Видение отказоустойчивой, надежной, масштабируемой сети передачи данных
Воодушевленный философией сетевых технологий, технологиями передачи данных, да и вообще всем тем, что объясняет, как все работает, решаюсь написать ряд статей о том, что является эталоном сетевых решений, качественной реализацией или настройкой, или что подобным не является, но в современности присутствует, и жутко раздражает.
Что же в этот раз.
В видении построения сетей компании Cisco существует понятие трехуровневая модель.
Трехуровневая модель сети представляет собой некую иерархическую структуру передачи данных не в терминах протоколов или моделей (типа модели OSI или TCP/IP), а в терминах функционирования абстрактных элементов сети.
Из названия очевидно, что все элементы сети делятся на три так называемых уровня. Это деление позволяет строить отказоустойчивые, надежные, масштабируемые сети передачи данных. Роль уровней скорее логическая, и не обязательно существует физическая привязка к конкретному оборудованию. 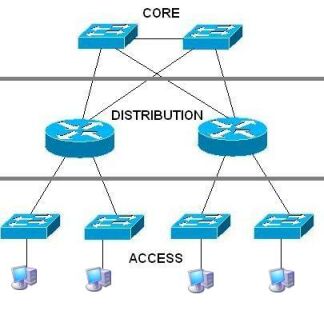
Базовый уровень (Core Layer)
Является ядром сети. Единственное, что он должен выполнять — молниеносно перенаправлять пакеты из одного сегмента в другой. Базовый уровень отвечает только за скоростную коммутацию трафика, он не отвечает за маршрутизацию. Исходя из этого, базовый уровень нужно обеспечить высокой степенью отказоустойчивости и надежности. Обычно дублируют устройства, работающие на базовом уровне. Рассмотрим, к примеру Cisco WS-C6503-E.
Уровень распределения (Distribution Layer)
Представляет собой «прослойку» между уровнем доступа и уровнем ядра (базовым уровнем). Именно на этом уровне осуществляется контроль над сетевой передачей данных. Также можно создавать широковещательные домены, создавать VLAN’ы, если необходимо, а так же внедрять различные политики (безопасности и управления). На уровне распределения может осуществляться правило обращения к уровню ядра. Приведу некоторые особенности и рекомендации при проектировании уровня распределения, которые выделяют ведущие производители сетевого оборудования.
Уровень доступа (Access Layer)
Важно!
Необходимо при построении сети придерживаться правила, чтобы функции одного уровня не выполнял другой и наоборот.
Естественно, что такая модель приемлема для сети крупного предприятия, в интересах которого функционирование ее должным образом. Немало нужно затратить сил и, времени и средств, чтобы выработать проект, внедрить и обслуживать такую сеть. Но зато это стоит того!
Обзор вариантов реализации отказоустойчивых кластеров: Stratus, VMware, VMmanager Cloud

