке, потому что каждый элемент выбирается и вставляется в начале.
LPOP команда
Команда LPOP используется для удаления элемента из списка в начале (или слева).
Хранение наборов в Redis
Когда дело доходит до списка, мы допускаем дублирование элементов. Итак, если нам нужно добавить уникальные элементы, мы должны использовать набор, который хранится внутри как хеш-таблица. Это означает, что элементы хранятся случайным образом, и повторение не допускается. Давайте посмотрим на команду для добавления элемента из набора Redis.
SADD команда
Это позволяет нам добавлять указанные члены в набор, хранящийся под ключом. Если ключ не существует, создается новый набор.
Хранение отсортированных наборов в Redis
Элементы в наборе Redis не хранятся в каком-либо порядке. Итак, если мы хотим хранить элементы в отсортированном порядке, мы можем использовать отсортированные наборы, также называемые ZSets.
Перед вставкой каждому элементу должна быть присвоена оценка. База данных Redis сортирует элементы в порядке возрастания оценок. Посмотрим на команду добавления элементов в отсортированный набор.
ZADD команда
Эта команда добавит элементы в отсортированный набор в базе данных Redis. Мы можем указать несколько пар очков или членов. Если член уже находится в этом отсортированном наборе, оценка обновляется, и элемент повторно вставляется в правильную позицию для сохранения оценки. Вот синтаксис:
Хранение хэша в Redis
В Redis значение также может быть парой «поле-значение», которую мы называем хэш-структурой данных. Давайте посмотрим на команду для хранения хэша в Redis.
HMSET команда
Эта команда используется для хранения хэша в Redis. Он установит для полей соответствующие значения в хэше. Эта команда перезаписывает поля, которые уже существуют в хэше. Синтаксис этой команды:
При использовании Redis 4.0.0 HMSETсчитается устаревшим и HSETпредпочтительным.
Расширенные концепции Redis
Теперь, когда мы понимаем некоторые основы Redis и познакомились с командами, давайте рассмотрим некоторые дополнительные концепции.
Важное примечание о Redis
Для этого урока, вместо терминологии модель / Slave, мы будем использовать прогрессивную leader/ followerметафору. Использование нами этой терминологии не помешает вашему пониманию Redis.
Официальная документация Redis использует модель Master / Slave, которая преобладала в компьютерных науках на протяжении десятилетий, начиная с 1904 года.
В последние годы многие организации предприняли значительные усилия, чтобы противостоять этой проблемной метафоре и заменить ее.
В Educative мы верим в расширение возможностей разработчиков и изменение отрасли к лучшему. Использование инклюзивной терминологии является частью этого культурного сдвига.
Репликация данных в Redis
Когда данные хранятся на сервере и происходит сбой сервера, данные могут быть потеряны. Мы используем технику репликации данных, чтобы избежать этой проблемы. Это в основном означает, что данные хранятся на двух или более серверах, чтобы предотвратить потери или сбои. Репликация данных также снижает нагрузку на наши серверы, поскольку запросы пользователей балансируются по нагрузке.
Redis следует подходу лидера / подчиненного для репликации данных на сервере. Один из серверов — это a leader, а остальные — это серверы followers, которые все подключены к leader. Мы записываем все в каталог leader, который затем отправляет изменения в followers.
Если a followerотключен, он автоматически переподключится и leaderточно воспроизведет. Это можно сделать двумя способами:
Примечание. В Redis процесс репликации асинхронный. Эти followerсервера асинхронно признают данные из leader, так что leaderзнает, какие команды были обработаны.
Упорство
Поскольку Redis — это база данных в памяти, данные хранятся в памяти (или ОЗУ). Если сервер выходит из строя, все сохраненные данные теряются. Redis имеет механизмы резервного копирования данных на диске. Таким образом, данные загружаются с диска в память при перезагрузке сервера. Redis имеет два варианта сохранения:
Кеширование на стороне клиента
Когда клиенту требуются данные, он просит сервер Redis предоставить их, что требует большой пропускной способности для каждого запроса. Мы можем кэшировать результаты для наиболее часто используемых ключей на стороне клиента, чтобы повысить производительность.
Redis обеспечивает поддержку кэширования на стороне клиента, которое называется отслеживанием. Есть два разных подхода:
Что учить дальше
Теперь вы должны хорошо понимать, как работает Redis и что он может сделать для ваших приложений. Это мощный инструмент, популярность которого растет. Любой разработчик должен обладать солидными навыками Redis в своем арсенале инструментов. Но есть еще чему поучиться.
Далее вам следует изучить: