Парсеры, обработка текста. Просто о сложном. CFG, BNF, LL(k), LR(k), PEG и другие страшные слова
Введение
Итак, вопрос, о чём же конкретно эта статья? Здесь я постараюсь помочь читателю с наименьшими потерями выходить из ситуации, когда надо разобрать какой-то текстовый формат, а библиотекой воспользоваться не получится. То есть решать абсолютно конкретную задачу общими средствами.
Сразу оговорюсь, тема сама по себе мало того, что ОЧЕНЬ непростая, так еще и до невозможности обширная и все охватить в рамках одной статьи просто не получится. Поэтому я начну от общего и буду переходить к частному, конкретно в этой статье давая скорее обзор инструментария (который, однако, может использоваться для решения вполне конкретных задач парсинга), чем погружаться вглубь концепций. Возможно, если читатели будут заинтересованы, статья превратится в цикл, в котором я могу раскрыть какие-то конкретные вопросы более подробно.
Написать её я решил потому, что имеющаяся по теме информация разрознена и зачастую не полна, на русском источников вообще очень мало, а те что есть, подразумевают достаточно приличное знакомство читателя с весьма специфической математикой. Поэтому, чтобы далекий от темы читатель не испытывал боль от сознания своей (мнимой) неполноценности, я и решил попытаться описать эту тему максимально просто.
Крепитесь, статья большая, некоторые места будут не очень интересными, но без них может быть непонятно.
Основные понятия
Перед разговором по теме стоит определиться с основными понятиями, чтобы не было разночтений. Это глоссарий данной статьи. Он может совпадать с общепринятой терминологией, но вообще говоря, не обязан, поскольку показывает картину, формирующуюся в голове автора.
Итак:
Варианты разбора
Когда мы сталкиваемся с задачей создания парсера, решение сводится, как правило, к 4 основным вариантам:
Решаем задачу парсинга
Пойдем по-порядку, варианты brute-force и regexp пропускаем.
Вот и настало время чуть подробнее остановиться на алгоритмах разборщика, вернее на используемых ими грамматиках. Итак, наиболее часто встречаются GLR (до O(L^3) или до O(L^4), как говорят некоторые источники (antlr)), LR, LALR и LL — все в пределах O(L). Наибольшей “прожорливостью” обладает GLR — она способна лучше обрабатывать неоднозначности грамматики, но за счет этого и более медленна. То есть если рассматривать “размер” класса обрабатываемых парсером грамматик(назовем его мощностью парсера), то при прочих равных, мощности распределятся так GLR > LR > LALR > SLR > LL. Потребление ресурсов, соответственно, близко к обратному. Но вернемся к грамматикам.
Составление или поиск грамматики для LR-парсера в целом достаточно просто и высок шанс, что составленный вами “на коленке” BNF будет спокойно воспринят парсером и обработан. Главное, грамматика должна быть полной, то есть описывать все возможные ситуации входного потока, кроме того попробуйте сами понять навскидку, можно ли зная k следующих символов (в зависимости от выбранного LR-парсера) однозначно определить, какое именно правило должно применяться.
Для LR-парсера могут возникать конфликты следующего вида:
Итак, что мы будем решать?
Ну, допустим, это будет простой калькулятор:
Если читатель попробует найти грамматику калькулятора в интернете, он увидит что часто операции сложения/вычитания и умножения/деления обрабатываются разными грамматическими конструкциями. Это сделано специально, чтобы учесть в грамматике такой момент, как приоритет операций (а также раскрыть неоднозначности грамматики). Мы это сделаем дальше по ходу статьи.
Пробуем найти нативное Python-решение, находим их много.
Переформулируем наш калькулятор так, как просит parglare
Достаточно? Сохраним в calc.pg и воспользуемся cli-tool
Упс! кажется, что-то лишнее. Бинго! я зачем-то вставил | = после “/” (нет, я-то знаю, откуда он там (но к теме статьи это не относится) ). Главное в том, что программа нам четко на это указала. Далее после исправления программа поругается еще на отсутствие; в конце обозначения нетерминала и на скобочку в правиле INT. Переформулированный вариант будет выглядеть так:
В итоге, pglr все нравится и он нам скажет:
Ну, а выше по выводу debug можно прочитать их красивое (и понятное) описание. Ну что ж, давайте подумаем. Во первых, давайте не будем самыми умными и выкинем нафиг positive_digit. Если кто-то напишет 0034 — во первых, он сам себе злобный буратино, а во вторых, большинство ЯП, в том числе Python при конвертации этого в число не скажут нам ничего и просто выдадут 34. Прекрасно, это сильно поможет. Во-вторых, нафиг отсюда разделение на int/float, для простоты предположим что все числа с плавающей точкой. Также, pglr понимает регулярные выражения в BNF, воспользуемся этим. Получим:
Ну, как бы то ни было, грамматика
Попробуем реально распарсить что-нибудь.
можем получить result.children и далее по дереву. Можем заодно подсчитать итоговое выражение, но делать это здесь не будем. Важно, что мы получили доступ к дереву объектов, для терминальных символов так же их “значение” и можем делать с этим все, что пожелаем.