Есть разновидности бизнеса, где перерывы в предоставлении сервиса недопустимы. Например, если у сотового оператора из-за поломки сервера остановится биллинговая система, абоненты останутся без связи. От осознания возможных последствий этого события возникает резонное желание подстраховаться.
Мы расскажем какие есть способы защиты от сбоев серверов и какие архитектуры используют при внедрении VMmanager Cloud: продукта, который предназначен для создания кластера высокой доступности.
Предисловие
В области защиты от сбоев на кластерах терминология в Интернете различается от сайта к сайту. Для того чтобы избежать путаницы, мы обозначим термины и определения, которые будут использоваться в этой статье.
На первый взгляд самый привлекательный вариант для бизнеса тот, когда в случае сбоя обслуживание пользователей не прерывается, то есть кластер непрерывной доступности. Без КНД никак не обойтись как минимум в задачах уже упомянутого биллинга абонентов и при автоматизации непрерывных производственных процессов. Однако наряду с положительными чертами такого подхода есть и “подводные камни”. О них следующий раздел статьи.
Continuous availability / непрерывная доступность
Бесперебойное обслуживание клиента возможно только в случае наличия в любой момент времени точной копии сервера (физического или виртуального), на котором запущен сервис. Если создавать копию уже после отказа оборудования, то на это потребуется время, а значит, будет перебой в предоставлении услуги. Кроме этого, после поломки невозможно будет получить содержимое оперативной памяти с проблемной машины, а значит находившаяся там информация будет потеряна.
Для реализации CA существует два способа: аппаратный и программный. Расскажем о каждом из них чуть подробнее.
Программный способ.
На момент написания статьи самый популярный инструмент для развёртывания кластера непрерывной доступности — vSphere от VMware. Технология обеспечения Continuous Availability в этом продукте имеет название “Fault Tolerance”.
В отличие от аппаратного способа данный вариант имеет ограничения в использовании. Перечислим основные:
Мы не стали расписывать конкретные конфигурации нод: состав комплектующих в серверах всегда зависит от задач кластера. Сетевое оборудование описывать также смысла не имеет: во всех случаях набор будет одинаковым. Поэтому в данной статье мы решили считать только то, что точно будет различаться: стоимость лицензий.
Стоит упомянуть и о тех продуктах, разработка которых остановилась.
Есть Remus на базе Xen, бесплатное решение с открытым исходным кодом. Проект использует технологию микроснэпшотов. К сожалению, документация давно не обновлялась; например, установка описана для Ubuntu 12.10, поддержка которой прекращена в 2014 году. И как ни странно, даже Гугл не нашёл ни одной компании, применившей Remus в своей деятельности.
Предпринимались попытки доработки QEMU с целью добавить возможность создания continuous availability кластера. На момент написания статьи существует два таких проекта.
Первый — Kemari, продукт с открытым исходным кодом, которым руководит Yoshiaki Tamura. Предполагается использовать механизмы живой миграции QEMU. Однако тот факт, что последний коммит был сделан в феврале 2011 года говорит о том, что скорее всего разработка зашла в тупик и не возобновится.
Второй — Micro Checkpointing, основанный Michael Hines, тоже open source. К сожалению, уже год в репозитории нет никакой активности. Похоже, что ситуация сложилась аналогично проекту Kemari.
Таким образом, реализации continuous availability на базе виртуализации KVM в данный момент нет.
Итак, практика показывает, что несмотря на преимущества систем непрерывной доступности, есть немало трудностей при внедрении и эксплуатации таких решений. Однако существуют ситуации, когда отказоустойчивость требуется, но нет жёстких требований к непрерывности сервиса. В таких случаях можно применить кластеры высокой доступности, КВД.
High availability / высокая доступность
В контексте КВД отказоустойчивость обеспечивается за счёт автоматического определения отказа оборудования и последующего запуска сервиса на исправном узле кластера.
В КВД не выполняется синхронизация запущенных на нодах процессов и не всегда выполняется синхронизация локальных дисков машин. Стало быть, использующиеся узлами носители должны быть на отдельном независимом хранилище, например, на сетевом хранилище данных. Причина очевидна: в случае отказа ноды пропадёт связь с ней, а значит, не будет возможности получить доступ к информации на её накопителе. Естественно, что СХД тоже должно быть отказоустойчивым, иначе КВД не получится по определению.
Таким образом, кластер высокой доступности делится на два подкластера:
VMmanager Cloud
Наше решение VMmanager Cloud использует виртуализацию QEMU-KVM. Мы сделали выбор в пользу этой технологии, поскольку она активно разрабатывается и поддерживается, а также позволяет установить любую операционную систему на виртуальную машину. В качестве инструмента для выявления отказов в кластере используется Corosync. Если выходит из строя один из серверов, VMmanager поочерёдно распределяет работавшие на нём виртуальные машины по оставшимся нодам.
В упрощённой форме алгоритм такой:
Практика показывает, что лучше выделить одну или несколько нод под аварийные ситуации и не развёртывать на них ВМ в период штатной работы. Такой подход исключает ситуацию, когда на “живых” нодах в кластере не хватает ресурсов, чтобы разместить все виртуальные машины с “умершей”. В случае с одним запасным сервером схема резервирования носит название “N+1”.
Рассмотрим по каким схемам пользователи VMmanager Cloud реализовывали кластеры высокой доступности.
FirstByte
Компания FirstByte начала предоставлять облачный хостинг в феврале 2016 года. Изначально кластер работал под управлением OpenStack. Однако отсутствие доступных специалистов по этой системе (как по наличию так и по цене) побудило к поиску другого решения. К новому инструменту для управления КВД предъявлялись следующие требования:
Отличительные черты кластера:
Данная конфигурация подходит для хостинга сайтов с высокой посещаемостью, для размещения игровых серверов и баз данных с нагрузкой от средней до высокой.
FirstVDS
Компания FirstVDS предоставляет услуги отказоустойчивого хостинга, запуск продукта состоялся в сентябре 2015 года.
К использованию VMmanager Cloud компания пришла из следующих соображений:
В случае общего отказа Infiniband-сети связь между хранилищем дисков ВМ и вычислительными серверами выполняется через Ethernet-сеть, которая развёрнута на оборудовании Juniper. “Подхват” происходит автоматически.
Благодаря высокой скорости взаимодействия с хранилищем такой кластер подходит для размещения сайтов со сверхвысокой посещаемостью, видеохостинга с потоковым воспроизведением контента, а также для выполнения операций с большими объёмами данных.
Эпилог
Подведём итог статьи. Если каждая секунда простоя сервиса приносит значительные убытки — не обойтись без кластера непрерывной доступности.
Однако если обстоятельства позволяют подождать 5 минут пока виртуальные машины разворачиваются на резервной ноде, можно взглянуть в сторону КВД. Это даст экономию в стоимости лицензий и оборудования.
Кроме этого не можем не напомнить, что единственное средство повышения отказоустойчивости — избыточность. Обеспечив резервирование серверов, не забудьте зарезервировать линии и оборудование передачи данных, каналы доступа в Интернет, электропитание. Всё что только можно зарезервировать — резервируйте. Такие меры исключают единую точку отказа, тонкое место, из-за неисправности в котором прекращает работать вся система. Приняв все вышеописанные меры, вы получите отказоустойчивый кластер, который действительно трудно вывести из строя.
Если вы решили, что для ваших задач больше подходит схема высокой доступности и выбрали VMmanager Cloud как инструмент для её реализации, к вашим услугам инструкция по установке и документация, которая поможет подробно ознакомиться с системой. Желаем вам бесперебойной работы!
P. S. Если у вас в организации есть аппаратные CA-серверы — напишите, пожалуйста, в комментариях кто вы и для чего вы их используете. Нам действительно интересно услышать для каких проектов использование такого оборудование экономически целесообразно 🙂
По Стопам CCNA 13. Сетевая Архитектура, базовые сетевые характеристики.
Сети должны поддерживать широкий диапазон приложений и сервисов, через множество различных сетевых сред и устройств, которые составляют физическую инфраструктуру.
Пока сети эволюционировали, были выявлены четыре базовых характеристики сети, которые сетевой специалист должен держать в уме для удовлетворения ожиданий пользователей.
1) Отказоустойчивость.
2) Масштабируемость.
3) Качество обслуживания или качество предоставления сервисов.
4) Безопасность.

