Урок №10. Пробельные символы
Обновл. 29 Мар 2021 |
При работе с реальными данными, такими как лог-файлы или даже пользовательский ввод, трудно не столкнуться с пробельными символами. Мы используем их в форматировании фрагментов информации, чтобы эти фрагменты было проще читать и визуально сканировать, но один лишь пробел может полностью сломать простейшее регулярное выражение.
Наиболее распространенными пробельными символами являются обычные пробелы ( ), табуляция ( \t ), новая строка ( \n ) и возврат каретки ( \r ). Кроме того, метасимвол пробельных символов \s будет соответствовать любому из вышеуказанных пробельных символов, являясь, таким образом, очень полезным при работе с необработанными данными.
| Задание | Текст | |
| Соответстовать | 1. abc |  |
| Соответстовать | 2. abc | |
| Соответстовать | 3. abc | |
| Пропустить | 4.abc | |
Поделиться в социальных сетях:
Всё (или почти всё) о пробеле
Как следует из заголовка, речь в статье пойдёт о неотъемлемой части любого русскоязычного (и не только) текста — о пробеле. Мы затронем историю пробела, виды пробелов, вопросы употребления пробела в веб-типографике.
История межсловного пробела
Межсловный пробел — сравнительно позднее изобретении в истории человеческой мысли. Глубоко история пробела изложена в книге Пола Санджера (Paul Saenger) «Space between Words: The Origins of Silent Reading», а также, несколько менее глубоко, в книге Иоганнеса Фридриха «История письма».
Также есть неплохая статья Антона Бизяева о пробелах и об их истории «В начале пробелов не было», которая была опубликована в 1997 году в журнале «Publish».
Вкратце, пробел появился достаточно поздно, в тех письменностях, где отсутствие разграничения слов приводило к сложности чтения (так называемое консонантное письмо, где записываются только согласные звуки). Однако в греческом и латыни, в которых записывали и гласные звуки, использование пробела было утеряно. Пол Санджер связывает это с тем, что чтение производилось вслух, что упрощало разграничение слов при восприятии текста.
Вновь пробел начал использоваться приблизительно в VII—IX вв. н. э., и эта традиция пришла из Ирландии, где у писцов и чтецов родным языком являлся древнеирландский, а религиозная литература записывалась на латыни. По-видимому, по этой причине монахи испытывали трудности с чтением вслух. Считается, что появление пробела плотно связано с постепенным переходом от чтения вслух к чтению про себя. Примерами книг на латыни с межсловными пробелами являются памятники британской литературы: Евангелие из Дарроу (VII в.) и Келлская книга (VIII—IX вв.).
В глаголице и кириллице пробел также отсутствовал, и в привычном нам смысле используется только с XVII века.
До того, как человечество изобрело наборный шрифт, никакой особенной классификации межсловных пробелов не было — ставили писцы пробелы на глазок и ставили. Напомню (мы писали об этом в статье «Выключка по ширине»), что рукопись и ксиллография относятся к способам создания текстов без подвижности литер. Естественно, пробелы могли получаться различной ширины, так как пропуски делались вручную.
Пробелы в ручном наборе
Когда подвижность литер появилась (а произошло это с появлением наборных шрифтов), появились соответственно и вопросы — а как же ставить пробелы, чтобы соблюдалась выключка по ширине?
Технология ручного набора такова, что набранная строка полностью зажимается в верстатке и в гранке, и, соответственно, должна иметь ширину, практически точно равную ширине полосы (подробнее с технологией ручного набора можно познакомиться в одноимённой книге М. В. Шульмейстера).
Строка при ручном наборе набиралась из литер (брусков, на торце которых делались выпуклые зеркальные копии букв, отпечатывающиеся на бумаге), а межсловные пробелы создавались с помощью так называемых шпаций — брусков различной толщины, у которых на торце нет печатающей поверхности. Выглядит это примерно вот так. Шпации для каждого кегля шрифта, естественно, выпускались свои, и имели различную ширину. Например, для шрифта кегля 10 пунктов (стандартный кегль для большинства текстовых изданий) выпускались шпации шириной 10, 5, 4, 3, 2 и 1 пункт.