Если мы хотим поправить конфликтные ситуации, как еще можно разрешить конфликты грамматики?
Есть несколько вариантов:
В этом случае решение более частное, но в ряде случаев более удобное. Parglare предоставляет хороший инструментарий для приоритезации правил, к примеру, для арифметических выражений можно выставить приоритет операции и ассоциативность (с какой стороны выполняется данная операция — слева направо или справа налево) чем приоритет выше, тем операция выполнится раньше (относительно остальных), к примеру, наша грамматика в такой нотации может выглядеть вот так:
Парсится, но работает не правильно. Например, для
получаем (при не-древовидном парсинге)
что, очевидно, не соответствует ожидаемому результату:
Мораль — лучше использовать стандартные описанные в BNF моменты. Блестящие и прикольные штуки блестят и прикольны, но не всегда работают. Или я не умею их готовить. А большинство библиотек парсинга — имеют версию alpha | beta.
По словам автора об этом баге, он происходит из-за того, что, по сути своей, ассоциативность (left) парсера на уровне алгоритма означает — предпочитать reduce, а не shift. То есть, по сути, если есть возможность “обрубить” правило, или продолжить в его рамках — лучше обрубить. Поскольку парсинг идет слева направо, это и означает левую ассоциативность. Причина же ошибки в том, что не определена приоритетность для правил внутри ADDOP/MULOP, что ломает все правило.
Однако, даже если мы зададим приоритетность (например:
ADDOP: “+” <1>
| “-” <1>), работать все равно не будет, уже из-за другой ошибки.
Напоследок пример с инлайн-функциями, привязываемыми непосредственно к правилам, из документации parglare.
Установка довольно простая, для linux это
Для того, чтобы работать на python2, нужно еще доустановить
Дальше попробуем сделать для него грамматику. У него чуть отличается формат, поэтому двойные кавычки заменим на одинарные и чуть перепишем регулярное выражение, а так же добавим обозначение для WS, который в предыдущем инструменте задавался по умолчанию. Левую рекурсию в нашем случае можно устранить просто переписав на правую.
Важный момент! В ANTLR есть правила парсера и грамматические правила. К появлению узла в результирующем AST ведут правила парсинга. Кроме того, существует некоторое различие, что можно/нельзя в грамматических/правилах парсинга. В частности, в правилах парсинга нет регулярных выражений. Кроме того, парсер должен получить входное правило, стартовый нетерминал (вообще, все несколько сложнее, но в нашем случае вполне хватает и этого). Вообще, стоит заметить, что ANTLR имеет довольно мощный синтаксис, так же поддерживает инлайн функции (пусть и несколько в ином формате) и “не попадающие в дерево” нетерминалы и кое-что еще. В итоге, наша грамматика выглядит так:
Файл при этом называется calc.g4 (Это важно! название файла должно совпадать с названием грамматики внутри).
Далее, мы можем навесить на грамматику листенеры и наслаждаться.
… Наслаждаться неправильно работающей программой. Вернее, правильно, но неожиданно.
И я признаю свою неудачу. Да, задача решаема. Но пользуясь только документацией и поиском на общие темы, мне её решить не удалось. Причины… Во-первых, исключая книгу по ANTLR, доступные в сети источники не отличаются подробностью и выразительностью. Во-вторых, в сети масса материалов по разным (не совместимым) версиям ANTLR. Нет, я все понимаю, развитие и прочее. Но почему-то в процессе знакомства с инструментом у меня сложилось ощущение, что о понятии обратной совместимости автор даже не слышал. В общем, грустно.
Update
Как верно замечено, одна голова хорошо, а две лучше.
Переформулирование грамматики с право-ассоциативной на левую выполняется буквально «щелчком пальцев» (Спасибо Valentin Nechayev netch80 за дополнение) — нужно всего лишь заменить
Левую рекурсию в данном случае ANTLR обрабатывает без вопросов (видимо, благодаря каким-то оптимизациям). Вывод простых листенеров в этом случае
Итак, перейдем к практике.
Используем Arpeggio от автора parglare:
Дальше разбираемся с документацией и узнаем, что рекомендованным для работы с AST для этой библиотеки является шаблон посетитель (visitor), весьма похожий на рекомендованный в ANTLR слушатель (listener). К счастью, здесь для всего эксперимента мне хватило часа, все оказалось не сложно:
При запуске выведет следующее:
Если есть желание посмотреть, как посетитель обходит дерево, можно раскомментировать debug
Как мы видим, грамматика претерпела небольшие, но важные изменения. В частности, если мы обратим внимание на правила stmt и term, то будет понятно, что они имеют произвольное число элементов. Соответственно, благодаря этому, обработка ассоциативности математических операций целиком и полностью на нашей совести. Несмотря на эти изменения, программа остается простой и понятной.