Для каждой, встреченной вами в жизни, сети данные параметры будут различны. Это вызвано как разницей в бюджетах на построение сети, так и разницей в уровнях специалистов принимающих участие в построении и обслуживании сети.
Теперь поподробнее о каждой характеристике.
Отказоустойчивость.
Ожидается, и в наше время особенно, что интернет всегда доступен. Миллионы пользователей по всему миру полагаются на его наличие. Данная потребность людей и выдвигает требование к построению отказоустойчивой системы.
Отказоустойчивая сеть – это сеть, построенная и функционирующая так, что ограничивает распространение отказа таким образом, что бы при отказе было затронуто наименьшее количество устройств. Такая архитектура сети позволяет не только ограничивать распространение возникших сбоев, но и быстрее устранять их.

Отказоустойчивые сети в первую очередь зависят от множества путей для связи между источником сообщения и его пунктом назначения. Если один из путей связи прервался, сообщение будет доставлено, используя альтернативные пути связи.

Наличие множества путей от пункта A до пункта B это обеспечение избыточности.
Одним из способов обеспечения функциональности избыточности является реализация сети на основе коммутации пакетов.
Коммутация пакетов делит общий поток информационных данных на маленькие пакеты, которые направляются через общедоступную сеть. Единое сообщение, такое как E-Mail сообщение или видеопоток делится на множество маленьких блоков, которые называются пакетами. Каждый пакет имеет в себе необходимую адресную информацию об источнике и назначении передачи.
Маршрутизаторы в сети коммутации пакетов пересылают пакеты в зависимости от текущего состояния сети. Это означает что все пакеты, из которых состоит изначальное сообщение, могут получить различные пути к пункту назначения. На рисунке показано, что пользователь не заметил проблем с доставкой сообщения, потому что маршрутизатор динамически изменил маршрут, когда на основном канале связи произошел собой.