Шпации шириной в кегль назывались кегельными или круглыми. Шпации в половину кегельной назывались полукегельными или полукруглыми. Также существует название «тонкая шпация», под которой понимают шпации толщиной 1—2 пункта для шрифта кегля 8—12 пунктов. То есть, для шрифта кегля 10 пунктов тонкая шпация обычно составляет 2 пункта (соответственно, 1⁄5 кегельной). Однако, в связи с отсутствием точного определения тонкой шпации, в руководствах издателя, редактора и верстальщика обычно говорят не об отбивке на тонкую шпацию, а об отбивке на столько-то пунктов (считая, что кегль шрифта равен 10 пунктам).
Таким образом, нужно понимать, что в зависимости от кегля шрифта доля круглой шпации (треть, четверть и т. п.) может иметь разную ширину в пунктах, и наоборот.
Традиционная ширина межсловного пробела
Итак, разобравшись с тем, что такое круглая и полукруглая шпации, перейдём к принятой в российском наборе ширине собственно межсловного пробела.
Шульмейстер пишет (стр. 94), что при наборе строки между словами ставится полукруглая. Когда строка набрана до конца, в большинстве случаев её ширина оказывается либо меньше, либо больше ширины полосы набора. Поэтому верстальщику приходится изменять ширину пробелов, уменьшая её минимум до 1⁄4 круглой и увеличивая максимум до 3⁄4 круглой (соответственно, при наборе кеглем 10 пунктов межсловные пробелы могут варьироваться от 3 до 7 пунктов). Естественно, бывают нюансы, зависящие от формата издания, но мы их касаться не будем.
Однако, Шульмейстер оговаривается, что сам по себе межсловный пробел в полукруглую великоват, и использование стандартного пробела в 1⁄3 круглой является как более экономичным с точки зрения расхода бумаги, так зачастую и более красивым. Также использование межсловного пробела в полукруглую не рекомендуется для узких шрифтов.
С появлением строкоотливных машин пробелы стали делаться равномерными по ширине в пределах одной строки, а ширина межсловного пробела стала варьироваться около 1⁄3 круглой.
Компьютерный набор и веб-типографика
В настоящее время мы ограничены возможностями используемых шрифтов, и, естественно, набором символов в Unicode. Нужно помнить, что далеко не все шрифты содержат большинство пробельных Unicode-символов.
При переходе к компьютерным системам вёрстки был совершён переход от указания ширины шпаций в пунктах к указанию ширины шпаций в долях круглой, так как шрифты стали легко масштабироваться до любого кегля, а пробельные элементы должны были оставаться пропорциональными кеглю шрифта.
Символы пробела в Unicode
Использование различных пробелов
Поскольку ширина межсловного пробела фиксирована в шрифте и изменяется автоматически при выключке по ширине, использование других пробельных символов в качестве межсловных оправдано только при наборе печатных изданий, и только при наличии глубокого понимания, для чего это делается.
В обычной вёрстке для веба для разделения слов достаточно пользоваться обычными и неразрывными межсловными пробелами.
Вместе тем, по правилам русскоязычной типографики в ряде мест должна использоваться тонкая шпация (точнее, в справочниках написано о двухпунктовой шпации, но мы будем употреблять термин «тонкая шпация» как наиболее соответствующий и с точки зрения устоявшейся терминологии, и с точки зрения внешнего вида строки при наборе).
Основные правила использования пробелов будут описаны ниже, но в целом мы рекомендуем следующий принцип для использования при вёрстке для веба.
Использование только тонкой шпации из всего разнообразия пробельных элементов позволяет, во-первых, сохранить гармоничный вид набранного текста, а во-вторых, не перегружать автора публикации разнообразными правилами употребления шпаций различной дробной ширины.