Общие выводы
На самом деле, выводов несколько:
Заключение
В заключение хочется сказать, что это было интересное исследование. Я попытался описать свои выводы максимально просто и понятно, надеюсь, мне удалось написать эту статью так, чтобы тема стала понятна даже далеким от математики программистам, хотя бы в общих чертах, достаточных для пользования существующим инструментарием.
Можно задавать любые вопросы, если какие-то подробности по теме будут волновать многих, они могут послужить для написания других статей.
Как и обещал, несколько полезных ссылок по теме статьи:
Парсинг: что это такое простыми словами
Сегодня парсинг настолько распространен, что о нем должен знать каждый вебмастер, а маркетолог и подавно. Когда-нибудь его надо включать в список обязательных инструментов, ведь при грамотном использовании можно извлечь немало пользы. Процесс этот отличается от взлома, а если следовать инструкциям (прописанным в robots.txt на сайтах), то и вполне законный.

Что такое парсинг и что значит парсить
Дословный перевод слова parsing — делать грамматический разбор или структурировать. В программировании/информатике, это автоматический сбор и систематизация необходимых сведений, размещенных на веб-ресурсах с помощью специальных программ.
Принцип работы парсинга основывается на сравнении готового общепринятого шаблона и найденной в сети информации. Например, вы создали интернет-магазин и хотите его продвигать. Вам нужно скопировать данные о товарах (цены, изображения, описания) у конкурентов, а потом разместить на своем сайте. Делать это вручную — длительная и рутинная работа, особенно когда речь идет о 500-1000 товарах. Поэтому процесс автоматизируется, и сбор данных доверяется программе/сервису. Результатом станет колоссальная экономия времени.
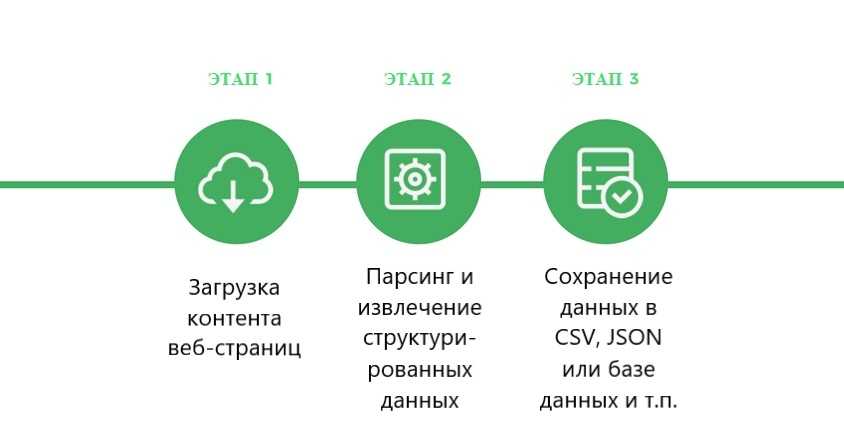
Подробнее о преимуществах автоматического сбора данных:
Единственное, что не умеет делать парсер, это уникализировать информацию — контент просто собирается из открытых источников.
Программа парсер
В роли парсера может выступить программа, сервис или скрипт. Функция у них одна — собрать данные с указанных web-сайтов, анализировать и выдать в нужном формате. Обычно используют десктопные и облачные парсеры, основное преимущество которых в отсутствии необходимости скачивать программу и устанавливать на свой комп. Вся работа производится в облаке.
Вот, например, несколько облачных парсеров на русском языке.
А это пара десктопных сервисов:
Что такое парсинг слов и зачем нужно
Парсинг также активно применяется вебмастерами и оптимизаторами для сбора семантического ядра с дальнейшей кластеризацией запросов. Таким образом, инструмент может решить вопросы с продвижением сайта и составлением рекламной кампании в Яндекс.Директе и Гугл Адс.
Среди популярных программ для парсинга в Seo:
В этапы работ над семантическим ядром сайта входит — определение поисковых фраз, анализ конкурентов, сбор данных со всех источников и т. д.
Что такое парсинг товаров и зачем нужно
Парсить товары, значит — собирать нужную информацию о продукции из готового каталога онлайн-магазинов. Обычно это делается в целях анализа ценовой политики конкурентов или для заполнения витрины своих сайтов. Ручной сбор такой информации и тщательная сортировка занимает много времени, поэтому автоматизация процесса напрашивается априори.
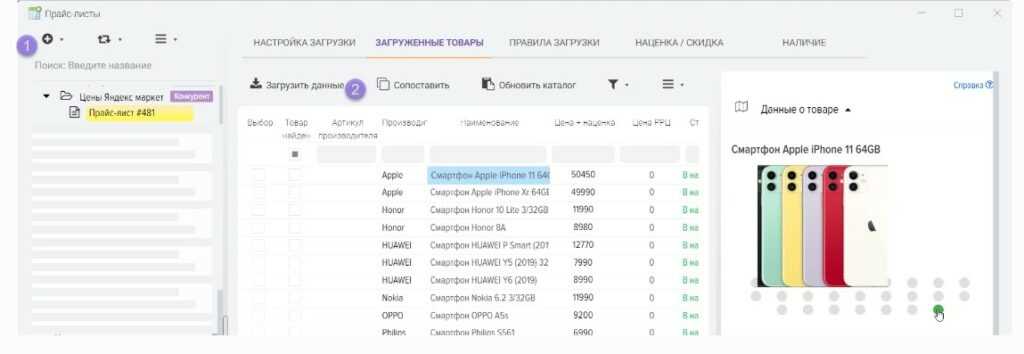
Например, парсинг товаров часто используется владельцами крупных интернет-магазинов. Это позволяет избавиться от рутинной работы, увеличить скорость сбора данных и сделать процесс более качественным.