Такое невозможно для сетей с коммутацией каналов, стандартно используемых для голосовых коммутаций.
При коммутации каналов сеть изначально устанавливает и резервирует на время взаимодействия один непрерывный канал связи между источником и назначением, и данный канал остается неизменным и зарезервированным пока конечные пользователи продолжают взаимодействовать. Если по пути этого взаимодействия произойдет сбой, то связь прервется, и пользователи будут вынуждены инициировать новое соединение
Масштабируемость.
Масштабируемость сети означает, что сеть может легко увеличиваться и расширяться для добавления новых пользователей и сервисов без существенного влияния на работу существующих пользователей и сервисов ими используемых.

Рисунок демонстрирует, как легко новая сеть может быть присоединена к существующей сети. Это возможно благодаря тому, что проектировщики придерживаются общепринятых стандартов и протоколов. Это позволяет программным и аппаратным производителям сосредотачиваться на улучшении продуктов и сервисов, не беспокоясь о проектировании и создании новых наборов правил для работы с сетью.
Качество обслуживания.
Quality of Service (QoS) или Качество обслуживания и сервисов, это все возрастающее, с течением времени, требование к сетям.
Новые приложения с каждым днем появляются и становятся доступны пользователям через глобальную сеть. Например, голосовая и видео связь, которые предполагают большие требования к качеству обслуживания в общедоступных сетях. Скорость доставки данных для этих типов сервиса требует в разы более быстрого времени отклика и большего объема передачи данных за единицу времени.

Так как в конвергентной сети данные, видео и аудио контент идут по одной и той же инфраструктуре, только специальные механизмы QoS позволяют обрабатывать пакеты в той последовательности, которая позволяет обеспечивать заданное качество для приоритетных типов данных, используемых приложениями конечных пользователей.
Потребность обработки трафика по приоритетам появляется, когда возникает перегрузка, то есть запросов на передачу пакетов приходит больше чем может обработать сетевая инфраструктура в текущий момент.
Пропускная способность сети измеряется в количестве бит которые могут быть переданы в течение одной секунды
Таким образом, получается единица измерения «Бит в секунду» и обозначается «bps»

На рисунке показано, что один из пользователей запросил Web страницу, а другой одновременно начал звонок. Согласно настройкам политики QoS роутер направил данные от первого пользователя через общий канал связи с интернетом, а все пакеты для голосовой связи были перенаправлены через альтернативный канал связи который на тот момент был пустым, таким незатейливым способом предоставив голосовой связи более высокий приоритет.
Безопасность.
Сетевая инфраструктура, сервисы и данные, содержащиеся в подключенных к сети устройствах это критически важный персональный и корпоративный капитал.
Существуют два типа вопросов сетевой безопасности, которые должны рассматриваться
1) Безопасность сетевой инфраструктуры.
2) Информационная безопасность.
Безопасность сетевой инфраструктуры включает физическую безопасность устройств, которые предоставляют сетевое соединение и так же предотвращение неавторизованного доступа к программному обеспечению, которое работает на данных устройствах.

Примером безопасности сетевой инфраструктуры могут служить антивандальные ящики, которые относительно надежно обеспечивают физическую безопасность промежуточных сетевых устройств.

Написав мне, вы всегда сможете заказать подобные ящики по хорошим ценам.
Примером же предотвращения неавторизованного доступа может служить настройка программного обеспечения сетевого устройства таким образом, что для просмотра и изменения настроек необходимо ввести имя пользователя, пароль и производить попытку подключения к данному устройству с четко заданных диапазонов адресов сети.