Обработка пробелов браузерами и поисковиками
При подготовке материала статьи мы провели своеобразный эксперимент на специально подготовленной странице. Яндекс и Google справляются с нестандартными символами хорошо, заменяя при поиске все нестандартные пробельные элементы на обычные (мы считаем, что это — правильное поведение). То есть, они не делают разницы между текстами «два слова», «два слова», «два слова» и т. п.
Основные правила употребления пробелов
Итак, ещё раз подчеркнём, что во всех правилах, перечисленных ниже, тонкая шпация используется только в том случае, когда автор отметает риск использования посетителем сайта браузеров, неверно отображающих тонкую шпацию. К ним относятся некоторые браузеры в *nix (возможно, это связано со встроенными шрифтами), MSIE версии 6.0 и раньше, браузеры для Mac (ими можно пренебречь, так как ошибка рендеринга заключается только в ширине шпации), возможно — некоторые браузеры для мобильных телефонов и КПК.
В том случае, если использование таких браузеров вероятно, мы рекомендуем использовать вместо тонкой шпации обычный или неразрывный межсловный пробелы.
Далее мы опишем те правила расстановки пробелов, которые чаще всего, по нашим наблюдениям, нарушаются при вёрстке текстов. Более подробную информацию о правилах набора текстов можно почерпнуть, например, в «Справочнике издателя и автора» А. Э. Мильчина и Л. К. Чельцовой.
Сокращения и символы
Числа и интервалы
Знаки препинания
Пробельные символы и форматирование ими кода в Html, а так же спецсимволы неразрывного пробела и другие мнемоники
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Чуть ранее мы уже успели поговорить о том, что такое язык Html, также узнали про оформление в нем комментариев и назначение директивы Doctype. Сегодня у нас на очереди понятие пробела в ХТМЛ, а еще связанное с ним форматирование кода при его написании (для удобства последующего его чтения и восприятия).

Ну и в связи с тем, что мы затронем тему неразрывного пробела и мягкого переноса, нам придется акцентировать наше внимание на так называемых спецсимволах или мнемониках, используемых в языке Html, которые позволят вам добавить в код web документа множество дополнительных символов, вроде уже упомянутого выше. Но обо всем по порядку.
Пробелы и пробельные символы в языке Html
Прежде, чем переходить к вопросу форматирования текста с помощью специально предназначенных для этого тегов (абзаца, заголовков и т.д.) я хочу остановиться на том моменте, как в языке ХТМЛ интерпретируются пробелы, переносы строки (Enter) и табуляция, как осуществляется разбивка текста в окне браузера при изменении его размера.
По умолчанию, при резиновой верстке сайта, браузер старается заполнить текстом все свободное пространство по ширине, но как только изменится размер этого пространства, то сразу же изменится и формирование текста. Возникают новые переносы, т.е браузер динамически переформатирует ваш текст на основании пробелов.
В языке Html в качестве пробельных символов используются:
Именно по каким-то из этих символов пробела и будет осуществляться перенос строки при форматировании текста в браузере. У разных посетителей вашего сайта будут разные размеры экрана браузера и, следовательно, разбивка текста во всех этих случаях может происходить по-разному (если вы используете, например, резиновый макет). Типичным примером может служить поисковая выдача Яндекса, где макет подстраивается под размер экрана по ширине, но до определенного минимального размера.
Но даже если вы используете фиксированный макет, то все равно при написании статьи в визуальном редакторе используемого вами движка (CMS) вы не сможете точно знать, где именно будет осуществляться перенос строки и по какому именно пробельному символу.
В связи с этим возникает вопрос: как не допустить разрыва конструкций типа «100 руб.» при формировании переноса в браузере по символу пробела в Html коде? Ответом на этот вопрос может служить использование не обычного пробела, а спецсимвола неразрывного пробела, который может выглядеть как:
В коде это может выглядеть примерно так:
Мнемоника неразрывного пробела не позволит браузеру осуществлять по нему разбивку строки ни при каких обстоятельствах. Иногда бывает нужно, наоборот, осуществлять принудительную разбивку длинного слова при изменении размера окна браузера по так называемой метке мягкого переноса, которая тоже формируется на основе спецсимвола. Но об этом мы поговорим чуть позже.