Вот как работает парсинг:
Что такое парсинг сайтов и зачем нужно
Парсинг сайтов бывает двух типов:
Алгоритм работы простой — машинальное извлечение открытых данных. Парсер переходит по ссылкам исследуемого сайта и собирает информацию по каждой странице. Сведения записываются в Excel или какой-нибудь другой файл.
Что такое парсинг аудитории и зачем нужно
Автоматический поиск и выгрузка данных о пользователях соцсетей по конкретному алгоритму называется парсингом аудитории. Данный процесс проводится на автомате (специальными программами) или вручную (таргетологи) — целью является выгрузка собранной информации в соответствующий рекламный кабинет.
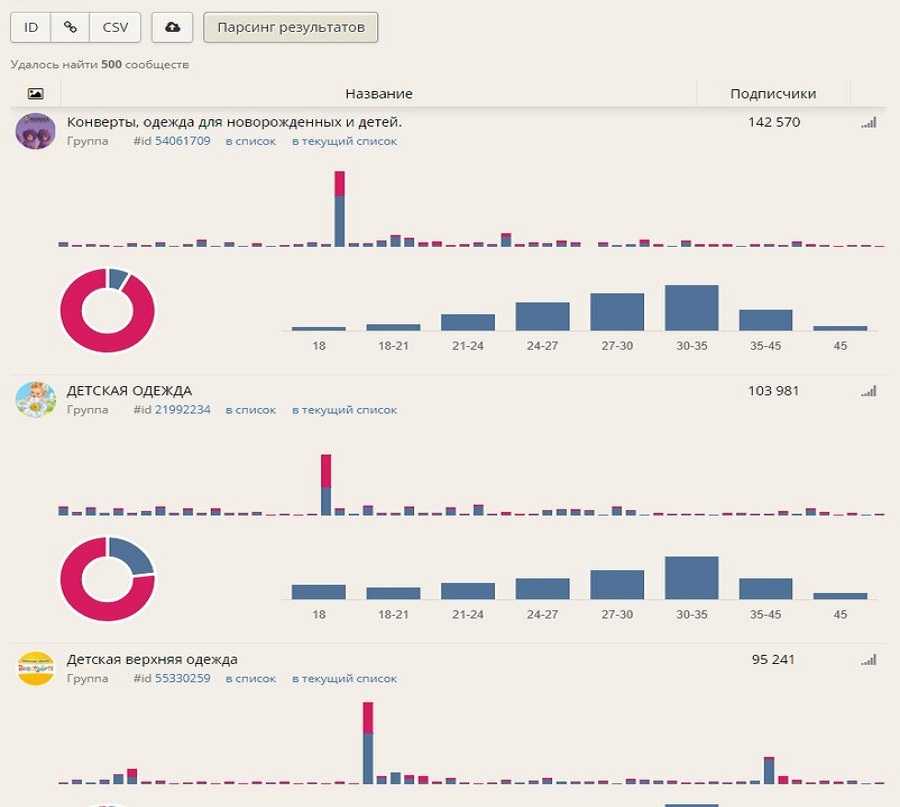 Парсинг аудиторий из Инстаграма и Фейсбука
Парсинг аудиторий из Инстаграма и Фейсбука
Чаще всего аудиторию группы парсят по активным ее пользователям — админам, модераторам, редакторам или просто старожилам, регулярно публикующим контент. Такой метод позволяет быстро и точно подобрать ЦА под свою нишу. Это будут потенциальные покупатели, которых реально заинтересует товар или услуга. Таким образом, маркетолог сэкономит средства и время, а реклама не будет показываться всем подряд.
Парсинг по аудитории можно настроить еще точнее, используя различные критерии выбора — возраст, семейное положение, финансовый статус, хобби и интересы. В таком случае бюджет РК сократится еще больше, а вероятность покупок и целевых действий возрастет.
Что такое парсинг в программировании и зачем нужно
Принцип работы парсинга в программировании — сравнение строк или конкретных символов с готовым шаблоном, написанном на одном из языков. Другими словами, это процесс сопоставления и проверки стоковых данных, проводимый по определенным правилам. Цель — найти проблемы производительности, несоответствие кода требованиям и другие недостатки сайтов/ресурсов/приложений.
Обычно айтишники разрабатывают собственные парсеры на таких языках, как C++, Java Programing. Делается это из-за того что иногда требуемый синтаксический анализатор невозможно найти в свободном доступе.