Понятие информационная безопасность относится к защите информации содержащейся в пакетах, передаваемых через сеть и информации хранимой на подключенных к сети устройствах.
В требованиях к сетевой информационной безопасности выделяют три основных компонента
1) Конфиденциальность – означает, что только известные планируемые и авторизованные получатели могут получить доступ и прочитать данные содержащиеся в сообщении
Два графа, А и В, ведут переписку и хотят объединиться против графа С, предполагая что граф C не в курсе их переписки и замыслов. Если Граф С имеет возможность получения информации из данной переписки, это нарушение Конфиденциальности информации.
2) Целостность данных – что означает гарантию того, что информация, отправленная из источника, дойдет до адресата в неизменном виде.
Два графа, А и В, ведут переписку и хотят объединиться против графа С. Граф С не может получить доступ к информации в письмах, но у него есть возможность подмены или изменения сообщений по пути. Добавляя в оригинальные сообщения дополнительную информацию граф, даже не имея возможности прочтения оригинального содержимого, может добиться принятия необходимого вектора развития данного информационного взаимодействия.
3) Доступность – означает что данные и информация своевременно и регламентировано, доступны авторизованным пользователям.
Опять приведу пример.
Если переписку между графами А и В, граф С прервет на постоянной основе, то информационное взаимодействие будет нарушено, то есть будет прервана своевременная доступность к информации.
Отказоустойчивые системы: зачем нужны и как построить
Методы построения отказоустойчивых систем
На сегодняшний день не существует системы, гарантирующей 100% отказоустойчивость. Другими словами, не существует системы, которая гарантирует 100% вероятность безотказной работы на протяжении задаваемого промежутка времени (100% доступность).
Примеры систем с различными значениями вероятностей безотказной работы
| Вероятность безотказной работы, % | Время простоя/год | Пример |
| 99 | 5000 минут | web страница общего характера |
| 99,9 | 500 минут | Amazon.com |
| 99,99 | 50 минут | Почтовый сервер крупного предприятия |
| 99,999 | 5 минут | Телефонная система |
| 99,9999 | 30 секунд | Высокоскоростной телефонный коммутатор |
Источник: G. Candea, «Principles of Dependable Computer Systems». Stanford University, 2003
Способы построения отказоустойчивых систем


Аппаратная избыточность (Hardware Redundancy, более известна как резервирование). Существуют методы постоянного резервирования (синтез избыточных устройств, нечувствительных к определенному количеству ошибок) и методы резервирования замещением (использование системы контроля, которая может действовать непрерывно или периодически, в этом случае говорят, о так называемом функциональном диагностировании). Исключая даже кратковременный простой, постоянное резервирование имеет относительное преимущество по сравнению со второй группой методов, системы при отказах.
Программная избыточность (Software Redundancy) используется для контроля и обеспечения достоверности наиболее важных решений по управлению и обработке информации. Она заключается в сопоставлении результатов обработки одинаковых исходных данных разными программами и исключении искажения результатов, обусловленных различными аномалиями.
Информационная избыточность (Information Redundancy) наиболее присуща телекоммуникационным системам, в которых информация передается многократно. Информационная избыточность заключается в дублировании накопленных исходных и промежуточных данных.
Временная избыточность (Time Redundancy) заключается в использовании некоторой части производительности компьютера для контроля за исполнением программ и восстановления (рестарта) вычислительного процесса (запас времени для повторного выполнения операции (например, двойного или тройного просчёта на вычислительной машине).
Наглядным примером введения многоуровневой избыточности в систему, для достижения отказоустойчивости, может послужить система контроля и управления авиалайнера Airbus 320 (fly-by-wire flight control system). В процессе функционирования системы управления, и обеспечения взаимосвязей между различными компонентами и контроля за последними, в Airbus 320 задействовано 5 различных независимых компьютеров. Система управления авиалайнером строилась из расчета, что обнаружение ошибок должно осуществляться как в аппаратной, так и в программной части системы. По этой причине, в процессе управления полетом, дополнительно задействовано два типа программного обеспечения, от двух независимых разработчиков.
Достаточно распространены методы, когда с целью повышения надежности, система снабжается схемой внутреннего контроля (СВК/тестер), предназначение которой заключается в инициализации «сигнала отказа» при наличии неисправностей или изменения функциональности, и как следствие, несоответствие выходных сигналов. В этом случае, сигнал о ошибке используется для отключения неисправного устройства от объекта управления. Также этот сигнал может быть параллельно использован для активизации команды подключения резервного или дублирующего устройства. Но важно при этом не забыть про проверку исправности схемы самого СВК.
Сделаем вывод. Отличительными преимуществами отказоустойчивых систем являются: их высокая безотказность, бесперебойность работы системы при наличии отказов и более продолжительный жизненный цикл эксплуатации. Отказоустойчивые системы помимо преимуществ имеют и ряд специфических характеристик, а именно: сложность дизайна и высокая стоимость развертывания, повышение энергопотребления, усложнение системы.