Визуальное форматирование кода для повышения его наглядности
Итак, еще раз повторюсь, переносы при форматировании текста в браузере автоматически создаются на месте расположения пробельных символов в коде, которые в свою очередь могут задаваться всего лишь тремя способами, описанными выше.
Особенностью языка гипертекстовой разметки является то, что любое количество пробелов (или переносов с табуляцией) идущих подряд, браузером заменяется при разборе Html кода на один единственный пробел. Что это нам дает? Ну, давайте подумаем.
Если десятки проставленных подряд пробелов, сотни переносов строк подряд и столько же расположенных подряд знаков табуляции в окне браузера все равно отобразятся как один, то можно использовать эту особенность для удобного нашему пониманию форматирования Html кода, чтобы потом можно было бы легко визуально отделить друг от друга разные элементы, контейнеры, таблицы и легко проверить наличие для них закрывающих тегов.
Например, такой вариант записи с обилием лишних пробелов, табуляций и переносов, которые нужных только для визуального форматирования кода, будет выглядеть очень легкочитаемым:
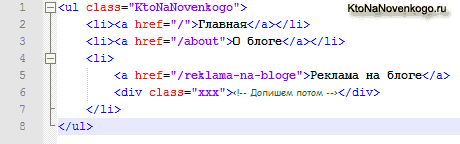
Но этот же фрагмент, где все лишние пробельные символы удалены, практически теряет свою читаемость:

Кстати, все вышесказанное будет справедливо и при записи свойств в CSS файлах, где вы сможете использовать удобное вам форматирование за счет лишних пробелов, переносов и табуляций, чтобы проще было бы найти и отделить друг от друга отдельные фрагменты.
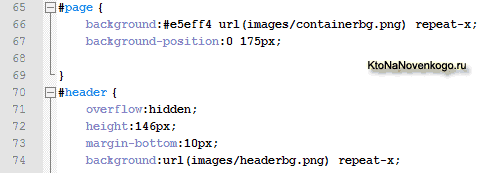
Уже после того, как вы все отладите и всесторонне протестируете, сможете сжать CSS (удалить из кода все пробелы) для повышения скорости загрузки.
Правда для такого рода визуального форматирования (которое не будет видно на вебстранице) чаще всего используют не сами пробелы, а именно символы табуляции и переноса строки. Есть такое правило — когда начинаете писать вложенный Html тег, то сделайте отступ с помощью табуляции (клавиша Tab на клавиатуре), а когда этот тег закрываете, то уберите отступ (сочетание клавиш Shift+Tab на клавиатуре).
Делать это нужно так, чтобы открывающий и закрывающий тэги были бы на одном вертикальном уровне (на одинаковом количестве табуляций от правого края страницы вашего Html редактора, например, Notepad++, о котором я писал тут). Кроме этого советую непосредственно после написания открывающего элемента сделать несколько переносов строки и сразу же прописать закрывающий на том же уровне (количестве табуляций), чтобы потом не забыть это сделать.
Т.е. открывающий и закрывающий элементы должны стоять на одном уровне по вертикали, а внутренние теги сдвигаем на один знак табуляции и располагаем закрывающие и открывающие опять же на одном уровне.
Для простых веб документов это может показаться излишеством, но при создании более-менее сложных, их код станет гораздо более наглядным и читаемым за счет обилия пробелов, а также в нем будет гораздо проще заметить ошибки за счет симметричного расположения тегов.
Спецсимволы или мнемоники в Html коде
Так, а теперь давайте поговорим о так называемых специальных символах, удобство использования которых я анонсировал в начале этой статьи. Спецсимволы еще иногда называют мнемоники или подстановки. Они предназначены для того, чтобы решить довольно давно возникшую в языке гипертекстовой разметки проблему, связанную с используемыми кодировками.
Когда вы набираете текст с клавиатуры, то происходит кодирование символов вашего языка по заранее установленному алгоритму, а потом они отображаются на сайте с помощью используемых вами шрифтов (где найти и как установить красивые онлайн шрифты для сайта) за счет декодирования.