На самом деле, парсинг в программировании не является чем-то сверх сложным. Рассмотрим, как он работает на примере разбора даты из строки.

С первого взгляда это какой-то непонятный код, но если приглядеться, то можно разобрать узнаваемые части.
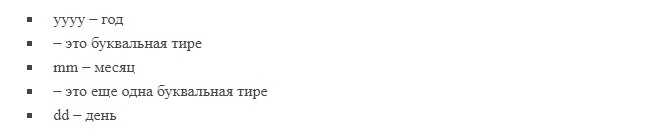
Примерно таким же способом осуществляется синтаксический анализ целого языка. Строки делятся на маленькие биты синтаксиса. Парсинг применяется не только в программировании, но также в аналитике и любой другой области, где можно работать с данными в стоковом формате.
Что такое парсинг в Инстаграм и зачем нужно
Парсинг в Инсте используют как один из инструментов для работы с ЦА — чтобы отсортировать пользователей, заинтересованных в товаре. Благодаря этому снижается рутина и экономится время.
У парсинга в Instagram имеются широкие возможности анализа и мониторинга. Инструмент помогает собрать всю нужную информацию и наладить взаимодействие с пользователями. Вот что с его помощью получится сделать в Инстаграме:
Все эти функции позволят точечно запустить рекламную кампанию, настроить таргет и оформить «вкусное» коммерческое предложение.
Что такое парсинг Авито и зачем нужно
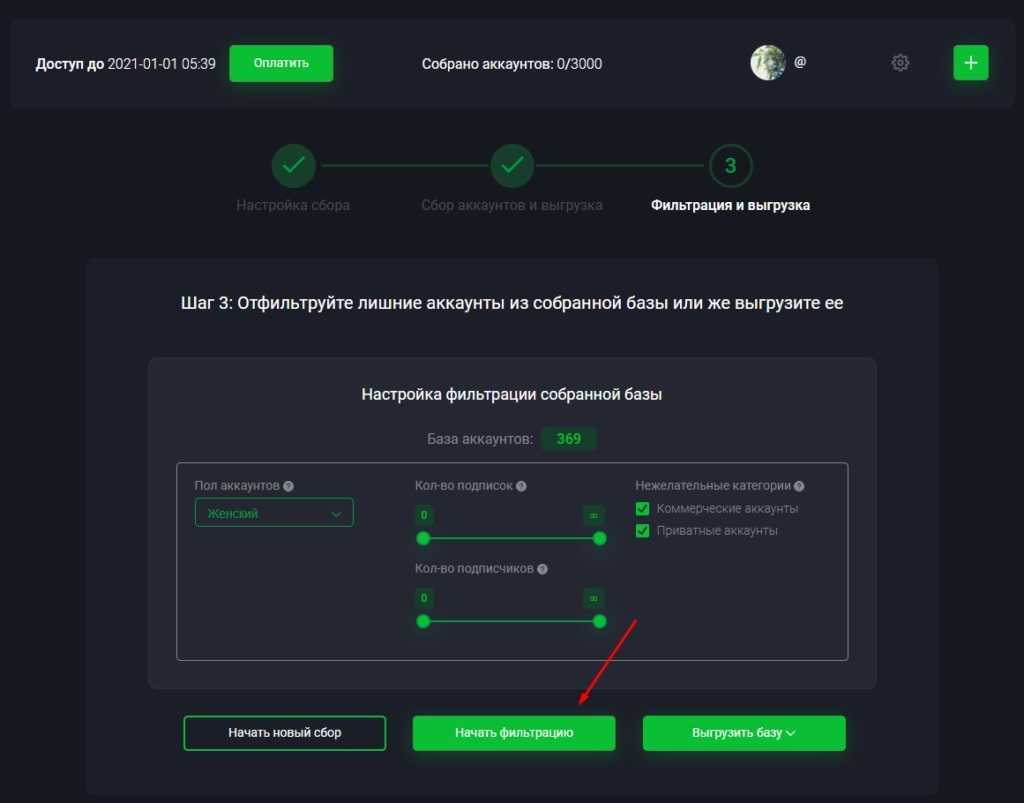
Парсинг полезен также в Авито — самой популярной доски объявлений в Рунете. С его помощью можно получить информацию обо всех постах, размещенных в определенных категориях, включая номера телефонов и адреса.