Кодировок существует очень много, но для языка Html по умолчанию была принята расширенная версия кодировок ASCII под названием Windows 1251 (CP1251).
В этой кодировке текста было возможно записать всего лишь 256 знаков — 128 от ASCII и еще 128 для букв русского языка. В результате возникла проблема с использованием на сайтах знаки, которые не входят в ASCII и не являются буквами русского языка, входящими в состав кодировки Windows 1251 (CP1251). Ну, вздумалось вам использовать тильду или апостроф, а возможности такой изначально в используемой языком Html кодировке не заложено.
Именно для таких случаев и были придуманы подстановки или же, другими словами, мнемоники. Изначально спецсимволы имели цифровой вид записи, но затем для самых распространенных из них были добавлены их буквенные аналоги для простоты их запоминания.
В общем понимании, мнемоника — это такой знак, который начинается с амперсанда «&» и заканчивается точкой с запятой «;». Именно по этим признакам браузер при разборе Html кода выделяет из него спецсимволы. Сразу за амперсандом в цифровом коде подстановки должен следовать знак решетки «#», который иногда называют хеш. А уже потом следует цифровой код нужного символа в кодировке юникод.
В юникоде можно записать более 60 000 знаков — главное, чтобы нужный вам символ мнемоники поддерживался используемым на вашем сайте шрифтом. Есть шрифты с поддержкой почти всех знаков кодировки юникод, а есть варианты только с определенным набором символов.
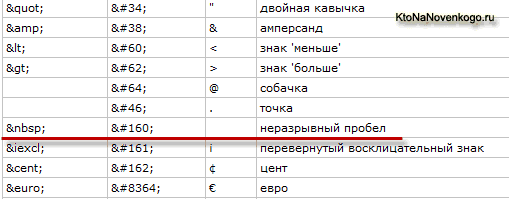
Полный список спецсимволов будет просто огромен, но наиболее часто используемые мнемоники вы можете позаимствовать, например, из этой таблицы:
Существует довольно интересный способ получения кода Html мнемоник для необходимого вам знака. Для этого достаточно будет открыть редактор Microsoft Word, создать новый документ и выбрать из верхнего меню «Вставка» — «Символ» (я пользуюсь 2003 версией, поэтому не знаю как сделать аналогичную операцию в более поздних версиях).
В открывшемся окне вам нужно выбрать шрифт, например, Times New Roman (или любой другой, который заведомо будет присутствовать на большинстве компьютеров посетителей вашего сайта — Courier или Arial, к примеру).
Добавьте из открывшегося списка в свой документ Word все нужные вам спецсимволы и сохраните данный вордовский документ как веб страницу (выбирается из выпадающего списка «.html» при сохранении). Ну, а затем вам лишь останется открыть эту веб страницу в любом Html редакторе (все тот же Notepad++ подойдет) и вы увидите все цифровые коды нужных вам мнемоник:
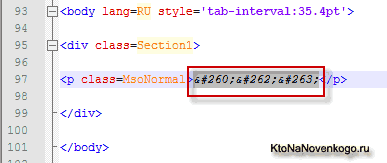
Способ немного сложноватый, но если приспичит использовать на странице своего сайта какой-нибудь редкий спецсимвол, то это будет проще, чем отыскивать в сети интернет таблицы, подобные приведенной чуть выше. Полученный код спецсимвола вам нужно будет вставить в нужное место и вместо него на веб странице браузер отобразит нужный вам знак (например, неразрывный пробел).
Неразрывный пробел и мягкий перенос в примерах
Как я уже упоминал выше и как вы можете видеть из приведенной чуть выше таблицы спецсимволов, некоторые мнемоники в Html получили кроме цифрового еще и символьное обозначение для их более простого запоминания. Т.е. вместо знака решетки «#» (хеша) в символьных вариантах используются слова. Например, все тот же неразрывный пробел может быть записан либо как (цифровая мнемоника), либо как (символьная).