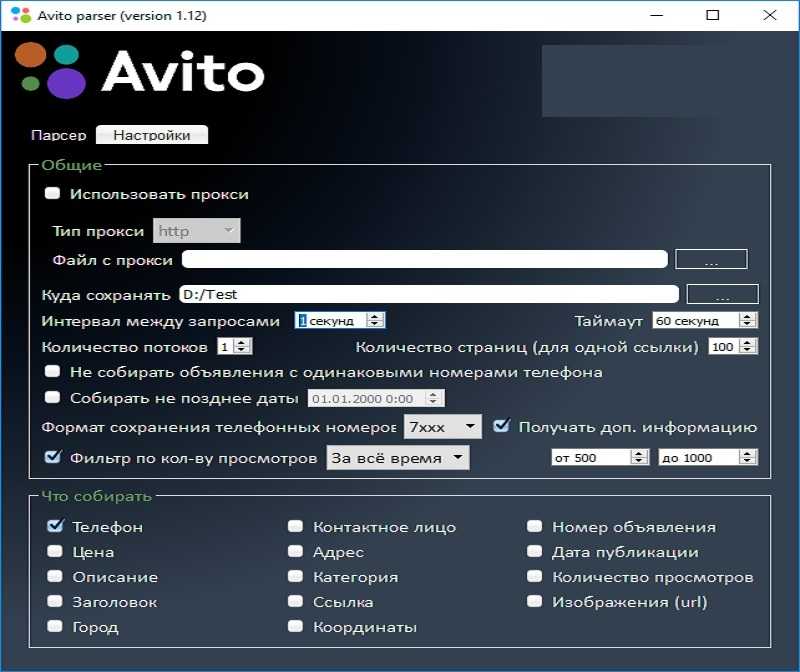
Чтобы спарсить данные с Avito, достаточно сделать так:
Инструмент соберет всю требуемую информацию в течение дня (в зависимости от объема данных) и выгрузит в документ. Обычно арбитражникам и маркетологам бывают нужны имена/контакты людей, цены на товары и изображения.
Полученные сведения можно использовать для отправки уведомлений на email, Gold calling, заполнения собственных площадок, анализа конкурентов и много чего еще. Сейчас есть возможность применять несколько парсеров для Авито — AvitoMonsterParser, FastParserAvito, Avi2-parser и другие.
Что такое парсер выдачи и зачем нужно
Парсеры для мониторинга поисковой выдачи входят в обязательный джентльменский набор опытного вебмастера, оптимизатора и маркетолога. Инструмент в этом случае настроен на сбор информации с заданного источника (Гугл, Яндекс, соцсети, форумы).
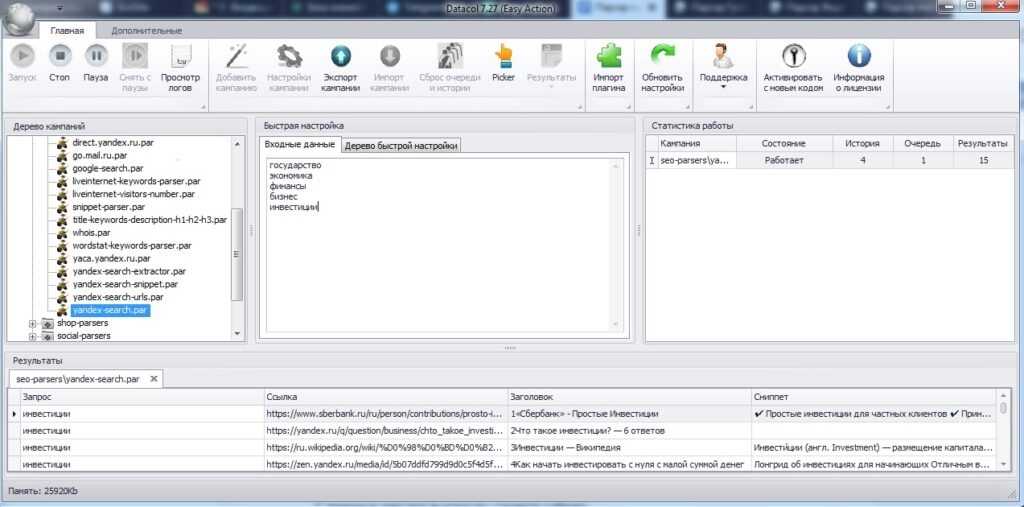 Ттак выглядит парсер на Яндекс
Ттак выглядит парсер на Яндекс
В первую очередь такой сбор данных нужен для анализа сайтов конкурентов. Парсинг даст возможность определить лидеров топа, узнать их характеристики в разрезе Seo. Например, вот какие данные чужих ресурсов:
Предоставленная информация поможет специалисту найти качественные сайты-доноры для размещения на них обратных ссылок, потенциальных клиентов/партнеров, а также площадки для рекламы.
Что такое парсинг цен и зачем нужно
Обычно ценовая «разведка», а в частности про оборот товара осложняется тем, что некоторые компании скрывают такую информацию. Напротив, такие гиганты, как Wildberries, Lamoda, Leroy Merlin ее открыто выставляют. На основе этих данных можно будет составить общее представление о продажах и сделать полезные выводы. К примеру, определить самые продаваемые позиции и сфокусироваться на них, а дешевые отсечь.

Цены можно парсить из разметки shema.org — это самый простой способ. Но если стоимость бывает зачеркнута или прайс с остатками товара загружается отдельными запросами к серверу, приходится использовать более функциональные программы. Сегодня есть такие проги, которые умеют раскрывать информацию методом эмулирования.