При написании статей, если вам потребуется вставить в текст документа знак амперсанда (&) или открывающей угловой скобки ( или же вам просто нужно вставить знак меньше (
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Комментарии и отзывы (18)
Еще один RSS-читатель у Вас появился 😉
Пробелы (и табуляцию) надо использовать не только при форматировании HTML-кода, но и любого другого кода (на языках программирования), читабельность кода рулит.
Сейчас уже список Html мнемоник запомнить сложно, поэтому лучше пользоваться специальной программой по выбору этих мнемоник (но и за таблицу спасибо =)
О, как я просил, в примерах проще понимать, а то html сам по себе сложен. А так — конкретная таблица и самые используемые символы приведены.
Давайте поскорее уже о раскрутке, можно пошагово или какие-то эксперименты и их результаты описать.
Интересный портал. Регулярно читаю, часто беру на заметки Ваши советы. Дмитрий у меня вопрос, возможно не по теме. Я тут вот прочел Методы управления поведения роботом от яндекса _http://help.yandex.ru/webmaster/?id=1111858 в которой говорится о таком мета теге как
Scorpio: действительно, Яндекс, с опозданием всего на пару лет относительно Google и других мировых лидеров поиска стал учитывать тег rel=»canonical». Я уже когда-то писал о нем и о способах его правильной настройки для WordPress — Новый тег CANONICAL, предназначенный для удаления дубликатов страниц из индекса поисковиков.
Спасибо за примеры и классную табличку. Всё это возьму на вооружение.
Хорошая статья. Кстати по адресу http://sitemaker.x10.bz/cheat_sheets.php можно найти удобную и очень полную таблицу по мнемоникам.
Дмитрий, спасибо. Сколько раз читал, столько раз брал на заметку темы, освещённые вами. Да и эта интересная тема. А главное, далеко не все знают. И если в разговоре мелькает какой из тегов такого плана, часто приходится отдельно объяснять, почему так, а не иначе.
Огромное спасибо Дмитрию за такую замечательную тему.
Спасибо. Наконец исправил ошибку валидатора 😉
Дмитрий, а если нужное растояние между словами в 20 — 30 пробелов что лупашить это столько раз. Вот например хочу бегущую строку разделить на пару фраз отдаленных друг от дружки. Вот чего налепил.
Извините код не дало
В тэге налепил по паре штук   между фразами
Блок слева «Это не реклама, а похожие статьи с этого же сайта (ссылки открываются в новом окне):», мне кажется рекламой именно потому, что я не успел дочитать статью, отвлекся и забыл о чем думал, когда появилось оно(((((
Желательно и я думаю меня поддержат, чтобы это окно открывалось только в присутствии конца статьи, т.е я «дочитал», а тут оно.
Отичная статья, правда я не нашел то что искал, буду искать дальше.
Как убрать в вордпрессе разбивку слова при переносе оставшейся части на следующую строку?
ПОдскажите, как мне быть. У меня есть код:
$tm->textarea (‘textshort’, 5, 70, », 1, », », 1);
, который выводит текстовое поле с прописанным уже html-кодом «», но, он выводится в одну строку:
, а мне хотелось бы что бы вывод был вот таким:
Дмитрий, спасибо за обзор, познавательно. У меня вопрос
в заметке на вордпресс понадобилось использовать js-скриптик, где присутствует знак && (двойной амперсанд), и вот не получается его скормить вордпрессу ни как & ни как & ни как & говорит, мол Uncaught SyntaxError: Unexpected token &
Использование пробельных символов для форматирования кода HTML, неразрывный пробел и другие спецсимволы (мнемоники)
Здравствуйте, уважаемые читатели блога Goldbusinessnet.com! Те, кто хотя бы поверхностно успел ознакомиться с уроками по основам языка гипертекстовой разметки, наверное, уже приняли к сведению, что такое HTML, пусть и в общих чертах. А значит, имеют представление о том, какие вообще HTML символы используются в коде документа.
В сегодняшней статье мы попробуем разобраться, что из себя представляет пробел в HTML, в каких случаях можно применить пробельные символы при форматировании самого кода для удобного восприятия. Узнаем, когда необходимо применение неразрывного пробела, а также познакомимся с другими спецсимволами (или, как их еще называют, мнемониками).

На самом деле я бы посоветовал не игнорировать тему использования различных спец символов, поскольку это важная составляющая, позволяющая придать законченность изучению языка гипертекстовой разметки. В общем, предоставленная в этой публикации информация лишней точно не будет. Ну а теперь к делу.
Пробелы и пробельные символы в HTML
Сначала необходимо сделать важное замечание. На клавиатуре компьютера есть специальные клавиши, которые позволяют реализовать разделение текста (чуть подробнее об этом ниже). Однако, лишь широкая клавиша пробела обеспечивает раздел между словами не только в редакторе, но и в окне браузера. При переносе строк и отступе от края существуют нюансы.
Как вы знаете, отображение тех или иных элементов в веббраузере определяется тегами. Для форматирования текста применяется известный тег абзаца P, который является блочным. То есть его содержание располагается по всей доступной ширине.
Чтобы перенести строки внутри абзаца P, нужно воспользоваться одиночным тегом BR, с помощью которого это можно осуществить. Скажем, нам нужно вставить в текст какие-нибудь строчки из стихотворения, которые мы пишем в текстовом редакторе:

Несмотря на то, что строки стиха расположены корректно и переносы осуществлены в нужных местах, в браузере все будет выглядеть иначе:

Чтобы добиться такого же отображения в окне веб-обозревателя, нужно в каждом месте переноса строки прописать BR:

Теперь мы достигли выполнения поставленной задачи и в браузере стихотворные строчки отобразятся совершенно правильно:

Таким образом, нужные переносы строк выполнены. Здесь еще нужно отметить такую особенность, что множественные пробелы, идущие один за другим, веббраузер отображает как один. В этом вы сможете убедиться, если в том же редакторе админки WordPress попробуете поставить не один, а несколько пробелов между двумя словами и, нажав на кнопку «Сохранить», посмотрите на результат в браузере.
Пробел, табуляция и перенос строки
В принципе, с этими пробельными символами мы знакомимся сразу же, как начинаем работу с текстом в редакторе и форматируем его в нужном виде. Для реализации подобной задачи существуют специальные клавиши, каждая из которых соответствует своему пробельному символу:
Однако, как я сказал выше, конечный нужный результат не только в текстовом редакторе, но и в браузере, мы получаем лишь при использовании первой клавиши. Все три клавиши (в том числе табуляция и перенос строки полезно использовать при форматировании кода HTML. Допустим, вот как выглядит фрагмент кода в NotePad++ (тут об этом редакторе толковый материал) при отображении всех пробельных символов:

Мы получаем код, который легко читаем и понятен благодаря пробелам. Оранжевыми стрелками отмечены отступы, создаваемые с помощью клавиши Tab, а символами CR и LF переносы строк, осуществляемые посредством кавиши Enter.
Просматриваются контейнеры, вложенные один в другой, хорошо выделяются открывающие и закрывающие теги. В таком виде данный код можно спокойно редактировать. А теперь сравните его с таким же кодом, в котором нет подобного разделения текста:

Таким же образом с помощью пробельных символов можно прописать и правила CSS, которые будут визуально выглядеть понятными и удобоваримыми:

После того, как вы приведете все стили к общему знаменателю и полностью закончите редактирования файла стилей, можно будет подвергнуть сжатию CSS, удалив из кода все пробелы. Это необходимо для повышения скорости загрузки сайта, что очень важно при продвижении ресурса.
Спецсимволы (или мнемоники) в коде HTML
Теперь разберем, в каких случаях необходимо использование специальных символов, о которых я упомянул в начале статьи. Спецсимволы HTML, которые иногда называют мнемониками, введены для решения давней проблемы с кодировками, возникшей в языке гипертекстовой разметки.
При наборе вами текста с клавиатуры происходит кодировка символов языка, который вы используете. В веббраузере набранный текст будет отображен посредством выбранных вами шрифтов в результате обратной операции декодирования.