Кейсы по заработку на парсинге
Существует несколько способов заработка на парсинге. Но обычно заказчиков интересуют:
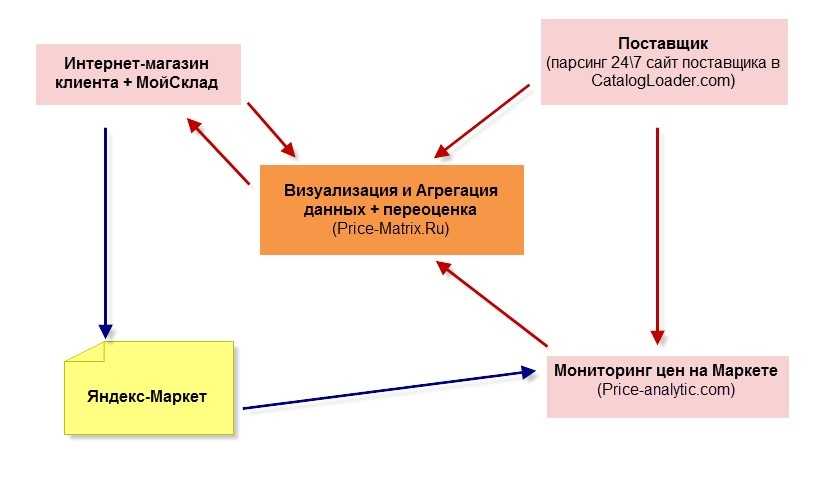
Ниже представлен интересный кейс от CatalogLoader, решивший задачи компании, закупающейся в буржунете и продающей на Яндекс.Маркете.
Что надо было сделать:
Задача решилась эффективно, клиент получил все необходимые данные. Использовался парсер сервиса CatalogLoader.com, собравший всю актуальную информацию с зарубежного интернет-магазина по нужным категориям/брендам. Сведения выгрузили в Price-Matrix.ru, где можно их анализировать и делать переоценку.
Еще один кейс, выложенный на сайте im-business. К ним обратился клиент, занимающийся грузоперевозками Россия-Беларусь. Ниша оказалась весьма конкурентной, поэтому человеку приходилось держать постоянный штат операторов и регулярно обновлять сайты с запросами на перевозку — чтобы не упустить заказы, иначе конкуренты не спят.
Задача для команды была следующая: спарсить информацию с 5 сайтов, которые постоянно мониторят заявки и отбирают их по определенным критериям. Сложность была в том, что все площадки разные — для некоторых требовалась регистрация. Пришлось в настройках прописать код для авторизации.
Дальше сделали так:
Все полученные данные сохраняли в общей таблице, каждый параметр по своим ячейкам. Заказчику давалась возможность отфильтровывать грузы, отмечать взятые в работу, а обработанные заявки выгружать для логиста.
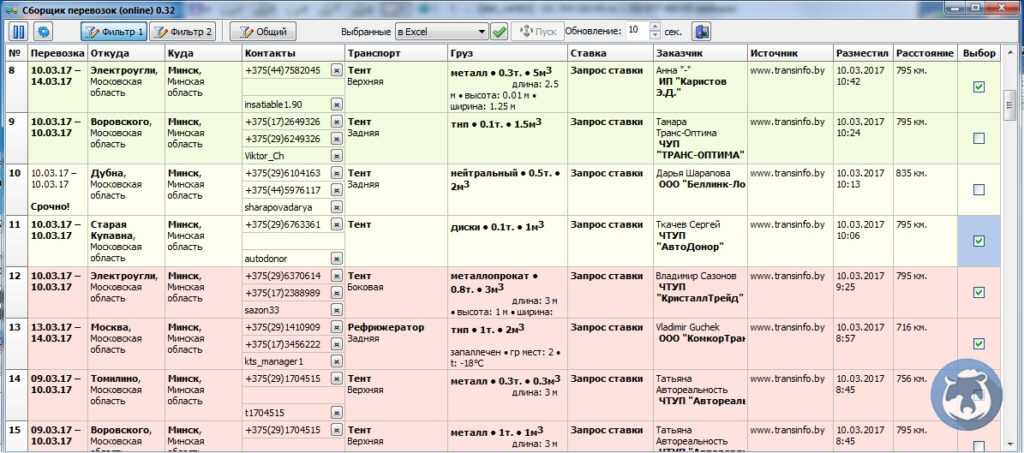
Результат — удалось сбросить значительную нагрузку с операторов фирмы, заявки стали обнаруживаться гораздо быстрее. Все это позволило опережать конкурентов и выходить в профит.
Заключение
Если у вас растущий бизнес или вы просто торгуете широко распространенными товарами, с парсингом вам придется столкнуться рано или поздно. Ничего противозаконного в нем нет, особенно при получении информации с интернет-магазинов. Здесь вы не нарушите закон о персональных данных или чьи-то авторские права
Парсинг. Что это и где используется
Парсинг (Parsing) – это принятое в информатике определение синтаксического анализа. Для этого создается математическая модель сравнения лексем с формальной грамматикой, описанная одним из языков программирования. Например, PHP, Perl, Ruby, Python.