Дело в том, что подобных кодировок немало, сейчас у нас нет цели их подробно разобрать. Просто в каждой из них может не доставать тех или иных символов, которые, однако, необходимо отобразить. Скажем, приспичило вам прописать одиночные кавычки или знак ударения, а эти значки банально отсутствуют в наборе.
Для того, чтобы ликвидировать эту проблему, и была введена система спецсимволов, которая включает в себя огромное количество самых различных мнемоник. Все они начинаются со значка амперсанда «&» и заканчиваются обычно точкой с запятой «;». Поначалу каждому спецсимволу соответствовал свой цифровой код. Например, для неразрывного пробела, который рассмотрим чуть ниже подробнее, будет справедлива такая запись:
Но спустя некоторое время наиболее распространенным символам были присвоены буквенные аналоги (мнемоники), чтобы их было проще запомнить. Скажем, для того же неразрывного пробела это выглядит следующим образом:
В результате браузер отображает соответствующий символ. Список мнемоник очень объемный, наиболее часто применяемые спецсимволы HTML вы можете обнаружить из ниже следующей таблицы:
Случаи использования некоторых спецсимволов, в том числе неразрывного пробела и мягкого переноса
Если вы немного уже изучили таблицу, то получили подтверждение сказанным мною выше словам, что для отображения всех спецсимволов используется цифровой код ( ) либо его буквенный аналог (символьная мнемоника), где вместо совокупности решетки и цифр прописаны буквы ( ).
Поэтому из той же таблицы спецсимволов HTML берем соответствующие коды и вся запись будет выглядеть так:
Тогда в браузере выведется именно запись мнемоник, которые нужно применить для отображения тега FOOTER. Немного путано, но на этой странице вы сможете попрактиковаться в данном аспекте, введя в поле «HTML» мнемоники для соответствующих символов и задействуя кнопку «Run», а в области «Result» получая результат их отображения в браузере:

Обратите внимание, что я обеспечил перенос текста с помощью уже упомянутого тега BR с тем, чтобы сами символы отображались не в одну строку, а столбиком для удобства.
Идем дальше. Иногда в тексте возникают сочетания, которые нежелательно разделять по разным строкам. Скажем, «1000 руб.» будет логичным или оставить на верхней строке, или при недостатке места всю конструкцию перенести на на строку ниже.
Особенно это актуально, если пользователи применяют устройства с различной шириной экрана, в том числе мобильные. Ведь в этом случае веббраузер форматирует текст, подстраиваясь под новые условия. И если при стандартных размерах монитора текст выглядит корректно, то при их изменении все может поменяться.
Для этих случаев предусмотрен неразрывный пробел HTML, о котором я уже упоминал. Напомню, что в этом случае код пробела такой:
И его нужно вставить между двумя совокупностями знаков, которые требуется связать:
Теперь браузер ни в коем случае не осуществит их разделение, даже если потребуется форматирование текста для его корректного отображения.
Также бывает такая ситуация, когда очень длинное слово не помещается в свободное пространство и требуется перенести его часть. Как при необходимости предопределить перенос на новую строку в этом случае? Для этого есть спецсимвол мягкого переноса , который нужно поместить в то место, в котором слово нужно разорвать:
Если возникает ситуация, когда слово нужно перенести, то на месте нахождения мнемоники мягкого переноса образуется разрыв, где появится знак переноса (дефис), а оставшаяся часть данного слова окажется на ниже следующей строке.
Впрочем, опять же будет полезным все это дело, включая примеры неразрывного и мягкого переноса, воочию отследить на практике:

В окне этого редактора можно изменять размеры поля просмотра «Result», захватив левой кнопкой мышки край этой области и, не отпуская ее, тянуть влево для уменьшения ширины. Тогда возникает реальная ситуация, когда браузер начинает переформатировать содержимое для корректного его отображения.
И осуществляется перенос, который был предусмотрен в описанных мной примерах. Впрочем, вы сами можете подвигать просмотровое окно, расширяя-сужая ее, и визуально убедиться в этом.