Когда человек читает, то, с точки зрения науки филологии, он совершает синтаксический анализ, сравнивая увиденные на бумаге слова (лексемы) с теми, что есть в его словарном запасе (формальной грамматикой).
Программа (скрипт), дающая возможность компьютеру «читать» – сравнивать предложенные слова с имеющимися во Всемирной сети, называется парсером. Сфера применения таких программ очень широка, но все они работают практически по одному алгоритму.
Как работает парсинг, что это такое? Алгоритм работы парсера
Независимо от того на каком формальном языке программирования написан парсер, алгоритм его действия остается одинаковым:
В интернете часто встречаются выражения, из которых следует, будто парсер (поисковый робот, бот) путешествует по Всемирной сети. Но зачастую эта программа никогда не покидает компьютера, на котором она инсталлирована.
Этим парсер коренным образом отличается от компьютерного вируса – автономной программы, способной к размножению, хотя по сути своей работы он похож на трояна. Ведь он получает данные, иногда конфиденциального характера, не спрашивая желания их владельца.
Зачем нужен парсинг?
Сбор информации в интернете – трудоемкая, рутинная, отнимающая много времени работа. Парсеры, способные в течение суток перебрать большую часть веб-ресурсов в поисках нужной информации, автоматизируют ее.
Наиболее активно «парсят» всемирную сеть роботы поисковых систем. Но информация собирается парсерами и в частных интересах. На ее основе, например, можно написать диссертацию. Парсинг используют программы автоматической проверки уникальности текстовой информации, быстро сравнивая содержимое сотен веб-страниц с предложенным текстом.
Без программ парсинга владельцам интернет-магазинов, которым требуются сотни однотипных описаний товаров, технических характеристик и другого контента, не являющегося интеллектуальной собственностью, было бы трудно вручную заполнять характеристики товаров.
Возможностью «спарсить» чужой контент для наполнения своего сайта пользуются многие веб-мастера и администраторы сайтов. Это оправдано, если требуется часто изменять контент для представления текущих новостей или другой, быстро меняющейся информации.
Парсинг – «палочка-выручалочка» для организаторов спам-рассылок по электронной почте или каналам мобильной связи. Для этого им надо запустить «бота» путешествовать по социальным сетям и собирать «телефоны, адреса, явки».
Ну и хозяева некоторых, особенно недавно организованных веб-ресурсов, любят наполнить свой сайт чужим контентом. Правда, они рискуют, поскольку поисковые системы быстро находят и банят любителей копипаста.
Основа работы парсера
Конечно же, парсеры не читают текста, они всего лишь сравнивают предложенный набор слов с тем, что обнаружили в интернете и действуют по заданной программе. То, как поисковый робот должен поступить с найденным контентом, написано в командной строке, содержащей набор букв, слов, выражений и знаков программного синтаксиса. Такая командная строка называется «регулярное выражение». Русские программисты используют жаргонные слова «маска» и «шаблон».
Чтобы парсер понимал регулярные выражения, он должен быть написан на языке, поддерживающем их в работе со строками. Такая возможность есть в РНР, Perl. Регулярные выражения описываются синтаксисом Unix, который хотя и считается устаревшим, но широко применяется благодаря свойству обратной совместимости.
Синтаксис Unix позволяет регулировать активность парсинга, делая его «ленивым», «жадным» и даже «сверхжадным». От этого параметра зависит длина строки, которую парсер копирует с веб-ресурса. Сверхжадный парсинг получает весь контент страницы, её HTML-код и внешнюю таблицу CSS.
Парсеры и PHP
Этот серверный язык удобен для создания парсеров:
Этические и технические сложности парсинга
Вопрос о том, является ли парсинг воровством контента, активно обсуждается во Всемирной сети. Большинство оппонентов считают, что заимствование части контента, не являющегося интеллектуальной собственностью, например, технических описаний, допустимо. Ссылка на первоисточник контента рассматривается как способ частичной легитимации. В то же время, наглое копирование, включая грамматические ошибки, осуждается интернет-сообществом, а поисковыми системами рассматривается как повод для блокировки ресурса.
Кроме этических проблем парсер способен создать и технические. Он автомат, робот, но его вход на сайт фиксируется, а входящий и исходящий трафики учитываются. Количество подключений к веб-ресурсу в секунду устанавливает создатель программы. Делать этот параметр очень большим нельзя, поскольку сервер может не переварить потока входящего трафика. При частоте 200–250 подключений в секунду работа парсера рассматривается как аналогичная DOS-атаке. Интернет-ресурс, к которому проявлено такое внимание, блокируется до выяснения обстоятельств.
Парсер можно написать самому или заказать на бирже фриланса, если вам требуются конкретные условия для поиска и чтения информации. Или купить эту программу в готовом виде с усредненным функционалом на специализированном веб-ресурсе.
iPipe – надёжный хостинг-провайдер с опытом работы более 15 лет.
Дорогие клиенты виртуального хостинга, мы рады сообщить о долгожданном нововведении → В панели управления Megatool доступен к выпуску бесплатный SSL…